 2015-09-06
2015-09-06 651
651Помимо описанных в этой главе существует большое количество других алгоритмов таксономии (см., например, [12,49,95, 166]). Естественно, возникает потребность в их сравнении и выборе алгоритма, в некотором смысле лучшего, чем другие. Алгоритмы можно сравнивать по требуемым машинным ресурсам (памяти и времени), по применимости к трудным случаям (большие массивы данных, разнотипные признаки, наличие в данных помех и пробелов и т. д.).
Однако главное, что интересует пользователя — качество получаемых решений. Чтобы сформулировать критерий качества, по которому можно было бы сравнивать алгоритмы таксономии, напомним, что таксономия обычно делается не только для компактной перекодировки множества то объектов в 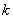 таксонов. Эти таксоны или их типичные представители (прецеденты) используются в дальнейшем как для краткого описания имеющихся объектов, так и (что более важно) для распознавания новых объектов генеральной совокупности. Каждый новый объект относится к тому таксону (образу), присоединение к которому наилучшим образом удовлетворяет критерию качества таксономии.
таксонов. Эти таксоны или их типичные представители (прецеденты) используются в дальнейшем как для краткого описания имеющихся объектов, так и (что более важно) для распознавания новых объектов генеральной совокупности. Каждый новый объект относится к тому таксону (образу), присоединение к которому наилучшим образом удовлетворяет критерию качества таксономии.
Пусть множество то объектов представляет собой некоторую выборку из генеральной совокупности, состоящей из 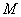 объектов
объектов 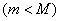 , и на множестве то тем или иным алгоритмом
, и на множестве то тем или иным алгоритмом 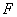 сделана таксономия на таксонов. Если теперь предъявлять по очереди все остальные
сделана таксономия на таксонов. Если теперь предъявлять по очереди все остальные 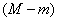 объектов и присоединять их к соответствующим таксонам, то в итоге будет получен вариант
объектов и присоединять их к соответствующим таксонам, то в итоге будет получен вариант 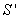 таксономии генеральной совокупности . Если бы мы тем же алгоритмом сделали таксономию сразу всей совокупности объектов, то получили бы вариант таксономии
таксономии генеральной совокупности . Если бы мы тем же алгоритмом сделали таксономию сразу всей совокупности объектов, то получили бы вариант таксономии 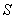 . Будем называть таксономии и базовой и выборочной соответственно.
. Будем называть таксономии и базовой и выборочной соответственно.
Возникает вопрос: будет ли таксономия совпадать с таксономией ? Если да, то алгоритм удачно угадал структуру множества по случайной выборке то. Эта способность по малой выборке правильно угадывать структурные закономерности генеральной совокупности и есть, по-видимому, основная характеристика 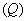 качества алгоритмов таксономии. Сравнивать различные алгоритмы таксономии по этому качеству можно с помощью программного испытательного полигона «Таксон» [84]. Прежде, чем описать его работу, введем некоторые обозначения.
качества алгоритмов таксономии. Сравнивать различные алгоритмы таксономии по этому качеству можно с помощью программного испытательного полигона «Таксон» [84]. Прежде, чем описать его работу, введем некоторые обозначения.
Если объекты 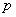 и
и 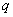 принадлежат разным таксонам, то считаем, что таксономическое расстояние
принадлежат разным таксонам, то считаем, что таксономическое расстояние 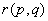 между ними равно единице, а если они из одного таксона, то
между ними равно единице, а если они из одного таксона, то 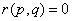 . Представим себе квадратную бинарную матрицу размером
. Представим себе квадратную бинарную матрицу размером 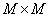 , столбцы и строки которой соответствуют объектам генеральной совокупности, а на пересечении -й строки с -м столбцом стоит значение . Все диагональные элементы такой матрицы равны нулю, так как
, столбцы и строки которой соответствуют объектам генеральной совокупности, а на пересечении -й строки с -м столбцом стоит значение . Все диагональные элементы такой матрицы равны нулю, так как 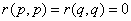 , и матрица симметрична, так как
, и матрица симметрична, так как 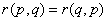 . Тогда различие
. Тогда различие 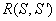 между двумя таксономиями и можно определить, наложив одну на другую матрицы, соответствующие этим таксономиям, и суммируя число элементов с несовпадающими значениями . Если полученную сумму разделить на максимально возможное число несовпадений
между двумя таксономиями и можно определить, наложив одну на другую матрицы, соответствующие этим таксономиям, и суммируя число элементов с несовпадающими значениями . Если полученную сумму разделить на максимально возможное число несовпадений 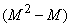 , то получим хеммингово расстояние между матрицами, нормированное в диапазоне от нуля до единицы:
, то получим хеммингово расстояние между матрицами, нормированное в диапазоне от нуля до единицы:
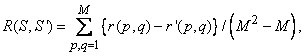
где и 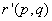 — таксономические расстояния для объектов из таксономий и соответственно. Чем меньше величина различия , тем лучше испытуемый алгоритм таксономии угадал структуру генеральной совокупности.
— таксономические расстояния для объектов из таксономий и соответственно. Чем меньше величина различия , тем лучше испытуемый алгоритм таксономии угадал структуру генеральной совокупности.
В полигоне «Таксон» можно менять объем генеральной совокупности , объем случайной выборки 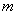 и размерность пространства признаков
и размерность пространства признаков 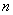 . Множество представляет собой либо данные некоторой реальной задачи, либо данные, порождаемые генератором с заданным законом распределения. В последнем случае можно задавать число таксонов и расстояния между таксонами
. Множество представляет собой либо данные некоторой реальной задачи, либо данные, порождаемые генератором с заданным законом распределения. В последнем случае можно задавать число таксонов и расстояния между таксонами 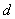 . Испытуемому алгоритму
. Испытуемому алгоритму 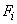 количество таксонов либо задается, либо он должен сам выбрать наилучшее число таксонов с точки зрения своего критерия качества . В процессе испытания объем выборки меняется от малых долей до полного объема . При каждом значении выборка формируется случайным образом, и эксперимент с объектами повторяется
количество таксонов либо задается, либо он должен сам выбрать наилучшее число таксонов с точки зрения своего критерия качества . В процессе испытания объем выборки меняется от малых долей до полного объема . При каждом значении выборка формируется случайным образом, и эксперимент с объектами повторяется 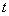 раз
раз  . Получаемые при этом величины усредняются. По итогам экспериментов фиксируется доля , при которой базовая и выборочная таксономии перестают отличаться друг от друга. Тот алгоритм считается лучшим, который достигает этого эффекта при минимальном значении .
. Получаемые при этом величины усредняются. По итогам экспериментов фиксируется доля , при которой базовая и выборочная таксономии перестают отличаться друг от друга. Тот алгоритм считается лучшим, который достигает этого эффекта при минимальном значении .
В ходе испытания алгоритмов таксономии выяснилось, что их способность угадывать структуру генеральной совокупности практически не зависит от размерности признакового пространства. Можно сказать, что по этому свойству машина существенно превосходит человека, который успешно решает задачи таксономии лишь тогда, когда есть возможность непосредственно видеть разделяемое множество, т. е. не более чем в трехмерном пространстве. При большем числе признаков он переходит к примитивному способу деления по каждому признаку в отдельности (например, от и до по возрасту и образованию), разрезая многомерное пространство на гиперпараллелепипеды.
Из рассмотренных в данной книге алгоритмов таксономии при сравнении на полигоне лучшим, как и ожидалось, оказался алгоритм KRAB (см. главу 10), на втором месте был SKAT и на третьем FOREL. Однако следует учитывать, что алгоритм KRAB гораздо более трудоемкий, чем его конкуренты. Кроме того, он выдает результат в виде таксонов произвольной формы и сложности, что требует больших затрат памяти на их описание и затрудняет понимание результата человеком. В итоге приходится сложные таксоны описывать набором более простых форм, например набором гиперсфер или гиперкубов. Алгоритм же FOREL дает быстрые и простые решения. Так что в практическом использовании всем этим алгоритмам находится свое место.








