 2015-10-13
2015-10-13 1964
1964Динамическое программирование (иначе «динамическое планирование») есть особый метод оптимизации решений, специально приспособленный к так называемым «многошаговым» (или «многоэтапным») операциям.
Представим себе некоторую операцию О, распадающуюся на ряд последовательных «шагов» или «этапов»,— например, деятельность отрасли промышленности в течение ряда хозяйственных лет; или же преодоление группой самолетов нескольких полос противовоздушной обороны; или же последовательность тестов, применяемых при контроле аппаратуры. Некоторые операции (подобно вышеприведенным) расчленяются на шаги естественно; в некоторых членение приходится вводить искусственно — скажем, процесс наведения ракеты на цель можно условно разбить на этапы, каждый из которых занимает какое-то время Δt.
 Итак, рассмотрим операцию О, состоящую из т шагов (этапов). Пусть эффективность операции характеризуется каким-то показателем W, который мы для краткости будем в этой главе называть «выигрышем». Предположим, что выигрыш W за всю операцию складывается из выигрышей на отдельных шагах:
Итак, рассмотрим операцию О, состоящую из т шагов (этапов). Пусть эффективность операции характеризуется каким-то показателем W, который мы для краткости будем в этой главе называть «выигрышем». Предположим, что выигрыш W за всю операцию складывается из выигрышей на отдельных шагах:
(12.1)
где wi — выигрыш на i-м шаге.
Если W обладает таким свойством, то его называют «аддитивным х критерием».
Операция О, о которой идет речь, представляет собой управляемый процесс, т. е. мы можем выбирать какие-то параметры, влияющие на его ход и исход, причем на каждом шаге выбирается какое-то решение, от которого зависит выигрыш на данном шаге и выигрыш за операцию в целом. Будем называть это решение «шаговым управлением». Совокупность всех шаговых управлений представляет собой управление операцией в целом. Обозначим его буквой х, а шаговые управления — буквами х1, x2,..., хт:
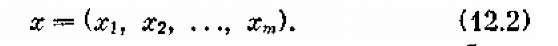
(12.2)
Следует иметь в виду, что х1, x2,..., хт в общем случае — не числа, а, может быть, векторы, функции и т. д.
Требуется найти такое управление х, при котором выигрыш W обращается в максимум:
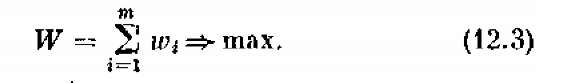 (12.3)
(12.3)
То управление х*, при котором этот максимум достигается, будем называть оптимальным управлением. Оно состоит из совокупности оптимальных шаговых управлений:
x* = (x*1, x*2,…, x*m) (12.4)
Тот максимальный выигрыш, который достигается при этом управлении, мы будем обозначать W*:

(12.5)
Формула (12.5) читается так: величина W* есть максимум из всех W(x) при разных управлениях х (максимум берется по всем управлениям х, возможным в данных условиях). Иногда это последнее оговаривается в формуле и пишут:
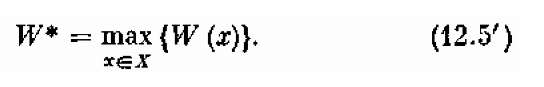
Рассмотрим несколько примеров многошаговых операций и для каждого из них поясним, что понимается под «управлением» и каков «выигрыш» (показатель эффективности) W.
1. Планируется деятельность группы промышленных предприятий II1, П2,..., Пк на период т хозяйственных лет m-летку). В начале периода на развитие группы выделены какие-то средства М, которые должны быть как-то распределены между предприятиями. В процессе работы предприятия вложенные в него средства частично расходуются (амортизируются), а частично сохраняются и снова могут быть перераспределены. Каждое предприятие за год приносит доход, зависящий от того, сколько средств в него вложено. В начале каждого хозяйственного года имеющиеся в наличии средства перераспределяются между предприятиями. Ставится вопрос: какое количество средств в начале каждого года нужно выделять каждому предприятию, чтобы, суммарный доход за т лет был максимальным?
Выигрыш W (суммарный доход) представляет собой сумму доходов на отдельных шагах (годах):

и, значит, обладает свойством аддитивности.
Управление хi на i-м шаге состоит в том, что в на чале i -го года предприятиям выделяются какие-то средства х1ъ x2,..., хік (первый индекс — номер шага, второй — номер предприятия). Таким образом, шаговое управление есть вектор с k составляющими:
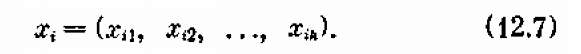
Разумеется, величины wt в формуле (12.6) зависят от количества вложенных в предприятия средств.
Управление х всей операцией состоит из совокупности всех шаговых управлений:
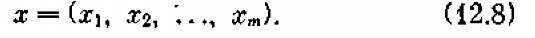
Требуется найти такое распределение средств по предприятиям и по годам (оптимальное управление х *), при котором величина W обращается в максимум.
В этом примере шаговые управления были векторами; в последующих примерах они будут проще и выражаться просто числами.
2. Космическая ракета состоит из т ступеней, а процесс ее вывода на орбиту — из т этапов, в конце каждого из которых очередная ступень сбрасывается. На все ступени (без учета «полезного» веса кабины) выделен какой-то общий вес:
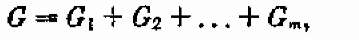
где Gі — вес i-й ступени.
В результате i -ro этапа (сгорания и сбрасывания i -й ступени) ракета получает приращение скорости Δi, зависящее от веса данной ступени и суммарного веса всех оставшихся плюс вес кабины. Спрашивается, как нужно распределить вес G между ступенями, чтобы скорость ракеты V при ее выводе на орбиту была максимальна?
В данном случае показатель эффективности (выигрыш) будет

где А. — выигрыш (приращение скорости) на i-м шаге. Управление х представляет собой совокупность весов всех ступеней Gi:
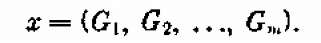
Оптимальным управлением х* будет то распределение весов по ступеням, при котором скорость V максимальна. В этом примере шаговое управление — одно число, а именно, вес данной ступени.
3. Владелец автомашины эксплуатирует ее в течение т лет. В начале каждого года он может принять одно из трех решений:
1) продать машину и заменить ее новой;
2) ремонтировать ее и продолжать эксплуатацию;
3) продолжать эксплуатацию без ремонта.
Шаговое управление — выбор одного из этих трех решений. Непосредственно числами они не выражаются, но можно приписать первому численное значение 1, второму 2, третьему 3. Какие нужно принять решения по годам (т. е. как чередовать управления 1, 2,3), чтобы суммарные расходы на эксплуатацию, ремонт и приобретение новых машин были минимальны?
Показатель эффективности (в данном случае это не «выигрыш», а «проигрыш», но это неважно) равен

(12.10)
где wі — расходы в i-м году. Величину W требуется обратить в минимум.
Управление операцией в целом представляет собой какую-то комбинацию чисел 1, 2, 3, например:
х = (3, 3, 2, 2, 2, 1, 3,...),
что означает: первые два года эксплуатировать машину без ремонта, последующие три года ее ремонтировать, в начале шестого года продать, купить новую, затем снова эксплуатировать без ремонта и т. д. Любое управление представляет собой вектор (совокупность чисел):
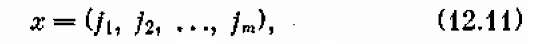 (12.11)
(12.11)
где каждое из чисел it, j2,..., jm имеет одно из трех значений: 1, 2 или 3. Нужно выбрать совокупность чисел (12.11), при которой величина (12.10) минимальна.
4. Прокладывается участок железнодорожного пути между пунктами А и В (рис. 12.1). Местность пересеченная, включает лесистые зоны, холмы, болота, реку, через которую надо строить мост. Требуется так провести дорогу из А в В, чтобы суммарные затраты на сооружение участка были минимальны.
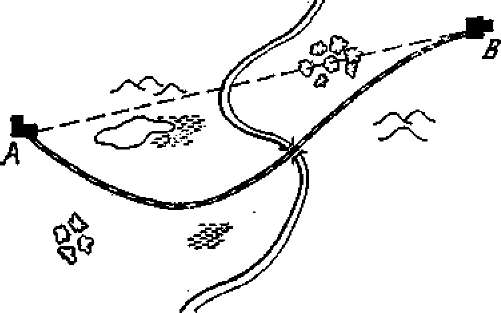 Рис. 12.1. Рис. 12.1. |
В этой задаче, в отличие от трех предыдущих, нет естественного членения на шаги: его приходится вводить искусственно, для чего, например, можно отрезок АВ разделить на т частей, провести через точки деления прямые, перпендикулярные АВ, и считать за «шаг» переход с одной такой прямой на другую. Если провести их достаточно близко друг от друга, то можно считать на каждом шаге участок пути прямолинейным. Шаговое управление на 7-м шаге представляет собой угол ф7, который составляет участок пути с прямой АВ. Управление всей операцией состоит из совокупности шаговых управлений:
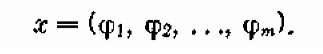
Требуется выбрать такое (оптимальное) управление х*, при котором суммарные затраты на сооружение всех участков минимальны:
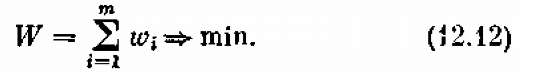
Итак, мы рассмотрели несколько примеров многошаговых задач исследования операций. А теперь поговорим о том, как можно решать подобного рода задачи?
Любую многошаговую задачу можно решать поразному: либо искать сразу все элементы решения на всех т шагах, либо же строить оптимальное управление шаг за шагом, па каждом этапе расчета оптимизируя только один шаг. Обычно второй способ оптимизации оказывается проще, чем первый, особенно при большом числе шагов.
Такая идея постепенной, пошаговой оптимизации и лежит в основе метода динамического программирования. Оптимизация одного шага, как правило, проще оптимизации всего процесса: лучше, оказывается, много раз решить сравнительно простую задачу, чем один раз — сложную.
С первого взгляда идея может показаться довольно тривиальной. В самом деле, чего казалось бы, проще: если трудно оптимизировать операцию в целом, разбить ее па ряд шагов. Каждый такой шаг будет отдельной, маленькой операцией, оптимизировать которую уже нетрудно. Надо выбрать на этом шаге такое управление, чтобы эффективность этого шага была максимальна. Не так ли?
Нет, вовсе не так! Принцип динамического программирования отнюдь не предполагает, что каждый шаг оптимизируется отдельно, независимо от других. Напротив, шаговое управление должно выбираться дальновидно, с учетом всех его последствий в будущем. Что толку, если мы выберем на данном шаге управление, при котором эффективность этого шага максимальна, если этот шаг лишит нас возможности хорошо выиграть на последующих шагах?
Пусть, например, планируется работа группы промышленных предприятий, из которых часть занята выпуском предметов потребления, а остальные производят для них машины. Задача операции — получить за т лет максимальный объем выпуска предметов потребления. Допустим, планируются капиталовложения на первый год. Исходя из узких интересов этого шага (года), мы должны были бы все наличные средства вложить в производство предметов потребления. Но правильно ли будет такое решение с точки зрения эффективности операции в целом? Очевидно, нет. Это решение — расточительное, недальновидное. Имея в виду будущее, надо выделить какую-то долю средств и па производство машин. От этого объем продукции за первый год, конечно, снизится, зато будут созданы условия для его увеличения в последующие годы.
Еще пример. Допустим, что в задаче 4 (прокладка железнодорожного пути из А в В) мы прельстимся идеей сразу же устремиться по самому легкому (дешевому) направлению. Что толку от экономии на первом шаге, если в дальнейшем он заведет нас (буквально или фигурально)в «болото»?
Значит, планируя многошаговую операцию, надо выбирать управление на каждом шаге с учетом всех его будущих последствий на еще предстоящих шагах. Управление на i-м шаге выбирается не так, чтобы выигрыш именно на данном шаге был максимален, а так, чтобы была максимальна сумма выигрышей я а всех оставшихся до конца шагах плюс данный.
Однако из этого правила есть исключение. Среди всех шагов есть один, который может планироваться попросту, без оглядки на будущее. Какой это шаг? Очевидно, последний! Этот шаг, единственный из всех, можно планировать так, чтобы он сам, как таковой, принес наибольшую выгоду.
Поэтому процесс динамического программирования обычно разворачивается от конца к началу: прежде всего планируется последний, m -й шаг. А как его спланировать, если мы не знаем, чем кончился предпоследний? Т. е. не знаем условий, в которых мы приступаем к последнему шагу?
Вот тут-то и начинается самое главное. Планируя последний шаг, нужно сделать разные предположения о том, чем кончился предпоследний, (т— 1)-й шаг, и для каждого из этих предположений найти условное оптимальное управление на m -м шаге («условное» потому, что оно выбирается исходя из условия, что предпоследний шаг кончился так-то и так-то).
Предположим, что мы это сделали, и для каждого из возможных исходов предпоследнего шага знаем условное оптимальное управление и соответствующий ему условный оптимальный выигрыш на m -м шаге. Отлично! Теперь мы можем оптимизировать управление на предпоследнем, (т — 1)-м шаге. Снова сделаем все возможные предположения о том, чем кончился предыдущий, (т — 2)-й шаг, и для каждого из этих предположений найдем такое управление на (т — 1)-м шаге, при котором выигрыш за последние два шага (из которых т-й уже оптимизирован!) максимален. Так мы найдем для каждого исхода (m — 2)-го шага условное оптимальное управление на (m —1)-м шаге и условный оптимальный выигрыш на двух последних шагах. Далее, «пятясь назад», оптимизируем управление на (т — 2)-м шаге и т. д., пока не дойдем до первого.
Предположим, что все условные оптимальные управления и условные оптимальные выигрыши за весь «хвост» процесса (на всех шагах, начиная от данного и до конца) нам известны. Это значит: мы знаем, что надо делать, как управлять на данном шаге и что мы за это получим на «хвосте», в каком бы состоянии ни был процесс к началу шага. Теперь мы можем построить уже не условно оптимальное, а просто Оптимальное управление х* и найти не условно оптимальный, а просто оптимальный выигрыш W*. В самом деле, пусть мы знаем, в каком состоянии S0 была управляемая система (объект управления S) в начале первого шага. Тогда мы можем выбрать оптимальное управление х1* на первом шаге. Применив его, мы изменим состояние системы на некоторое новое S1 *; в этом состоянии мы подошли ко второму шагу.
Тогда нам тоже известно условное оптимальное управление х 2*, которое к концу второго шага переводит систему в состояние S2*, и т. д. Что касается оптимального выигрыша W* за всю операцию, то он нам уже известен: ведь именно на основе его максимальности мы выбирали управление на первом шаге.
Таким образом, в процессе оптимизации управления методом динамического программирования многошаговый процесс «проходится» дважды: первый раз — от конца к началу, в результате чего находятся условные оптимальные управления и условные оптимальные выигрыши за оставшийся «хвост» процесса; второй раз — от начала к концу, когда нам остается только «прочитать» уже готовые рекомендации и найти безусловное оптимальное управление х*, состоящее из оптимальных шаговых управлений x*, х2*,..., хт*. Первый этап — условной оптимизации — несравненно сложнее и длительнее второго. Второй этап почти не требует дополнительных вычислений.
Автор не льстит себя надеждой, что из такого описания метода динамического программирования читатель, не встречавшийся с ним до сих пор, поймет по-настоящему его идею. Истинное понимание возникает при рассмотрении конкретных примеров, к которым мы и перейдем.

