2015-09-06
2015-09-06 431
431Задачи таксономии
Содержательную постановку задачи таксономии можно прочитать в работе [121], написанной еще во II в. до нашей эры. В «Письме ученому соседу» Демокрит пишет такие слова: «Если тебе, дорогой друг, нужно разобраться в сложном нагромождении фактов или вещей, ты сначала разложи их на небольшое число куч по похожести. Картина прояснится, и ты поймешь природу этих вещей».
Некоторое время назад новосибирские социологи изучали причины массовой миграции сельского населения в города. В города и села Алтайского края были направлены экспедиции, которые находили людей, недавно переехавших из села в город, а также тех сельских жителей, которые планируют такой переезд в ближайшем будущем. Каждому из них социологи задавали около ста вопросов, записывая в анкету ответы о возрасте, образовании, семейном положении и прочих характеристиках опрашиваемого. Когда социологи вернулись из экспедиций и выложили на стол заполненные анкеты, они увидели впечатляющую картину. Перед ними была гора из семи тысяч анкет, каждая их которых содержала ответы на сто вопросов. Как подступиться к анализу этих данных? Переписывание данных в протокол «объект-свойство» делу не поможет: таблица размером 7000 строк на 100 столбцов так же не обозрима, как и эта гора анкет.
Пошли по единственно возможному пути: перенесли анкеты на машинные носители и применили к полученной таблице программы таксономии. В результате получили 7 основных таксонов, средние характеристики которых позволили дать им вполне понятную содержательную интерпретацию. Выделился, например, таксон, куда вошли люди женского пола в возрасте более 60 лет, дети которых живут в городе. Ясно, что представители этого таксона, который социологи назвали «бабушки», едут в город нянчить своих внуков. Были также понятные таксоны «демобилизованные солдаты», «невесты» и другие [86].
Группировка объектов (часто употребляют также термины автоматическая классификация, самообучение, кластеризация) по похожести их свойств упрощает решение многих практических задач анализа данных. Так, если объекты описаны свойствами, которые влияют на общую оценку их качества, то в одну группу (таксон) будут собраны объекты, обладающие приблизительно одинаковым качеством. И вместо того, чтобы хранить в памяти все объекты, достаточно сохранить описание типичного представителя каждого таксона (прецедента), перечислить номера объектов, входящих в данный таксон, и указать максимальное отклонение каждого свойства от его среднего значения для данного таксона. Этой информации обычно бывает достаточно для дальнейшего анализа изучаемого множества объектов.
Как же делается таксономия? Одно и тоже множество из то объектов можно разбить на 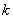 таксонов
таксонов 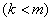 по-разному. Если бы мы записали такое исходное состояние нашего знания в виде эмпирической гипотезы
по-разному. Если бы мы записали такое исходное состояние нашего знания в виде эмпирической гипотезы 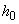 , то ее тестовый алгоритм
, то ее тестовый алгоритм 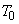 считал бы допустимой любую таксономию. Но мы знаем, что человек, делая группировку чего бы то ни было, руководствуется каким-то критерием (обозначим его
считал бы допустимой любую таксономию. Но мы знаем, что человек, делая группировку чего бы то ни было, руководствуется каким-то критерием (обозначим его 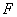 ), который позволяет отличать хорошие группировки от плохих и выбирать наилучший вариант таксономии. Теперь наше знание позволяет сформулировать более сильную гипотезу, тестовый алгоритм которой считает допустимой только такую таксономию, которая удовлетворяет критерию .
), который позволяет отличать хорошие группировки от плохих и выбирать наилучший вариант таксономии. Теперь наше знание позволяет сформулировать более сильную гипотезу, тестовый алгоритм которой считает допустимой только такую таксономию, которая удовлетворяет критерию .