2015-06-14
2015-06-14 446
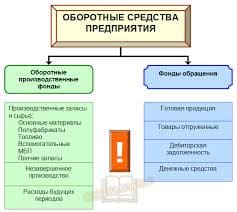
446Ранее были рассмотрены различные отношения между выборками: количественное преобладание какого-то признака, представленного в одной из выборок, тесность связи между выборками. Но есть еще одно важное отношение между ними: количественная разница распределений, благодаря наличию которой при сопоставлении выборок открывается возможность прийти к содержательным выводам. Это отношение обнаруживается при сопоставлении распределений численностей.
Допустим, что сравниваются две выборки, составленные соответственно из выпускников двух школ. Часть выпускников каждой школы сдавала экзамены в вузы. Из первой школы сдавали экзамены 100 человек, из них 82 успешно сдали экзамены, не сдали – 18. Таково распределение численностей в первой выборке. Из второй школы сдавали экзамены в вузы 87 человек, выдержали 44 человека, не сдали – 43. Таково распределение численностей во второй выборке.
Достаточно ли этих данных, чтобы утверждать, что подготовленность к вузовским экзаменам выпускников этих школ неодинакова?
На первый взгляд, разница налицо: лучше подготовлены выпускники первой школы. Однако при таком раскладе численностей возможно влияние случайности. Поэтому встает вопрос: можно ли, считаясь с представленными распределениями, прийти к статистически обоснованному выводу о мере подготовленности к экзаменам в вузы выпускников той и другой выборки?
Метод, с помощью которого подвергаются статистическому анализу описанные распределения численностей, получил название хи-квадрат, его обозначают греческой буквой χ2 с показателем степени. Он былразработан математиком К. Пирсоном. Метод χ2 весьма универсален применим во многих исследованиях, он пригоден для статистического анализа распределения численностей разнообразных количественных материалов, относящихся ко всем статистическим шкалам, в том числе и к шкале наименований.
Техника вычисления хи-квадрата довольно проста. Рассмотрим пример со сдачей экзаменов в вузы выпускниками 1-й и 2-й школ. В условии сказано, что всего намерены были сдавать экзамены 187 человек, из этого числа на долю 1-й школы приходится 53,5% (100 человек), а на долю 2-й школы – 46,5% (87 человек). Предположим, что выпускники той и другой школы подготовлены одинаково, тогда и доли сдавших и несдавших будут такие же, как доли их представленности в общем числе сдающих. Всего сдало экзамены 126 выпускников. Согласно высказанному предположению, 53,5% от этого числа должны были бы прийтись на 1-ю школу – это составит 66,9 от 126 – и 46,5% на 2-ю школу, что составит 58,9 от 126. Такое же рассуждение повторяем и относительно несдавших. Их всего 61 человек. На 1-ю школу, как нам известно, должно, по предположению, прийтись 53,5% от этого числа, т.е. 33,0 от 61, а на долю 2-й школы – 46,5%, т.е. 28,1 от 61. Нуль-гипотеза, имеющая в данном раскладе тот смысл, что между выпускниками нет различия, при таком соотношении сдавших и несдавших подтвердилась бы. Однако в условиях этого исследования показано другое распределение. Количество выпускников 1 -и школы, сдавших экзамены, составляет 82, а не 66,9, как можно было бы предположить, исходя из нуль-гипотезы. Соответственно, количество выпускников 2-й школы, сдавших экзамены, составляет в действительности всего 44, а не 58,9. Точно так же, сравнивая количество несдавших (по условию с предполагаемым распределением), найдем по 1-й школе 18, а не 33, а по 2-й школе – 43, а не 28,1.
Расхождения между действительными (наблюденными) распределениями и распределениями, которые могли бы иметь место, если исходить из нуль-гипотез, налицо. Они-то и учитываются при вычислении х2. Все сказанное удобно представить в виде таблицы-графика распределения численностей (табл. 14). Количества, которые были бы получены при принятии нуль-гипотезы, заключены в скобки. В правом углу буквенное обозначение клетки.
Таблица 14