 2018-02-14
2018-02-14 1074
1074Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели. Она включает в себя два круга вопросов: отбор факторов и выбор вида уравнения регрессии.
Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям.
1. Они должны быть количественно измеримы. Факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
3. Включаемые факторы не должны коррелировать друг с другом. Наибольшие трудности в использовании аппарата множественной регрессии возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т. е. имеет место совокупное воздействие факторов друг на друга.
Наличие мультиколлинеарности между признаками приводит к:
· Искажению величины параметров модели, которые имеют тенденцию к завышению;
· Изменению смысла экономической интерпретации коэффициентов регрессии;
· Слабые обусловленности системы нормальных равнений;
· Осложнению процесса определения наиболее существенных факторных признаков.
В решении проблемы мультиколлинеарности моно выделить несколько этапов:
· Установление наличия мультиколлинеарности;
· Определение причин возникновения мультиколлинеарности;
· Разработка мер по её устранению.
Причинами возникновения мультиколлинеарности между призанками являются:
· Изучаемые факторные признаки, характеризующие одну и ту же сторону явления или процесса. Например, показатели объема производимой продукции и среднегодовой стоимости основных фондов одновременно включать в модель не рекомендуется, так как они оба характеризуют размер предприятия;
· Использование в качестве факторных признаков показателей, суммарное значение которых представляет собой постоянную величину;
· Факторные признаки, являющиеся составными элементами друг друга;
· Факторные признаки, по экономическому смыслу дублирующие друг друга.
Одним из индикаторов определения наличия мультиколлинеарности между признаками является превышение парным коэффициентом корреляции величины 0,8 (rxi xj) и др.
Отбор факторов, включаемых в регрессию, является одним из важнейших этапов практического использования методов регрессии. Подходы к отбору факторов на основе показателей корреляции могут быть разные. Они приводят построение уравнения множественной регрессии соответственно к разным методикам. В зависимости от того, какая методика построения уравнения регрессии принята, меняется алгоритм ее решения на ЭВМ.
Наиболее широкое применение получили следующие методы построения уравнения множественной регрессии:
• метод исключения;
• метод включения;
• шаговый регрессионный анализ.
Каждый из этих методов по-своему решает проблему отбора факторов, давая в целом близкие результаты — отсев факторов из полного его набора (метод исключения), дополнительное введение фактора (метод включения), исключение ранее введенного фактора (шаговый регрессионный анализ).
Практика построения многофакторных моделей взаимосвязи показывает, что все реально существующие зависимости между социально экономическими явлениями можно описать используя пять типов моделей:
1) Линейная: 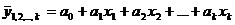
2) Степенная 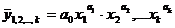
3) Показательная 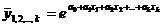
4) Параболическая 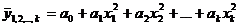
5) Гиперболическая 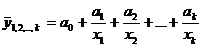
Наиболее приемлемым способом определения вида исходного уравнения регрессии является метод перебора различных уравнений.
Основное значение имеют линейные модели в силу простоты и логичности их экономической интерпретации. Нелинейные формы зависимости приводятся к линейным путем линеаризации. В линейной множественной регрессии 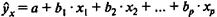 параметры при xназываются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
параметры при xназываются коэффициентами «чистой» регрессии. Они характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизмененном значении других факторов, закрепленных на среднем уровне.
Параметры уравнения множественной регрессии оцениваются, как и в парной регрессии, методом наименьших квадратов (МНК). При его применении строится система нормальных уравнений, решение которой и позволяет получить оценки параметров регрессии.
Уравнение множественной регрессии можно построить в естественном и стандартизированном виде.
А) Построение уравнения в естественном виде. Так, для уравнения у = а + b 1 · х1 + b2 · х2 + ··· + bр · хр + ε система нормальных уравнений составит:
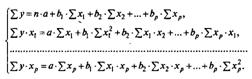
Ее решение может быть осуществлено методом определителей:
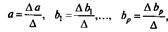
где Δ — определитель системы;
Δ а, Δ b1,..., Δ bp — частные определители.
Б) Возможен и иной подход к определению параметров множественной регрессии, когда на основе матрицы парных коэффициентов корреляции строится уравнение регрессии в стандартизованном масштабе:
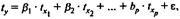
где 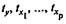 — стандартизованные переменные:
— стандартизованные переменные: 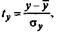
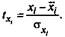
для которых среднее значение равно нулю:
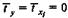
а среднее квадратическое отклонение равно единице:
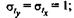 β -стандартизованные коэффициенты регрессии.
β -стандартизованные коэффициенты регрессии.
Применяя МНК к уравнению множественной регрессии в стандартизованном масштабе, после соответствующих преобразований получим систему нормальных уравнений вида
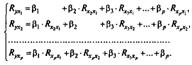
Решая ее методом определителей, найдем параметры — стандартизованные коэффициенты регрессии (β -коэффициенты).
Стандартизованные коэффициенты регрессии показывают, на сколько сигм изменится в среднем результат, если соответствующий фактор x j, изменится на одну сигму при неизменном среднем уровне других факторов. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат.
От уравнения в стандартизированном виде можно перейти к уравнению в естественной форме. Так, переход для двухфакторного уравнения множественной регрессии можно записать следующим образом:
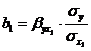
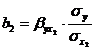
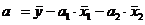
Практическая значимость уравнения множественной регрессии оценивается с помощью показателя множественной корреляции и его квадрата - коэффициента детерминации.
Показатель множественной корреляции характеризует тесноту связи рассматриваемого набора факторов с исследуемым признаком, или, иначе, оценивает тесноту совместного влияния факторов на результат.
Независимо от формы связи показатель множественной корреляции может быть найден как индекс множественной корреляции:
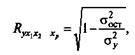
где σ2 у — общая дисперсия результативного признака;
σ2 ост - остаточная дисперсия для уравнения y =f(x1, x 2,..., x p).
При линейной зависимости признаков формула индекса корреляции может быть представлена следующим выражением:
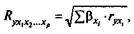
где βxi - стандартизованные коэффициенты регрессии;
r уxi -парные коэффициенты корреляции результата с каждым фактором.
Скорректированный индекс множественной корреляции содержит поправку на число степеней свободы, а именно остаточная сумма квадратов 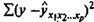 делится на число степеней свободы остаточной вариации (n - т - 1), а общая сумма квадратов отклонений
делится на число степеней свободы остаточной вариации (n - т - 1), а общая сумма квадратов отклонений 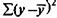 - на число степеней свободы в целом по совокупности (n - 1).
- на число степеней свободы в целом по совокупности (n - 1).
Формула скорректированного индекса множественной детерминации имеет вид:
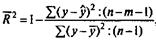
где т - число параметров при переменных х;
n - число наблюдений.
Поскольку 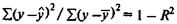 , то величину скорректированного индекса детерминации можно представить в виде
, то величину скорректированного индекса детерминации можно представить в виде
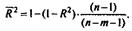
Чем больше величина m, тем сильнее различия 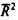 и R2.
и R2.
Парные коэффициенты корреляции. Для измерения тесноты связи между двумя из рассматриваемых переменных(без учета их взаимодействия с другими переменными) применяются парные коэффициенты корреляции. Методика расчета таких коэффициентов и их интерпретации аналогичны линейному коэффициенту корреляции в случае однофакторной связи.
Частные коэффициенты корреляции. Однако в реальных условиях все переменные, как правило, взаимосвязаны. Теснота этой связи определяется частными коэффициентами корреляции, которые характеризуют степень влияния одного из аргументов на функцию при условии, что остальные независимые переменные закреплены на постоянном уровне.
Значимость уравнения множественной регрессии в целом, так же как и в парной регрессии, оценивается с помощью F-критерия Фишера:
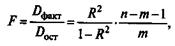
где D факт - факторная сумма квадратов на одну степень свободы;
D ост - остаточная сумма квадратов на одну степень свободы;
R2- коэффициент (индекс) множественной детерминации;
т - число параметров при переменных x (в линейной регрессии совпадает с числом включенных в модель факторов);
n- число наблюдений.
Оценивается значимость не только уравнения в целом, но и фактора, дополнительно включенного в регрессионную модель. Частный F-критерий построен на сравнении прироста факторной дисперсии, обусловленного влиянием дополнительно включенного фактора, с остаточной дисперсией на одну степень свободы по регрессионной модели в целом. Предположим, что оцениваем значимость влияния x1 как дополнительно включенного в модель фактора. Используем следующую формулу:
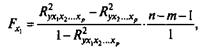
где R2 yx1x2...xp - коэффициент множественной детерминации для модели с полным набором факторов;
R2yx2....xp ~ тот же показатель, но без включения в модель фактора x1;
n- число наблюдений;
т - число параметров в модели (без свободного члена).
Фактическое значение частного F-критерия сравнивается с табличным при 5%-ном или 1%-ном уровне значимости и числе степеней свободы: 1 и n— т — 1. Если фактическое значение Fxj. превышает 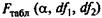 , то дополнительное включение фактора xj в модель статистически оправданно и коэффициент чистой регрессии b i при факторе xi - статистически значим. Если же фактическое значение Fxj меньше табличного, то дополнительное включение в модель фактора х, не увеличивает существенно долю объясненной вариации признака у, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
, то дополнительное включение фактора xj в модель статистически оправданно и коэффициент чистой регрессии b i при факторе xi - статистически значим. Если же фактическое значение Fxj меньше табличного, то дополнительное включение в модель фактора х, не увеличивает существенно долю объясненной вариации признака у, следовательно, нецелесообразно его включение в модель; коэффициент регрессии при данном факторе в этом случае статистически незначим.
С помощью частного F-критерия можно проверить значимость всех коэффициентов регрессии в предположении, что каждый соответствующий фактор xi - вводился в уравнение множественной регрессии последним.
Оценка значимости коэффициентов чистой регрессии по t-критерию Стьюдента может быть проведена и без расчета частных F-критериев. В этом случае, как и в парной регрессии, для каждого фактора используется формула
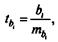
где b1 — коэффициент чистой регрессии при факторе xj;
тbi — средняя квадратическая ошибка коэффициента регрессии bi
Для уравнения множественной регрессии 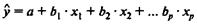 средняя квадратическая ошибка коэффициента регрессии может быть определена по следующей формуле:
средняя квадратическая ошибка коэффициента регрессии может быть определена по следующей формуле:
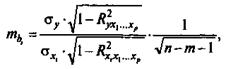
где σу - среднее квадратическое отклонение для признака у;
σxi - среднее квадратическое отклонение для признака xi;
R2 yx1...xp - коэффициент детерминации для уравнения множественной регрессии;
R2 xix1...xp- коэффициент детерминации для зависимости фактора xt со всеми другими факторами уравнения множественной регрессии;
n - т - 1 - число степеней свободы для остаточной суммы квадратов отклонений.
До сих пор в качестве факторов рассматривались экономические переменные, принимающие количественные значения в некотором интервале. Вместе с тем может оказаться необходимым включить в модель фактор, имеющий два или более качественных уровней. Чтобы ввести такие переменные в регрессионную модель, им должны быть присвоены те или иные цифровые метки, т. е. качественные переменные преобразованы в количественные. Такого вида сконструированные переменные в эконометрике принято называть фиктивными переменными. В отечественной литературе можно встретить термин «структурные переменные».
При оценке параметров уравнения регрессии применяется метод наименьших квадратов (МНК). При этом делаются определенные предпосылки относительно случайной составляющей ε.
В модели
y=а+b1∙x1+b2∙x2+…+bp∙xp+ε
случайная составляющая ε представляет собой ненаблюдаемую величину. После того как произведена оценка параметров модели, рассчитывая разности фактических и теоретических значений результативного признака у, можно определить оценки случайной составляющей y — 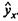 . Поскольку они не есть реальные случайные остатки, их можно считать некоторой выборочной реализацией неизвестного остатка заданного уравнения, т. е. εj.
. Поскольку они не есть реальные случайные остатки, их можно считать некоторой выборочной реализацией неизвестного остатка заданного уравнения, т. е. εj.
При изменении спецификации модели, добавлении в нее новых наблюдений выборочные оценки остатков εj могут меняться. Поэтому в задачу регрессионного анализа входит не только построение самой модели, но и исследование случайных отклонений εj, т. е. остаточных величин.
Коэффициенты регрессии, найденные исходя из системы нормальных уравнений, представляют собой выборочные оценки характеристики силы связи. Их несмещенность является желательным свойством, так как только в этом случае они могут иметь практическую значимость. Несмещенность оценки означает, что математическое ожидание остатков равно нулю. Следовательно, при большом числе выборочных оцениваний остатки не будут накапливаться и найденный параметр регрессии bi можно рассматривать как среднее значение из возможного большого количества несмещенных оценок. Если оценки обладают свойством несмещенности, то их можно сравнивать по разным исследованиям.
Для практических целей важна не только несмещенность, но и эффективность оценок. Оценки считаются эффективными, если они характеризуются наименьшей дисперсией. Поэтому несмещенность оценки должна дополняться минимальной дисперсией. В практических исследованиях это означает возможность перехода от точечного оценивания к интервальному.
Степень реалистичности доверительных интервалов параметров регрессии обеспечивается, если оценки будут не только несмещенными и эффективными, но и состоятельными. Состоятельность оценок характеризует увеличение их точности с увеличением объема выборки. Большой практический интерес представляют те результаты регрессии, для которых доверительный интервал ожидаемого значения параметра регрессии bi имеет предел значений вероятности, равный единице. Иными словами, вероятность получения оценки на заданном расстоянии от истинного значения параметра близка к единице.
Указанные критерии оценок (несмещенность, состоятельность, эффективность) обязательно учитываются при разных способах оценивания. Метод наименьших квадратов строит оценки регрессии на основе минимизации суммы квадратов остатков. Поэтому очень важно исследовать поведение остаточных величин регрессии ε i. Условия, необходимые для получения несмещенных, состоятельных и эффективных оценок, представляют собой предпосылки МНК, соблюдение которых желательно для получения достоверных результатов регрессии.
Исследования остатков εi - предполагают проверку наличия следующих пяти предпосылок МНК:
• случайный характер остатков;
• нулевая средняя величина остатков, не зависящая от хi;
• гомоскедастичность — дисперсия каждого отклонения ε i
одинакова для всех значений х;
• отсутствие автокорреляции остатков. Значения остатков ε i
распределены независимо друг от друга;
• остатки подчиняются нормальному распределению.
В тех случаях, когда все пять предпосылок выполняются, оценки, полученные по МНК и по методу максимального правдоподобия, совпадают между собой. Если распределение случайных остатков ε i не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
Прежде всего проверяется случайный характер остатков ε i -первая предпосылка МНК.
С этой целью стоится график зависимости остатков ε i - от теоретических значений результативного признака (рис.).
Рис. Зависимость случайных остатков ε i от теоретических значений 
|
|
Если на графике получена горизонтальная полоса, то остатки ε i представляют собой случайные
В этих случаях необходимо либо применять другую функцию, либо вводить дополнительную информацию и заново строить уравнение регрессии до тех пор, пока остатки ε i не будут случайными величинами.
Вторая предпосылка ΜΗΚ относительно нулевой средней величины остатков означает, что 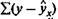 = 0. Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. Для моделей, нелинейных по оцениваемым параметрам и приводимых к линейному виду логарифмированием, средняя ошибка равна нулю для логарифмов исходных данных.
= 0. Это выполнимо для линейных моделей и моделей, нелинейных относительно включаемых переменных. Для моделей, нелинейных по оцениваемым параметрам и приводимых к линейному виду логарифмированием, средняя ошибка равна нулю для логарифмов исходных данных.
Если остатки на графике расположены в виде горизонтальной полосы, то они независимы от значений xj. Если же график показывает наличие зависимости ε i и хj, то модель неадекватна. Корреляция случайных остатков с факторными признаками позволяет проводить корректировку модели, в частности использовать кусочно-линейные модели.
Предпосылка о нормальном распределении остатков позволяет проводить проверку параметров регрессии и корреляции с помощью критериев t, F. Вместе с тем оценки регрессии, найденные с применением МНК, обладают хорошими свойствами даже при отсутствии нормального распределения остатков, т. е. при нарушении пятой предпосылки МНК.
Совершенно необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение третьей и четвертой предпосылок.
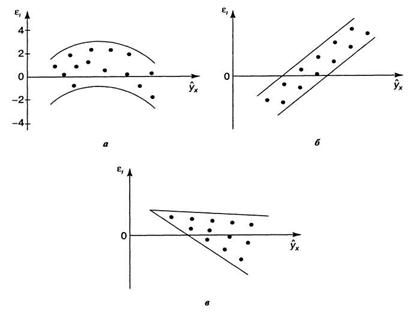
В соответствии с третьей предпосылкой МНК требуется, чтобы дисперсия остатков была гомоскедастичной. Это значит, что для каждого значения фактора хj остатки ε i имеют одинаковую дисперсию. Если это условие применения МНК не соблюдается, то имеет место гетероскедастичность. Наличие гетероскедастичности можно наглядно видеть из поля корреляции.
Рис. Примеры гетероскедастичности:
а — дисперсия остатков растет по мере увеличения х;
б — дисперсия остатков достигает максимальной величины при средних
значениях переменной xи уменьшается при минимальных
и максимальных значениях х;
в — максимальная дисперсия остатков при
малых значениях xи дисперсия остатков однородна
по мере увеличения значений x
Гомоскедастичность остатков означает, что дисперсия остатков ε i одинакова для каждого значения х. Используя трехмерное изображение, получим следующие графики, иллюстрирующие гомо - и гетероскедастичность.
 Рис.Гомоскедастичность остатков Рис.Гомоскедастичность остатков | 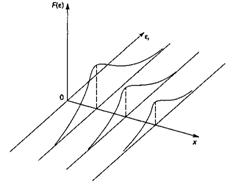 Рис. Гетероскедастичность остатков Рис. Гетероскедастичность остатков |
Наличие гомоскедастичности или гетероскедастичности можно видеть и по рассмотренному выше графику зависимости остатков ε i от теоретических значений результативного признака 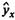 .
.
Наличие гетероскедастичности может в отдельных случаях привести к смещенности оценок коэффициентов регрессии, хотя несмещенность оценок коэффициентов регрессии в основном зависит от соблюдения второй предпосылки МНК, т. е. независимости остатков и величин факторов. Гетероскедастичность будет сказываться на уменьшении эффективности оценок bi.
При малом объеме выборки, что наиболее характерно для эконометрических исследований, для оценки гетероскедастичности может использоваться метод Гольдфельда — Квандта, разработанный в 1965 г. Гольдфельд и Квандт рассмотрели однофакторную линейную модель, для которой дисперсия остатков возрастает пропорционально квадрату фактора. Чтобы оценить нарушение гомоскедастичности, они предложили параметрический тест, который включает в себя следующие шаги.
1. Упорядочение n наблюдений по мере возрастания переменной х.
2. Исключение из рассмотрения С центральных наблюдений; при этом (n — С): 2 > p, где p— число оцениваемых параметров.
3. Разделение совокупности из (n - С) наблюдений на две группы (соответственно с малыми и большими значениями фактора х) и определение по каждой из групп уравнений регрессии.
4. Определение остаточной суммы квадратов для первой (S1) и второй (S2) групп и нахождение их отношения: R = S1: S2 .
При выполнении нулевой гипотезы о гомоскедастичности отношение R будет удовлетворять F-критерию с (n - С - 2р): 2 степенями свободы для каждой остаточной суммы квадратов. Чем больше величина R превышает табличное значение F-критерия, тем более нарушена предпосылка о равенстве дисперсий остаточных величин.
При несоблюдении основных предпосылок МНК приходится корректировать модель, изменяя ее спецификацию, добавлять (исключать) некоторые факторы, преобразовывать исходные данные для того, чтобы получить оценки коэффициентов регрессии, которые обладают свойством несмещенности, имеют меньшее значение дисперсии остатков и обеспечивают в связи с этим более эффективную статистическую проверку значимости параметров регрессии. Этой цели, как уже указывалось, служит и применение обобщенного метода наименьших квадратов.

