 2017-12-14
2017-12-14 1647
1647Элементы основ однофакторного дисперсионного анализа
Дисперсионным анализом называется статистический метод обработки нормально распределенных случайных данных для оценки влияния на них качественных факторных признаков. В однофакторном дисперсионном анализе исследуется влияние одного контролируемого фактора, т.е. с известными уровнями влияния на части изучаемой выборки.
Случайность управленческих и экономических данных, характеризующих изучаемое явление, определяется влиянием многих неконтролируемых факторов. Их полный учет не возможен, что придает рассматриваемым данным вероятностные черты.
Однофакторный дисперсионный анализ имеет своей целью выявление систематического (неслучайного) влияния на распределение данных существенного контролируемого управленческого или экономического фактора, который может не иметь количественного измерения.
Систематизация и представление данных при однофакторном дисперсионном анализе рассматривается на примере влияния технологии обработки сырья на качество продукции. Технология выступает как фактор, и каждая конкретная технология, как i-й уровень фактора (i=1, 2, …, m). Здесь m –полное число используемых технологий. Качество продукции y систематизируется по уровням технологии с индексами i и номерам партий j=1, 2, …, ni.
Соответственно качество продукции, произведенной по технологии с i-м уровнем, в j-й партии обозначается как yij. Количество партий продукции, произведенной по технологии с i-м уровнем, обозначено как ni. Удобной формой представления систематизированной выборки данных является таблица.
| Индекс технологии, i | Индекс партии, j | ni | |||||
В таблице систематизированы данные для однофакторного дисперсионного анализа влияния технологии обработки сырья на качество продукции (время полного износа) в проверявшихся партиях: в строках перечисляются 4-х вида технологий (4 уровня контролируемого фактора), в столбцах – номера проверявшихся партий (у11=140, у12=141, у13=140 и т.д.).
Идея однофакторного дисперсионного анализа
Влияние рассматриваемого фактора (уровня технологии), если оно есть, проявляется в статистически значимом отклонении математических ожиданий (средних) в строках таблицы с разными уровнями технологии. Но устанавливается такой факт при анализе дисперсий.
Пусть: `y – общее среднее качества продукции;`yi – среднее качество при i-м уровне технологии; S2 – сумма квадратов отклонений качества относительно общего среднего. Тогда:
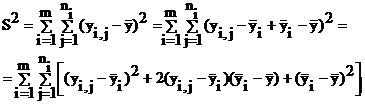
В последнем выражении удвоенное произведение равно нулю, поскольку
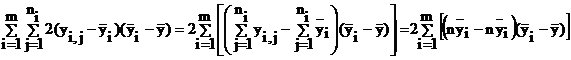
Остаются квадраты разностей, которые преобразуются к виду
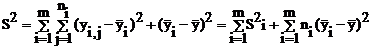
Первый член состоит из сумм квадратов внутригрупповых отклонений относительно групповых средних (для каждой строки), обозначенных как S2i. Внутригрупповые отклонения в таких суммах называются остаточными. Они не содержат систематического влияния рассматриваемого фактора, т.к. данные сгруппированы из условия его одинакового воздействия, и связаны со случайным несистемным воздействием множества неконтролируемых причин.
Второй член состоит из сумм квадратов отклонений средних в выделенных группах (строках) относительно общего среднего (математического ожидания), повторяемых для каждой варианты в группе, т.е. по ni раз. Именно эта сумма характеризует влияние рассматриваемого фактора. Чем значительнее его влияние, тем больше разности и сумма их квадратов.
Если влияния факторов нет, то `y1 =`y2 = …=`ym=`y, и вторая сумма равна нулю. Идея дисперсионного анализа состоит в оценке по дисперсиям значимости нарушений этих равенств.
В выборке нормально распределенных случайных величин, состоящей из групп, общее рассеяние S2 (сумма квадратов отклонения от общего среднего) разлагается на 2 составляющие (суммы квадратов отклонений): вариант в группах и групповых средних от общего среднего.
Этим составляющим рассеяния отвечают выборочные дисперсии:
D1,D2, …,Dm – внутригрупповые (для строк), где каждая Di=S2i/(ni-1);
Dmgr – межгрупповая для вариант, выражающая групповое рассеяние (строк) относительно общего среднего, как Dmgr= 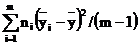 .
.
Оценки дисперсий находятся, как соответствующие суммы квадратов отклонений, поделенные на число степеней свободы. Число степеней свободы выборочной внутригрупповой дисперсии равно количеству отклонений в группе (строке) за вычетом 1, поскольку отклонения считаются относительно выборочного группового среднего из тех же данных.
Число степеней свободы выборочной межгрупповой дисперсия на 1 меньше числа групп (строк), поскольку общее среднее является средневзвешенным групповых средних.
Средневзвешенная внутригрупповая дисперсия Dо вычисляется из оценок внутригрупповых дисперсий, как Dо= 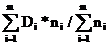 ;
;
Разложение общей дисперсии на составляющие, т.е. дисперсии Dmgr и Do, – это и есть дисперсионный анализ, как по смыслу термина анализ, так и по существу выполненных операций. При этом дисперсионный анализ опирается на процедуры сравнения дисперсий для выяснения влияния исследуемого фактора и оценки степени этого влияния на выборку данных.
Проверка гипотезы о равенстве дисперсий
Отсутствие влияния исследуемого фактора устанавливается проверкой гипотезы Но, называемой нулевой, о равенстве оценок дисперсий Dmgr=Do.
Для этого используется F-распределение отношения оценок дисперсий, нормированных по неизвестным значениям самих дисперсий (не оценок) Smgr и So, т.е. (Dmgr/Smgr)/(Do/So). Поскольку в нулевой гипотезе исследуется случай равенства дисперсий, то для принятия нулевой гипотезы, когда Smgr=So, рассматривается отношение оценок дисперсий F=Dmgr/Do.
F-распределение обычно связывается с Р. Фишером, разработавшим (1924 г.) другое распределение, для логарифма дисперсионного отношения.Позднее Снедекор (G.W.Snedekor, 1937) предложил обычно используемое распределение непосредственно для F-отношения, называемое распределением Фишера, иногда Фишера-Снедекора или Снедекора.
F-распределение дает вероятность распределения отношения оценок дисперсий 2-х нормальных выборок. Оценка каждой дисперсии удовлетворяет c2-распределению Пирсона: определяется суммой квадратов нормированных отклонений случайных величин относительно математического ожидания в выборке из генеральной совокупности, распределенной нормально.
Дисперсия Dmgr определяется суммой квадратов отклонений групповых средних от общего среднего. Суммы случайных величин в каждой группе (и рассчитанные по ним групповые средние) по центральной предельной теореме теории вероятностей сходятся к нормальному закону с ростом числа слагаемых. Практика статистических исследований показывает, что уже при нескольких слагаемых их суммы достаточно точно описываются нормальным законом. Поэтому Dmgr удовлетворяет c2-распределению Пирсона.
Дисперсии Do складывается из оценок дисперсий в группах. Каждая такая внутригрупповая оценка включает сумму квадратов отклонений рассматриваемых случайных значений относительно своего группового математического ожидания. Квадраты отклонений во всех группах должны подчиняться одному и тому же однородному c2-распределению. Иными словами, оценки внутригрупповых дисперсий должны относиться к нормальным выборкам из одной генеральной совокупности, распределенной по нормальному закону, что требует проверки.
Необходимо, чтобы общая совокупность случайных величин (всех групп) подчинялась нормальному закону, групповые выборки также являлись нормальными, и их выборочные дисперсии составляли однородный ряд оценок дисперсии генеральной совокупности.
Критериями согласия общей совокупности случайных величин (всех групп) с нормальным законом могут служить оценки асимметрии и эксцесса.
Однородность выборочных внутригрупповых дисперсий, как оценок дисперсии генеральной совокупности проверяется по F-критерию. Различия оценок внутригрупповых дисперсий должны быть статистически незначимы. Достаточно сравнить самую большую и самую малую оценки. Если их различие статистически незначимо, то у остальных оно еще менее значимо, и все они образуют однородный ряд оценок дисперсии генеральной совокупности.
В более надежном критерии Бартлета используются все выборочные внутригрупповые дисперсии (не только самые контрастные), но число степеней свободы должно быть не менее 5 (объемы групповых выборок не менее 6), что не выполняется для приведенных выше данных.
Если общая выборка всех групп не противоречит нормальному закону, и внутригрупповые оценки дисперсий отвечают одной и той же генеральной дисперсии, F-распределение позволяет проверить нулевую гипотезу Dmgr=Do, т.е. F=Dmgr/Do=1. F-распределение зависит от степеней свободы у анализируемых выборочных дисперсий, т.е. от m-1 и 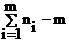 =N-m.
=N-m.
Плотность вероятности F-распределения имеет максимум при F=1, когда Dmgr=Do, и падает до 0 с увеличением F-отношения до +¥ и уменьшением до 0.
Равенство F=1 носит вероятностный характер, поскольку используемые в F-отношении оценки дисперсий являются случайными величинами, колеблющимися со стандартными отклонениями, зависящими от числа степеней свободы. Поэтому F-отношение может отличаться от 1 при равенстве истинных значений дисперсий и требуется установить значимость их различия.
Обычно нулевая гипотеза о равенстве F=1 отклоняется при вероятности менее 0,05. В этом случае вероятность ошибки отклонения нулевой гипотезы не превышает 0,05.
Принятая вероятность отклонения гипотезы называется критическим уровнем. Его выбор не так прост. При критическом уровне меньше 0,05 уменьшится вероятность ошибки отклонения нулевой гипотезы и ошибочного указания на системное влияние исследуемого фактора (ошибки первого рода). Но при этом возрастает вероятность ошибки принятия нулевой гипотезы и недооценки системного влияния исследуемого фактора (ошибки второго рода).
Случаи F£1 очевидны без всякого критерия, поскольку означают относительную малость межгрупповых отклонений и малую вероятность F>1.
Проблема вероятностной оценки отношения и проверки гипотезы Но возникает при F>1. Т.е. проверяется односторонняя гипотеза: находится вероятность того, что при F>1, различие дисперсий малозначимо. Малозначимое различие с большой вероятностью ошибки отклонения нулевой гипотезы означает, что отклонения групповых средних, несущих влияние исследуемого фактора, от общего математического ожидания, объясняются случайными причинами – неконтролируемыми факторами.
Большая величина F-отношения с вероятностью ошибки отклонения нулевой гипотезы, превышающей критический уровень, указывает на значимость отклонений внутригрупповых средних от общего математического ожидания, влияние контролируемого фактора и необходимость его учета.
Оценка степени влияния исследуемого фактора
Проверка нулевой гипотезы о равенстве дисперсий устанавливает достоверность влияния контролируемого фактора на изучаемое явление, но не оценивает меру этого влияния.
Количественной оценкой степени влияния фактора служит выборочный коэффициент детерминации. Он показывает, какую долю в общем рассеянии (в сумме квадратов отклонений всех N вариант от общего среднего) составляет сумма квадратов отклонений групповых средних от общего групповых под влиянием контролируемого фактора. Т.е. коэффициент детерминации – это доля рассеяния, объясняемого известной (детерминированной) причиной.
Коэффициент детерминации d удобнее выражать не через отношение соответствующих сумм квадратов отклонений, а через оценки межгрупповой (Dmgr) и общей (D) дисперсий, поскольку последнюю из них можно сразу получить в программных средствах с помощью встроенной функции или процедуры: d=[Dmgr(m-1)]/[D(N-1)].
Коэффициент детерминации равен нулю, если влияние фактора отсутствует, и возрастает до 1, когда он определяет все рассеяние, и оно становится детерминированным.
Недетерминированная доля рассеяния 1-d, не получившая объяснения, связана с множеством неучитываемых причин и изменяется от 0 до 1.
Однофакторный дисперсионный анализ в Mathcad
Операции однофакторного дисперсионного анализа рассматриваются на примере обсуждавшейся выборки данных о влиянии разных технологий обработки сырья на качество продукции (время ее полного износа).
Ввод исходных данных и их представление в виде векторов-столбцов
Исходные данные систематизированы в виде таблицы, приведенной в начале главы. Для дисперсионного анализа необходимы данные по каждой технологии (в строках), и количества исследованных партий продукции (в последнем столбце). Если исходная таблица имеется в файле Word, то указанные строки и столбец рекомендуется импортировать в Mathcad.
Однако непосредственно импортированные из Word строки и столбцы не всегда правильно интерпретируются Mathcad. Поэтому таблицу из Word рекомендуется вначале экспортировать в Excel, затем каждая необходимая строка и столбец там поочередно копируются в буфер и вставляются в Mathcad.
По умолчанию в Mathcad координаты векторов и матриц, т.е. индексы строк и столбцов, нумеруются, начиная с 0, что определяется системной переменной ORIGIN=0. Для более привычной индексации, начиная с 1, в рабочий лист Mathcad вводится команда
ORIGIN:=1
Для создания в Mathcad векторов с показателями качества для каждой технологии в Excel вначале выделяется 1-я строка с показателями качества по 1-й технологии и копируется в буфер. В рабочем листе Mathcad ниже первой команды вводится имя 1-й вектора-строки и операция присваивания
у1:=g
а в место-заполнитель производится вставка значений из буфера. Операция повторяется для 4-х строк:
у1:= (140 141 140 141 142 145)
у2:= (150 149 150 147)
у3:= (147 147 145 150 150)
у4:= (144 147 142 146)
Затем в исходной таблице выделяется и копируется столбец значений ni. В рабочий лист Mathcad вводится имя вектора-столбца количеств партий и операция присваивания
n:=g
в место-заполнитель вставляются значения из буфера,
затем с помощью встроенной функции length определяется
m:=length(n)
m – общее количество исследованных партий.
В Mathcad предусмотрены операции и встроенные функции для векторов-
столбцов, для получения которых векторы-строки необходимо транспонировать.
Оператор транспонирования вызывается кнопкой МТ на палитре Matrix.
Преобразуемые векторы-столбцы уi (с нижними индексами), становятся четырьмя компонентами создаваемого вектора-столбца у:
у1:=у1Т у2:=у2Т у3:=у3Т у4:=у4Т
Для дисперсионного анализа необходим вектор-столбец всей выборки, состоящий из векторов-столбцов у1, у2, у3 и у4. Объединение этих векторов возможно последовательным применением функции стыковки. Она имеет синтаксис stack(A,B), где два аргумента – имена стыкуемых векторов-столбцов А и В. Вместо последовательной стыковки у1 и у2, их объединенного вектора с у3 и затем второй стыковки с у4, рациональнее построить вложенную функцию стыковок путем подстановки в качестве аргументов векторов-столбцов, возвращаемых функциями стыковок. Для этого после ввода имени создаваемого вектора и оператора присваивания Y:=g в место-заполнитель вызывается встроенная функция стыковки, и вызов повторяется для каждого ее аргумента. Во вложенные (внутренние) функции стыковок в качестве аргументов подставляются имена векторов-столбцов у1 и у2, у3 и у4:
Y:=stack(stack(у1, у2), stack(у3, у4))
Объем всей выборки определяется, как размер (N) вектора Y:
N:= length(N) N=19 m=19
Это контрольная операция: разумеется, должно выполняться N = m.
Исследование типа распределения исходных данных
Операции дисперсионного анализа корректны для выборки случайной величины, распределенной по нормальному закону. Непротиворечие с ним анализируемых данных, представленных вектором Y, тестируется по выборочным оценкам асимметрии A и эксцесса E, которые у случайной величины, подчиняющейся нормальному закону, близки к 0.
В Mathcad 2000 и последующих версиях имеются встроенные функции для возвращения этих оценок: A:=skew(Y) A:= -0.174 E:= kurt(Y) E= -1.344
Оценки A и E отличаются от 0. Значимость абсолютных величин оценок устанавливается по сравнению с их среднеквадратичными погрешностями dA и dE. Для их вычисления встроенных функций нет, и расчеты выполняются по вводимым формулам:
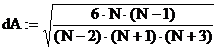 dA=0.524
dA=0.524 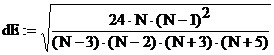 dE=1.014
dE=1.014
Поскольку абсолютная величина оценок A и E значимо (в 2-3 раза) не превышает их среднеквадратичных погрешностей dA и dE, то асимметрию и эксцесс можно полагать близкими к нулю, не противоречащими распределению по нормальному закону.
Проверка однородности оценок внутригрупповых дисперсий
Внутригрупповые дисперсии удобнее представить вектором, задав его элемент функцией Var с аргументом – элементом вектора вариант для каждой из 4-х групп (уровней технологии):
i:=1.. 4 Dgi:= Var(yi) 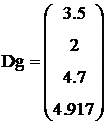
Для суждений об однородности оценок внутригрупповых дисперсий Dgi корректнее использовать F- критерий, поскольку объемы групповых выборок колеблются от 4 до 6, т.е. не все удовлетворяют условию критерия Бартлета. Из компонент вектора дисперсий видно, что самой большой и малой из них являются Dg4 и Dg2 с дисперсионным отношением Fg:
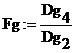
Встроенной функцией рF вероятности распределения Фишера с учетом степеней свободы возвращается вероятность Fg=1 для исследуемого Fg=Dg4/Dg2. Используя его, вычисляется вероятность р для «хвоста», т.е. вероятность оценок Fg, превышающих фактическую величину:
p:= 1-pF(Fg, n4 –1, n2 –1) p = 0.24
Полученная вероятность «хвоста» значительно превышает обычный критический уровень (0,05 и менее), при котором нулевую гипотезу можно отклонить. Отсюда следует, что даже максимально различающиеся оценки внутригрупповых дисперсий можно рассматривать, как выборочные для одной и той же генеральной дисперсии. Другие промежуточные оценки внутригрупповых дисперсий, характеризующиеся меньшей разностью, могут быть отнесены к одной и той же генеральной дисперсии с еще большей надежностью.
Оценка межгрупповой дисперсии
Межгрупповая дисперсия вариант Dmgr выражается через рассматривавшуюся сумму квадратов отклонений групповых средних относительно общего среднего.
Средние возвращаются встроенными функциями mean с аргументами – векторами уi (вариантами групп с разной технологией обработки сырья), и Y (вариантами всей выборки). Поэтому оценка межгрупповой дисперсии с учетом числа групп (4) и степеней свободы (на 1 меньше) можно представить в виде:
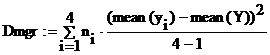 Dmgr=57.861
Dmgr=57.861
Оценка средневзвешенной внутригрупповой дисперсии
Внутригрупповое рассеяние и соответствующая ему внутригрупповая дисперсия не несет влияния исследуемого фактора, поскольку внутри группы, отвечающей одному уровню фактора, его воздействие одинаково. Следовательно, каждая внутригрупповая дисперсия определяется случайными несистемными воздействиями множества неконтролируемых причин, – так называемым остаточным рассеянием. Выборочные внутригрупповые дисперсии образуют однородный ряд оценок внутригрупповой дисперсии Do, что позволяет определить ее как средневзвешенную из этого ряда оценок:
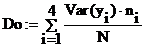 Do=3.798
Do=3.798
Число степеней свободы дисперсии Do равно количеству всех вариант за вычетом 4 – количества использованных средних 4-х групп, т.е. N-4.
Проверка нулевой гипотезы о равенстве дисперсий
Дисперсионный анализ состоит в проверке нулевой гипотезы Но – того, что F=Dmgr/Do=1 не превышает критического значения Fkr, вероятность которого по F-распределению отвечает выбранному уровню значимости, например 0.95. Критическая величина F-отношение возвращается обратной по отношению к функции вероятности распределения Фишера встроенной функцией qF (ее аргументами являются выбранный уровень значимости и степени свободы оценок дисперсий):
Fkr:=qF(0.95, 4-1, N-4) Fkr= 3.287
Фактическая величина F-отношения составляет:
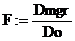 F=15.233
F=15.233
Поскольку фактическая величина F значительно превышает критическую, то гипотеза Но о равенстве дисперсий отклоняется. Вероятность ошибки первого рода – отклонения нулевой гипотезы и ошибочного указания на системное влияние исследуемого фактора возвращается встроенной функцией рF вероятности распределения Фишера с аргументами – фактическимF-отношением и степенями свободы оценок дисперсий: p:= 1 – pF(F, 4-1, N-4) p= 8.018×10-5
Вероятность ошибки отклонения нулевой гипотезы значительно меньше 0.05, т.е. маловероятно, что F-отношение незначимо отличается от 1.
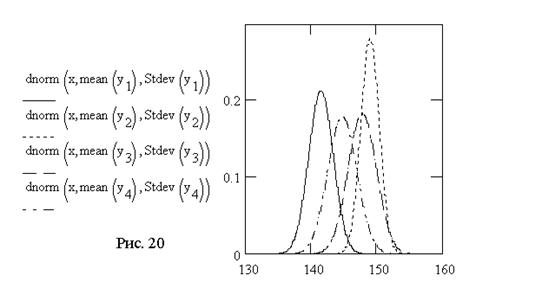
Системное влияние исследуемого фактора иллюстрируется выводом теоретических кривых плотности вероятностей нормального распределения с выборочными оценками параметров групповых выборок, отвечающих разным технологиям – элементам вектора качества уi (рис. 1).
Графики задаются в шаблоне плоского декартового типа: по оси абсцисс – значения качества, по оси ординат – теоретические плотности вероятностей нормального распределения, возвращаемые встроенных функций dnorm с аргументами: выборочным математическим ожиданием и стандартным отклонением в группе каждой технологии обработки сырья.
Количественная оценка влияния исследуемого фактора
Коэффициент детерминации d, являющийся количественной оценкой влияния исследуемого фактора, выражается, как было показано, через оценки общей и межгрупповой дисперсий, умноженные на число степеней свободы: 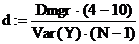 d:=0.753
d:=0.753
Отсюда следует, что 75.3% общего рассеяния значений качества обусловлено технологией, т.е. она весьма значительно влияет на качество.
Однофакторный дисперсионный анализ в Excel
Дисперсионный анализ в Excel рассматривается на примере обсуждавшихся данных о влиянии технологий обработки сырья на качество продукции (время полного износа).
Если исходные данные в виде таблицы имеются в файле Word, то прямоугольный блок таблицы с цифровыми ячейками копируется в буфер. В рабочем листе Excel табличный курсор устанавливается в левый верхний угол намеченного для таблицы диапазона и дается команда вставки содержимого буфера.
Проверка согласия выборки с нормальным законом распределения
Дисперсионный анализ корректен для выборки данных, распределенной по нормальному закону. Априорно закон распределения не известен и подлежит тестированию.
Простейшими критериями согласия фактического распределения с нормальным законом являются выборочные оценки асимметрии и эксцесса. Они при выполнении нормального закона ведут себя, как случайные величины с нулевыми математическими ожиданиями и стандартными отклонениями, зависящими от объема выборки. Согласными с нормальным законом полагаются оценки асимметрии и эксцесса, которые по абсолютной величине не превышают 2-3 стандартных отклонений.
Тестирование устанавливает несогласие фактического распределения с нормальным законом или согласие (непротиворечие) с ним. Другими словами, если даже одна из выборочных оценок значимо отличается от нуля, то нормальный закон отвергается, однако допустимые отклонения от нуля, являются необходимым, но недостаточным условием подчинения нормальному закону.
Выборочная оценка асимметрии возвращается встроенной функцией СКОС. Ее аргумент (скопированный блок данных, включая пустые ячейки) указывается в первой строке диалогового окна мастера функций. Стандартное отклонение выборочной оценки асимметрии рассчитывается по обсуждавшейся формуле, вводимой в формате Excel.
Возвращаемая функцией СКОС оценка асимметрии по абсолютной величине отличается от 0, но в пределах стандартного отклонения оценки, т.е. она значимо не отличается от нуля и не противоречит гипотезе распределения выборки по нормальному закону.
Аналогичным образом встроенной функцией ЭКСЦЕСС возвращается выборочная оценка эксцесса и рассчитывается стандартное отклонение оценки.
Абсолютная величина оценки эксцесса не превышает ее удвоенного стандартного отклонения, т.е. также значимо не отличается от нуля и не противоречит гипотезе распределения выборки по нормальному закону.
Задание встроенной процедуры однофакторного дисперсионного анализа
В Excel имеется встроенная процедура однофакторного дисперсионного анализа, вызываемая из списка Анализ данных… в меню Сервис. Если Анализ данных… отсутствует в меню Сервис, то из него вызывается команда Надстройки… и в ее списке флажком помечается Пакет анализа. Для запуска процедуры однофакторного дисперсионного анализа в списке Анализ данных… выбирается Однофакторный дисперсионный анализ.
Запуск процедуры выводит одноименный диалог Однофакторный дисперсионный анализ, в котором выполняются следующие установки:
в поле Входной диапазон вводится диапазон ячеек с анализируемыми данными – скопированный блок таблицы, включая пустые ячейки;
переключатель Группирование устанавливается в положение По строкам соответственно группировке в строках исходных данных по уровням;
переключатель Метки в первой строке/Метки в первом столбце не устанавливается – во входном диапазоне нет меток (заглавия выходного диапазона выводятся по умолчанию);
параметр Альфа с вероятностью критической величины F-отношения, при превышении которой нулевая гипотеза отклоняется, можно оставить со значением 0,05 по умолчанию;
в поле Выходной диапазон вводится адрес ячейки, расположенной в левом верхнем углу выходного диапазона, размеры которого рассчитываются автоматически (при попадании туда занятых ячеек выводится сообщение);
переключатель Новый лист устанавливается для открытия нового листа в текущей книге и вставки результатов анализа, начиная с ячейки A1 (имя нового листа вводится в поле переключателя), но при выборе опции Выходной диапазон, т.е. выводе результатов в текущий лист, поле Новый лист не доступно;
переключатель Новая книга для открытия новой книги вставки результаты, начиная с ячейки A1 на 1-м листе.
После выполнения установок в диалоге нажимается кнопка ОК.
Результаты однофакторного дисперсионного анализа и их интерпретация
Результаты анализа выводятся на рабочий лист в указанное место для выходного диапазона в таблицах Итоги и Дисперсионный анализ (рис. 1).
| Однофакторный дисперсионный анализ | ||||||
| ИТОГИ | ||||||
| Группы | Счет | Сумма | Среднее | Дисперсия | ||
| Строка 1 | 141,5 | 3,5 | ||||
| Строка 2 | ||||||
| Строка 3 | 147,8 | 4,7 | ||||
| Строка 4 | 144,75 | 4,916667 | ||||
| Дисперсионный анализ | ||||||
| Источник вариации | SS | df | MS | F | P-Знач. | F критич. |
| Между группами | 173,58 | 57,860 | 15,21311 | 8,1E-05 | 3,28738 | |
| Внутри групп | 57,05 | 3,8033 | ||||
| Итого | 230,63 | |||||
| Рис. 1 |
Проверка однородности внутригрупповых дисперсий в таблице Итоги
Первая из выводимых таблиц (Итоги) содержит приведенные на рис. 21 сведения по группам (строкам), т.е. уровням влияния фактора.
Как было показано, выборочные внутригрупповые дисперсии должны составлять однородный ряд оценок одной и той же дисперсии неконтролируемых факторов (множества случайных причин). Выполнение условия проверяется F-критерием для самой большой и самой малых оценок по значимости их различий. Если различия самых контрастных оценок по F-критерию малозначимы, весь ряд оценок внутригрупповых дисперсий полагается однородным, отвечающим одной и той же дисперсии неконтролируемых факторов.
Как видно, из таблицы Итоги (рис. 1), самая большая и малая внутригрупповые дисперсии расположены в 4-й и 2-й строках с дисперсионным отношением Fg=4,92/2.
Встроенная функция FРАСПОБР (обратная для распределения Фишера) возвращает критическую величину F-отношения при вероятности ошибки отклонения нулевой гипотезы 0,05 и фактических степенях свободы в группах. Критическая величина превосходит Fg и не дает оснований отклонения нулевой гипотезы о равенстве исследованных дисперсий.
Содержание таблицы Дисперсионный анализ
Во второй таблице (рис. 1) в столбцеSS – суммы квадратов отклонений в строках:
Между группами – групповых средних относительно общего математического ожидания, умноженных на объемы групп, характеризующих влияние рассматриваемого фактора;
Внутри групп – вариант в группах относительно групповых средних – остаточное рассеяние, вызванное случайными воздействиями множества неконтролируемых причин;
Итого – суммарное общее рассеяние (внутри- и межгрупповое).
В столбце df – степени свободы для указанных видов рассеяния.
В столбцеMS– дисперсии (Dmgr и Do) для указанных видов рассеяния – частные от делением данных столбцов SS и df.
В столбце F приведено F-отношение, подсчитанное, как F=Dmgr/Do.
В столбце P-Значение – вероятность F-распределения для приведенных значений
F-отношения и степеней свободы.
В столбце F критическое приведено F-отношение, отвечающее критическому уровню, задававшемуся параметром альфа (0,05), с указанными степенями свободы.
Из выведенных результатов следует, что вероятность ошибки при отклонении нулевой гипотезы, т.е. при принятии влияния возрастного фактора, очень мала и фактическое
F-отношение значительно больше критической величины для принятого уровня (0,05). Следовательно, технология статистически значимо влияет на качество продукции.
Оценка степени влияния исследуемого фактора
Степень влияния рассматриваемого фактора (технологий) оценивается коэффициентом детерминации d, подсчитываемым, как отношение данных столбцаSS:строки Между группами к строке Итого.
ПОНЯТИЯ ДВУХФАКТОРНОГО ДИСПЕРСИОННОГО АНАЛИЗА
И ЕГО РЕАЛИЗАЦИЯ ВСТРОЕННЫМИ ПРОЦЕДУРАМИ
СТАНДАРТНЫХ ПРОГРАММНЫХ СРЕДСТВ
ЭЛЕМЕНТЫ ОСНОВ ДВУХФАКТОРНОГО ДИСПЕРСИОННОГО АНАЛИЗА
В двухфакторном дисперсионном анализе исследуется систематическое (неслучайное) контролируемое влияние двух качественных факторов на выборку нормально распределенных случайных величин. Случайность управленческих и экономических величин определяется влиянием многих неконтролируемых причин, полный учет которых не возможен.
Вместе с тем, случайные данные могут испытывать систематическое влияние определенных фиксируемых факторов. Такое влияние является контролируемым, т.е. известны уровни и конкретные объекты (их перечни) воздействия. При этом природа объектов, как случайных величин, сохраняется, но происходит изменение параметров распределений в группах с разными уровнями влияния. Рассматривается смещение групповых математических ожиданий в зависимости от уровня влияния факторов.
Итак, общая изменчивость выборочных данных имеет две составляющие, определяемые:
многими случайными (неконтролируемыми) причинами;
конкретными систематическими неслучайными факторами с известными количественно или качественно выраженными уровнями воздействия.
Исследование в выборке нормально распределенных случайных величин общей изменчивости, ее разложение и оценка значимости систематической контролируемой составляющей является предметом дисперсионного анализа.
Систематизация исходных данных и их обозначения
Исходные данные для двухфакторного (с влиянием факторов А и В) дисперсионного анализа систематизируются в виде таблицы, как показано ниже. Положение (адрес) исходных данных в систематизированной таблице определяется 3-мя индексами: i(порядковым номером столбца – уровня фактора А), j (порядковым номером строки – уровня фактора В) и k (порядковым номером в основной ячейке – серии с одинаковыми индексами iи j). Таким образом, любую варианту в выборке (в таблице) можно обозначить, как xijk с индексами от 1до соответственно I, J и K, – в данном примере I=3, J=4 и K=5.
| ГРУППЫ | По уровням фактора А | ||||||||||||||
| По уровни фактора В | i=1 | i=2 | i=3 | ||||||||||||
| j=1 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 |
| j=2 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 |
| j=3 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 |
| j=4 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 | k=1 | k=2 | k=3 | k=4 | k=5 |
Средние для всей выборки и групп, выделяемых при систематизации, обозначаются:
`хij – в основных ячейках по значениям xijk в каждой с индексами от k = 1 до k = К (К=5);
`хi – ячеек по столбцам (среднее из средних `хij с одинаковыми индексами i);
`хj – ячеек по строкам (среднее из средних `хij с одинаковыми индексами j);
`х – всех вариант (среднее из средних `хij или`хi или`хj).
Идея и логика двухфакторного дисперсионного анализа
Идея метода состоит в анализе, т.е. в разложении общей вариации данных (их суммарной дисперсии) на компоненты, вызываемые:
многими случайными (неконтролируемыми) причинами;
систематическим контролируемым (неслучайным) влиянием фактора А;
систематическим контролируемым (неслучайным) влиянием фактора В;
систематическим контролируемым (неслучайным) взаимодействием факторов А и В.
Но практически при двухфакторном дисперсионном анализе решаются более простые задачи – достаточно выяснить: являются ли существенными компоненты суммарной дисперсии, вызываемые факторами А и В и эффектами их взаимодействия. Для этого вычисления всех указанных компонент дисперсии не требуется и программными средствами не предусматривается. Вместо этого, находятся дисперсии структурных элементов таблицы SA (столбцов), SB (строк) и SAВ (ячеек), которые включают дисперсии, вносимые рассматриваемыми факторами и дисперсию (обозначим ее D) многих случайных (неконтролируемых) причин:
SAB= КDАB+D; SA= KJDА + KDAB + D; SВ = KIDВ + KDAB + D.
Если влияние факторов А и В или эффектов их взаимодействия отсутствует, то вызываемые ими дисперсии (DА,DB, DАB) равны нулю и для дисперсий элементов таблицы SA, SB и SAВсправедливы приближенные соотношения:
SA»D; SВ»D; SAB»D,
Влиянию рассматриваемых факторов отвечает нарушение этих приближенных равенств. Проблема состоит в том, чтобы оценить, насколько существенно дисперсии структурных элементов таблицы SA, SB и SAВ отличаются от дисперсии D, вызываемой неконтролируемыми (случайными) причинами. Значимость нарушения приближенных равенств дисперсий оценивается по вероятности ошибки при отклонении гипотезыНо, состоящей в том, что F=SА/D (F=SВ/D или F=SАВ/D) меньше выбранного уровня значимости – вероятности F-распределения.
Напомним, что F-распределение Р. Фишера дает вероятность равенства оценок дисперсий, из которых составлено F-отношение, с учетом числа их степеней свободы. Плотность вероятности F-распределения имеет максимум при значении F-отношения, равном 1, и уменьшается до 0 при отклонении отношения от 1, как в сторону увеличения, так и уменьшения.
Почему равенство F=1 носит вероятностный, а равенства дисперсий приближенный характер? Дело в том, что оценки дисперсий определяются с некоторыми погрешностями, зависящими от числа степеней свободы, из-за чего отношение оценок может отличаться от 1, а приближенное равенство дисперсий нарушается при равенстве истинных значений дисперсий.
Какую вероятность считать достаточной для отклонения нулевой гипотезы? Обычно нулевая гипотеза отклоняется при вероятности F=1 менее 0,05. Это означает, что вероятность ошибки отклонения не превышает 0,05. Принятую вероятность отклонения гипотезы называют критическим уровнем. Таблицы F-распределения составлены для ряда уровней значимости, в т.ч. больше и меньше 0,05. Какой уровень взять в качестве критического? При критическом уровне менее 0,05 уменьшится вероятность ошибки отклонения нулевой гипотезы и ошибочного указания на системное влияние исследуемого фактора, но возрастает вероятность ошибки принятия нулевой гипотезы и недооценки системного влияния исследуемого фактора.
Случаи F£1 очевидны (без всякого критерия), поскольку означают относительную малость рассеяний, вызываемых изучаемыми факторами, и малую вероятность того, что F>1.
Проблема вероятностной оценки отношения и проверки гипотезыНовозникает в случаях F>1. Т.е. проверяется односторонняя гипотеза. Находится вероятность того, что, хотя для оценок дисперсий F>1, сами дисперсии все-таки могут быть равны.
Равенство дисперсий означает, что отклонения от общего математического ожидания для групповых средних, с влиянием исследуемого фактора, не более случайных остаточных отклонений неконтролируемых причин. И, наоборот, если F-отношение превышает критический уровень, то это указывает на значимость отклонений от общего математического ожидания групповых средних с разными уровнями влияния исследуемых контролируемых факторов, и необходимость их учета.
Дисперсия неконтролируемых (случайных) причин D
В каждой основной ij-й ячейке таблицы рассеяние вариантхijk относительно среднего в ней ` хij, т.е. дисперсия серии Dij, является оценкой дисперсии неконтролируемых (случайных) причин. Dij свободно от влияния факторов, поскольку их влияние, если оно есть, во всех значениях и среднем в каждой ячейке одинаково и уничтожается при вычитании:
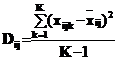 .
.
В знаменателе выражения находится число степеней свободы К-1, определяемое количеством вариант в серии, уменьшенной на 1 с учетом подсчитанного из них среднего`хij.
Еще лучшей (более надежной) оценкой рассеяния множества неконтролируемых (случайных) причин является среднее из дисперсий всех серий во всех основных ячейках
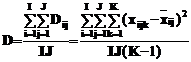
Оценка дисперсии имеет IJ(K-1) степеней свободы, равное общему числу вариант, уменьшенному на количество средних во всех сериях.
Совместное рассеяние, вносимое взаимодействием факторов А и В
и неконтролируемыми причинами
Кроме так называемых главных эффектов, состоящих в систематическом независимом влиянии факторов А и В, могут проявляться эффекты их взаимодействия, т.е. изменение влияния уровня одного фактора, обусловленное уровнем другого фактора. Эффекты взаимодействия зависят от уровней обоих факторов (i и j). Т.е. данные в каждой основной ячейке таблицы могут испытывать влияние взаимодействия факторов, которое складывается со случайными отклонениями, вносимыми многими неконтролируемыми причинами.
Среднее значение серии вариант в основной ячейке`хij может приобрести суммарное рассеяние S под влиянием дисперсии взаимодействия факторов DAB и рассмотренной выше дисперсии D многих случайных неконтролируемых причин:
S=DAB+D/K.
Последнее слагаемое – дисперсия многих случайных неконтролируемых причин для среднего из К значений вариант в ячейке. Случайные колебания вариант в их среднем усредняются (уменьшаются в К раз). Первое слагаемое представляет собой дисперсию взаимодействия факторов DAB, эффект которых для всех вариант в ячейке и их среднего является одинаковым.
Совместное рассеяние, вызываемое эффектом взаимодействия факторов и влиянием многих случайных неконтролируемых причин, принято характеризовать величиной
SAB = KS = KDAB+D.
Отсутствие взаимодействия факторов (DАB=0) SAB=D отвечает нулевой гипотезе.
Непосредственно из табличных данных ни S, ни SAB не выражаются, но их можно найти из дисперсий средних значений строк таблицы и средних значений серий в столбцах.
1. Рассеяние средних значений строк`хj относительно общего среднего`х характеризуется несмещенной оценкой дисперсии
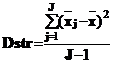
Несмещенная оценка дисперсии находится, как сумма квадратов отклонений, деленная на количество строк в соответствии с числом степеней свободы J-1.
Дисперсия Dstr раскладывается на 2 компоненты:
DB – уровней фактора B, который изменяется от строки к строке;
S/I – неконтролируемых причин и эффектов взаимодействия факторов В и А для средних по строке из относящихся к ней средним серий (в I ячейках каждой строки).
В соответствие с этим дисперсия средних значений строк представляется в виде суммы:
Dstr= DB+ S/I.
Последнее слагаемое здесь представляет собой дисперсию S неконтролируемых причин и эффектов взаимодействия факторов В и А, уменьшенную в I раз, как относящуюся к среднему по строке из I ячеек. Заметим, что уменьшение дисперсии S относится к ее обоим составляющим, т.к. усреднение идет не внутри ячейки, а между ними (по строке).
2. Рассеяние средних в ячейках `хij внутри i-го столбца относительно его среднего`хi характеризуется несмещенной оценкой дисперсии, которую можно обозначить, как Di:
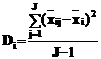
Несмещенная оценка дисперсии находится, как сумма квадратов отклонений, деленная на количество ячеек (строк), приведенное к числу степеней свободы J-1.
Дисперсию Di можно разложить на 2 компоненты:
DiВ – уровней фактора B, изменяющихся между строками в i -м столбце;
Si – неконтролируемых причин и эффектов взаимодействия факторов В и А на уровне i.
Поэтому дисперсия представляется в виде Di= DiВ+ Si.
Еще лучшей (более надежной) оценкой этих компонент является среднее из дисперсий по всем столбцам
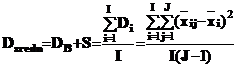
Из найденных в п. 1 и п. 2 дисперсий находится искомое рассеяние S неконтролируемых причин и эффектов взаимодействия факторов В и А: Dsredn– Dstr = DB+S–(DB+ S/I).
Очевидно, S=(Dsredn– Dstr)I/(I-1).
Через элементы таблицы с систематизированными данными искомую величину можно выразить в виде
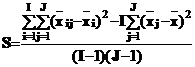
Найденная дисперсия S и линейно связанная с ней дисперсия SAB = KS, очевидно, имеют по (I-1)(J-1) степеней свободы.
Дисперсия средних по столбцам, как отражение влияния фактора А
Рассеяние средних по столбцам ` хiотносительно общего среднего ` х характеризуется так называемой несмещенной оценкой дисперсии
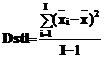
Несмещенная оценка дисперсии находится с учетом числа степеней свободы: сумма квадратов отклонений средних по столбцам определяется относительно их общего среднего и число степеней свободы становится на 1 меньше.
Дисперсию Dstl можно разложить на 2 компоненты:
DА – уровней фактора А;
S/J – неконтролируемых причин и эффектов взаимодействий факторов В и А для средних по столбцам.
Поэтому дисперсия представляется в виде
Dstl= DА + S/J.
Последнее слагаемое здесь представляет собой рассматривавшуюся дисперсию S неконтролируемых причин и эффектов взаимодействия факторов А и В, уменьшенную в J раз, как относящуюся к среднему по столбцу из J ячеек (и строк).
Учитывая, что
S=DAB+D/K, Dstl= DА + DAB/J +D/KJ или KJDstl= KJDА + KDAB + D.
Эта дисперсия с I-1 степенями свободы обозначается SA и отражает влияние фактора А:
SA= KJDА + KDAB + D= KJDstl = KJ 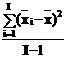
Дисперсия средних значений строк, как отражение влияния фактора В
Несмещенная оценка дисперсии средних значений строк`хj относительно общего среднего`х уже рассматривалось:
Было показано, что дисперсию Dstr можно разложить на 2 компоненты:
DB – уровней фактора B, который изменяется от строки к строке;
S/I – неконтролируемых причин и эффектов взаимодействия факторов В и А для средних по строке из относящихся к ней средним серий (в I ячейках каждой строки).
Поэтому дисперсия средних значений строк представляется в виде
Dstr= DB+ S/I.
Учитывая, что S=DAB+D/K, Dstr= DB+ DAB/I +D/KI или KIDstr= KIDВ+ KDAB + D.
Полученную дисперсию с J-1 степенями свободы принято обозначать SВ, и использовать для оценки влияния фактора В, т.е.
SВ = KIDВ + KDAB + D = KIDstr= KI 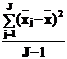
ДВУХФАКТОРНЫЙ ДИСПЕРСИОННЫЙ АНАЛИЗ В EXCEL
Для двухфакторного дисперсионного анализа в электронной таблице Excel используется пакет Анализ данных со встроенными программами «Двухфакторный дисперсионный анализ с повторениями» (случай одинаковых серий данных в основных ячейках) и «Двухфакторный дисперсионный анализ без повторений» (в основных ячейках по одному значению).
Исходные данные, их ввод и структурирование для анализа
Двухфакторным дисперсионным анализом исследуется влияние на суточный объем продаж товаров двух факторов: периода продаж – фактора А и размещения магазинов – фактора В. Данные по объемам продаж (тыс. руб.) представлены в таблице.
Прежде, чем запускать программу двухфакторного дисперсионного анализа, в рабочий лист Excel необходимо ввести систематизированную таблицу с исходными данными.
| ГРУППЫ | По уровням фактора А (периоды продаж) | |||||||||||
| По уровни фактора В (магазины) | i=1 (I квартал) | i=2 (II квартал) | i=3 (III квартал) | i=1 (IV квартал) | ||||||||
| j=1 (в микрорайоне) | 10,9 | 10,6 | 11,2 | 10,9 | 10,5 | 11,8 | 10,9 | 9,7 | 9,1 | 11,9 | 11,3 | 11,4 |
| j=2 (в центре города) | 13,5 | 12,8 | 13,6 | 14,9 | 16,1 | 14,5 | 14,5 | 14,8 | 15,0 | 14,4 | 14,9 | 15,3 |
| j=3 (возле вокзала) | 16,3 | 17,6 | 18,1 | 18,1 | 18,1 | 17,7 | 19,5 | 20,1 | 19,3 | 18,7 | 19,0 | 20,1 |
Закрашенный блок таблицы с числовыми данными выделяется, копируется в буфер, откроем рабочий лист Excelи в него вставляется содержимое буфера.
Скопированную таблицу, в которой серии («повторения» в основных ячейках) являются строками, необходимо преобразовать так, чтобы серии оказались в столбцах. Для преобразования таблица в рабочем листе Excel выделяется, копируется в буфер и выбирается ячейка, определяющее место вставки преобразованной таблицы. При этом левее первого столбца необходимо предусмотреть свободный столбец, а выше первой строки – свободную строку. В меню Правка выбирается команда Специальная вставка… с опцией транспонировать.
Проверка согласия с нормальным законом и нормализация вариант
Перед выполнением дисперсионного анализа необходимо убедиться в согласии распределения исследуемой выборки с нормальным законом. Согласие фактического распределения с нормальным законом проверяется по выборочным значениям асимметрии (А) и эксцесса (Е).
Выборочная величина асимметрии возвращается встроенной функцией СКОС. Она выбирается в списке функций, относящихся к категории Статистические. Ее аргументом является диапазон исходных данных, т.е. таблица с ними.
В нормально распределенной выборке А=0. Найденное выборочное значение также близко к 0. Среднеквадратичная погрешность оценки dA находится по формуле

которую следует ввести в формате Excel (N – это общее число вариант). Вычисление показывает, что оценка А отклоняется от 0 значительно меньше ее среднеквадратичной погрешности.
Выборочная оценка эксцесса возвращается одноименной функцией также как указано для асимметрии, а погрешность – по формуле
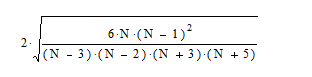

Для нормально распределенной выборки Е=0. В нашем случае выборочное значение эксцесса отклоняется от 0 меньше удвоенной среднеквадратичной погрешности.
Таким образом, выборочные асимметрия и эксцесс не противоречат гипотезе нормального распределения исследуемой выборки – необходимому условию корректного выполнения дисперсионного анализа.
Запуск программы двухфакторного дисперсионного анализа
и установка параметров в диалоговом окне программы
В Excel имеется встроенная процедура двухфакторного дисперсионного анализа, вызываемая из списка Анализ данных… в меню Сервис. Если Анализ данных… отсутствует в меню Сервис, то из него вызывается команда Надстройки… и в ее списке флажком помечается Пакет анализа. Поскольку исходные данные состоят из серий одинаковой численности для каждого сочетания факторов (в каждой основной ячейке), то в пакете Анализ данных… выбирается процедура Двухфакторный дисперсионный анализ с повторениями.
Запуск процедуры приводит к выводу одноименного диалога Двухфакторный дисперсионный анализ с повторениями. В диалоге производятся следующие установки:
в поле Входной диапазон вводится ссылка на ячейки, содержащие анализируемые данные, т.е. скопированную таблицу, включая свободную строку сверху и свободный столбец слева;
в поле Число строк на выборку вводится число строк, соответствующих объему серий (повторяющихся данных), – в данном случае вводится число 3;
в поле Альфа вводится уровень значимости для критических параметров F-статистик, т.е. вероятность ошибки отклонения верной гипотезы – можно оставить 0,05 (по умолчанию);
в поле Выходной диапазон вводится адрес ячейки, расположенной в левом верхнем углу выходного диапазона, размеры которого рассчитываются автоматически, при попадании туда занятых ячеек появится соответствующее предупреждение;
переключатель Новый лист устанавливается для открытия нового листа в текущей книге и вставки результатов анализа, начиная с ячейки A1 (имя нового листа вводится в поле переключателя), но при выборе опции Выходной диапазон, т.е. выводе результатов в текущий лист, поле Новый лист не доступно;
переключатель Новая книга устанавливается при необходимости открыть новую книгу и вставить результаты анализа в ячейку A1 на первом листе в этой книге.
После установки необходимых параметров в диалоговом окне для вывода результатов в нем нажимается кнопка ОК.
Результаты двухфакторного дисперсионного анализа с повторениями
Результаты обработки данных и их анализа выводятся в виде двух таблиц.
Первая таблица содержит результаты первичной обработки данных по сериям (в основных ячейках) и уровням обоих факторов. Она состоит из столбцов с данными по сериям, относящихся к уровням фактора А и блоков строк, каждый из которых соответствует сериям одного уровня фактора В.
Первый столбец таблицы состоит из обозначений параметров для каждой серии:
Счет – количество вариант в серии – в данном случае по 3;
Сумма – сумма значений вариант в серии;
Среднее – среднее из значений вариант в серии;
Дисперсия – несмещенная оценка дисперсии значений вариант в серии относительно ее среднего, подсчитанная с учетом числа степеней свободы в серии, т.е. 2=3-1.
Второй, третий и четвертый столбцы содержат значения параметров для серий соответственно первого, второго и третьего уровней фактора А.
Пятый (последний) столбец является итоговым для строк, соответствующих уровням влияния фактора В. Вначале выводится общее количество вариант в сериях, относящихся к данному уровню влияния, т.е. 9=3+3+3. Ниже – сумма сумм по сериям, приведенным левее, еще ниже – среднее значение для данного уровня фактора В. Последней стоит несмещенная оценка дисперсии вариант для данного уровня фактора В.
Нижний (итоговый) строковый блок первой таблицы содержит итоги по каждому уровню фактора А, т.е. по столбцам, обозначенные:
Счет – общее количество вариант в сериях для каждого уровня 12=3+3+3+3;
Сумма – суммы значений вариант в сериях, относящихся к каждому уровню А;
Среднее – средние из значений вариант в сериях для каждого уровню фактора А;
Дисперсия – несмещенная оценка дисперсий вариант для каждого уровня фактора А.
Вторая таблица состоит из результатов двухфакторного дисперсионного анализа с повторениями. Столбцы второй таблицы имеют следующие названия и информацию:
Источник вариации – названия вычисляемых рассеяний (дисперсий);
SS – суммы квадратов отклонений, отвечающих названным слева дисперсиям;
df – степени свободы для приведенных слева сумм квадратов отклонений;
MS – дисперсии (суммы квадратов отклонений, поделенные на число степеней свободы);
F – отношение дисперсии к дисперсии неконтролируемых причин в строке Внутри;
P-Значение – вероятность ошибки отклонения нулевой гипотезы;
F критическое – F-отношение с критическим уровнем, задаваемым, как альфа (0,05).
Вероятности ошибок можно вывести функцией FРАСП для указанных F-отношения и числа степеней свободы; величину F критическое – функцией FРАСПОБР.
Строки второй таблицы, т.е. источники рассеяния, названы в первом столбце:
Выборка – строка с данными по изменчивости, вызываемом фактором В, содержащая сумму квадратов отклонений, число степеней свободы, дисперсию SВ, F-отношение, равное SВ/D; вероятность ошибки отклонения нулевой гипотезы и критическую величину F-отношения;
Столбцы – строка с данными по изменчивости, вызываемой влиянием фактора А, содержащая указанные выше показатели, но относящиеся кSА;
Взаимодействие – строка с данными по изменчивости, вызываемой взаимодействием факторов А и В, и содержащая перечислявшиеся выше показатели, но относящиеся кSАВ;
Внутри – строка с данными по изменчивости, вызываемой неконтролируемыми (случайными) причинами, которые предполагаются присущими внутренней природе рассматриваемых величин и не связанными с внешними воздействиями (отсюда название строки).
Обработка и интерпретация результатов дисперсионного анализа
Явно выводимые итоговые результаты дисперсионного анализа состоят в отклонении с очень небольшой, близкой к 0 вероятностью, ошибки нулевых гипотез об отсутствии влияния факторов А и В и эффектов их взаимодействия.
Проверка однородности оценок дисперсий в сериях
Оценкой рассеяния множества неконтролируемых (случайных) причин является, как указывалось, среднее из дисперсий всех серий во всех основных ячейках:
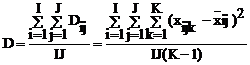
При этом дисперсии серий Dij, рассматриваются как выборочные оценки неизвестной генеральной дисперсии и должны быть однородны. Т.к. объемы серий малы и состоят из 3-х вариант, то для проверки однородности дисперсий серий воспользуемся F- критерием, применив его к самой большой и малой из дисперсий.
Дисперсии серий Dij выводятся в 4-х блоках первой таблицы в строках Дисперсия (в трех столбцах). Среди них найдем самую малую и большую с помощью встроенных функций Мин и Макс. Составим из них F-отношение 0,863/0,053=16,19 и найдем для него вероятность ошибки при отклонении нулевой гипотезы (вероятность распределения Фишера) с помощью встроенной функции FРАСП для 2-х степеней свободы каждой дисперсии.
Возвращаемая функцией вероятность 0,058 превышает обычно используемый критический уровень (0,05 и менее), т.е. даже самые контрастные выборочные дисперсии не имеют значимых различий и могут рассматриваться, как выборочные из одной и той же генеральной совокупности. Другие оценки дисперсий серий, с меньшим различием, могут полагаться однородными с еще большей надежностью.
Оценка степени влияния исследуемого фактора
Проверка нулевых гипотез о равенстве дисперсий не обнаруживает или выявляет влияние исследуемых контролируемых факторов и эффекта их взаимодействия на объем продаж.
Для оценки степени влияния каждого из них используются выборочные коэффициенты детерминации (dА,dВ и dАВ), отвечающие разложению общего рассеяния на составляющие:
сумму квадратов отклонений от средних в сериях, которая характеризует изменчивость, обусловленную случайными причинами;
сумму квадратов отклонений под влиянием различных уровней воздействия фактора А;
сумму квадратов отклонений под влиянием различных уровней воздействия фактора В;
сумму квадратов отклонений под влиянием эффектов взаимодействия обоих факторов.
Поскольку все эти суммы и их итог выведены во второй таблице, то остается вычислить отношения, характеризующие долю в общем рассеянии указанных составляющих.
Если влияние исследуемого фактора отсутствует, то коэффициент детерминации равен нулю. Теоретически величина коэффициента детерминации может возрастать до 1, когда все рассеяние практически целиком объясняется влиянием исследуемого фактора. В нашем случае коэффициент детерминации для рассеяния, вызываемого фактором В, достигает 92%, что связано с превалирующим влиянием размещения магазинов на колебания объемов продаж.
Задание для самостоятельной работы
Имеются данные о ценах на различные товары в различных магазинах в разные периоды. Сгруппировать товары провести однофакторный дисперсионный анализ средствами Excel и Mathcad.

