 2020-01-14
2020-01-14 135
135
Задача 3.1
Известно, что каноническая форма порождающей матрицы линейного (n,k)-кода имеет следующую структуру: G(n,k) = (I k | Dk, n-k), где I k - единичная матрица размерности k, а D - блок «дополнений» размерности k´(n–k), каждая строка которого имеет вес w(D i)≥ d0–1).

По заданной порождающей матрице (15,11)-кода с минимальным расстоянием d0 = 3, приведенной в шестнадцатеричном формате справа, напишите проверочную матрицу H(15,11), с помощью которой составьте список синдромов однократных ошибок в слове.
Напишите проверочную матрицу для укороченного (14,10)-кода.
Задача 3.2
В некоторой системе необходимо передавать до 12 сообщений. С целью обеспечения помехоустойчивости необходимо представить сообщения словами линейного (n, k)-кода, обеспечивающего вероятность безошибочной передачи сообщения (слова) не хуже, чем 0,9995, при том, что сигналы передаются по двоичному симметричному каналу с независимыми ошибками, вероятность происхождения которых Р0–1=Р1–0=РБ=10–4.
Требуется:
1) определить параметры слова избыточного (n, k)-кода;
2) написать порождающую G(n,k) и проверочную H(n,k) матрицы кода (в канонической форме);
3) изложить в графической или текстовой форме алгоритм работы декодера;
4) вычислить вероятности:
- предъявления получателю неискаженного сообщения (слова);
- предъявления получателю сообщения с незамеченными ошибками;
5)определить выигрыш в помехоустойчивости по сравнению с неизбыточным кодом:
- по вероятности получения неискаженного сообщения;
- по вероятности получения сообщения с незамеченными ошибками.
Задача 3.3
Напишите порождающую матрицу линейного (7,4)-кода с минимальным расстоянием d0=3. На ее основе получите матрицу укороченного (5,2)-кода. Напишите полный список кодовых слов, определите минимальное кодовое расстояние.
На основе той же исходной матрицы (7,4)-кода получите порождающую матрицу для расширенного (8,4)-кода с минимальным расстоянием d0 = 4.
Задача 3.4
Первичный преобразователь (датчик) технологического параметра измеряет уровень жидкости в некотором резервуаре. Результат измерения уровня («отсчет») отображается словом неизбыточного двоичного кода на все сочетания. Уровень жидкости меняется в пределах от 0 до 100 мм. Статическая погрешность измерения не превосходит ±1мм.
Для передачи сигналов используется двоичный симметричный канал без стирания и памяти. Вероятность ложного опознавания одного бита РБ=5*10–4.
Определите:
1) число состояний источника информации и минимальную длину слова неизбыточного кода;
2) вероятность получения сообщения с незамеченными ошибками («подмена сообщения»);
3) параметры избыточного линейного (n,k) - кода, обеспечивающего вероятность получения сообщения с незамеченными ошибками не хуже 10–6;
4) выигрыш в помехоустойчивости по отношению к неизбыточному коду, оцениваемый по вероятности «подмены сообщения», о которой шла речь в п.2;
5) проигрыш в скорости передачи сигналов по отношению к неизбыточному кодированию («относительную скорость» избыточного (n,k)-кода).
Задача 3.5
Первичный преобразователь технологического параметра представляет каждый отсчет измеряемого параметра (сообщение) трехразрядным десятичным числом в диапазоне от 00,0 до 99,9. Каждая десятичная цифра кодируется, в свою очередь, двоичным кодом с четным весом.
Информация передается по двоичному симметричному каналу без стирания и памяти, у которого вероятность искажения одного бита равна 10–4. Декодер канала декодирует слова с четным весом, обнаруживая ошибки.
Определите:
1) вероятность предъявления получателю безошибочного сообщения;
2) вероятность предъявления получателю ошибочного сообщения из-за незамеченных ошибок в сигнале.
Задача 3.6
Первичный преобразователь, как и в предыдущей задаче, каждое сообщение (отсчет) отображает последовательностью из трех десятичных цифр. Каждая десятичная цифра представлена словом, принадлежащим коду с постоянным весом.
Канал передачи элементарных сигналов - асимметричный, без памяти и стирания. Вероятность ложного опознавания «1» Р1–0=0,5*10–3, а ложного опознавания «0» Р0–1=2*10–3.
Требуется:
1) вычислить минимальную длину кодового слова. Если есть варианты, назначить (выбрать) значение веса слов;
2) вычислить вероятность предъявления получателю неискаженного сообщения;
3) вероятность предъявления получателю сообщения с незамеченными ошибками;
4) вычислить аналогичную вероятность при кодировании десятичной цифры неизбыточным кодом со словами длиной в четыре бита;
5) выигрыш в помехоустойчивости, оцениваемый по вероятности незамеченных ошибок, обеспечиваемый предлагаемым кодом с постоянным весом;
6) проигрыш в скорости передачи сообщений по сравнению с кодированием по п.4).
Упражнение 3.7
Напишите список слов (4,3)-циклического кода, заданного порождающим многочленом g(x) = x+1. Определите минимальное расстояние d0 данного кода.
Требуется:
1) построить на основе регистров сдвига структурную схему декодера, обнаруживающего ошибки в кодовых словах;
2) в рамках ограничений выбранной вами серии ТТЛ-схем построить функциональную схему декодера, включая реализацию ключей, управляющих работой регистров;
3) можно ли предложить циклический код с такой же длиной информационного блока (к=3) и таким же расстоянием d0, но с большей относительной скоростью?
Упражнение 3.8
Охарактеризуйте всевозможные конфигурации векторов ошибок, которые позволяет обнаруживать (7,4)-циклический код, образованный порождающим многочленом g(x) = x3+x+1 и имеющий минимальное расстояние d0=3.
Поясните, какие из перечисленных ошибок могут не обнаруживаться (7,4)-нециклическим кодом с тем же расстоянием. Приведите конкретные примеры таких ошибок.
Упражнение 3.9
На основе регистров сдвига постройте структурную схему декодера с исправлением однократных ошибок для укороченного (15,11)-циклического кода с минимальным расстоянием d0=3 и образующим многочленом g(x) = x4+x+1.
Напишите несколько слов, принадлежащих данному коду. С их помощью проиллюстрируйте поведение декодера в условиях возникновения одно- и двукратных ошибок в кодовых словах.
Нужно ли что–нибудь изменить в схеме декодера с тем, чтобы он декодировал слова укороченного (14,10)-кода?
Рекомендации по решению задач РАЗДЕЛА 3
Задачи 3.1, 3.2, 3.3 преследуют цель дать некоторый тренаж в манипулировании с каноническими формами матриц G(n,k) и H(n,k).
Напомним, что в принципе роль порождающей матрицы G может выполнять любая совокупность из k линейно-независимых векторов длины n, попарные расстояния среди которых не меньше d0. Каноническая форма матрицы предполагает определенную технологию ее формирования. Матрица G представляет собой блочную структуру типа
G(n,k) = (I k | D k, n-k), (3.1)
где I k - единичная матрица размерности k;
D - блок дополнений размерности k*(n–k), каждая строка D i которого имеет вес w(Di)³(d0–1).
Проверочная матрица Н по определению ортогональна к G и структурно представляет собой
H(n,k) = (Dт | I n–k), (3.2)
где Dт - транспортированный блок D размерности kЧ(n–k);
In–k - единичная матрица размерности n–k.
Следствием ортогональности является
V*HТ = S = 0 (3.3)
- фундаментальное соотношение, лежащее в основе процедуры декодирования по синдрому S линейных (n,k)-кодов. Вектор V принадлежит коду G.
Матричная форма описания линейных кодов позволяет легко получить так называемые «укороченные коды» (задачи 3.1, 3.3). Укороченный (n–z,k–z) - код может быть получен из (n,k) - кода, если в канонической матрице G(n,k) вычеркнуть z строк сверху и z столбцов слева. В отношении помехоустойчивости такой код обладает свойствами неукороченного кода.
В задачах 3.7, 3.8, 3.9 обсуждаются циклические (n,k) - коды, получившие в практике передачи кодированных сигналов наибольшее распространение, благодаря прекрасным свойствам в отношении обнаружения ошибок и удивительно простой схемотехнике декодирующих устройств. В [1], [2 ], [3 ] приведены примеры построения структурных и функциональных схем кодирующих и декодирующих устройств.
В задачах 3.2, 3.4, 3.5, 3.6 требуется вычислять вероятности различных событий, связанных с возникновением в кодовом слове ошибок различных конфигураций. Построение формул для вычисления вероятностей можно освоить, например, с помощью [3]. Для этого только необходимо возобновить в памяти теоремы о сумме и произведении вероятностей для совместного наступления независимых событий, а также всякий раз четко формулировать суть события, вероятность наступления которого вычисляется.
С точки зрения инженерной практики наиболее правдоподобны задачи 3.2 и 3.4. Для данного источника предложить кодирование, помехоустойчивость которого удовлетворяет наперед заданным требованиям. В задаче 3.2 требуется, чтобы вероятность предъявления получателю неискаженной информации РНИ была не менее допустимого значения РНИ.ДОП. Исходим из того, что каждое сообщение отображается одним кодовым словом, а каждое слово передается однократно. Проделаем следующее:
1) закодируем источник неизбыточным кодом, определим k - длину неизбыточного слова;
2) проверим соотношение РНИ.НЕИЗБ = РНИ.ДОП. Скорее всего окажется, что РНИ.НЕИЗБ <Р НИ.ДОП. Если это не так, то неизбыточное кодирование решает задачу;
3) если вероятность предъявления получателю неискаженного сообщения меньше допустимого значения, то мы должны заключить, что понадобится код с исправлением ошибок в слове, так как при неизменном качестве двоичного канала РБ при однократной передаче слова других путей повышения этой вероятности нет;
4) определим максимальную кратность ошибки t, которая должна исправляться. Это легко сделать, если иметь в виду, что в обсуждаемом двоичном канале вероятность возникновения однократной ошибки равна
Cn1*PБ*(1–PБ)n–1; (3.4)
5) знание (или предложение) максимальной кратности исправляемой ошибки дает нам знание максимального расстояния кода, так как необходимо, чтобы d0=2t+1. Имеется в виду, что неравенство имеет минимальную глубину;
6) после этого можно вычислить число контрольных символов в кодовом слове, воспользовавшись известным теоретическим результатом (граница Хэмминга).
2(n–k) ³Cn0 + Cn1 +...+ Cnt. (3.5)
Здесь Cni - биномиальный коэффициент.
Убедимся, что с учетом исправления ошибок кратности t и меньше вероятность РНИ.³РНИ.ДОП.
Задача 3.4 решается вполне аналогично. Необходимо только иметь в виду, что здесь для уменьшения вероятности предъявления получателю сообщения с незамеченной ошибкой РОШ. мы заинтересованы в повышении кратности r обнаруживаемых ошибок. Исправление ошибок эту вероятность не уменьшит. Для обнаружения ошибок кратности r и меньше понадобится (n,k) - код с расстоянием d0³(r+1). Быть может, требованиям задачи удовлетворяет код с расстоянием d0=2 (с четным весом). Если это не так, можно для определения числа контрольных символов (n–k) воспользоваться выражением (3.5).
Наконец, рассмотрим еще решение задачи 3.6, так как она отличается от всех других двумя факторами:
1. Здесь сообщение («отсчет» измеряемой аналоговой величины) отображается не одним кодовым словом, а последовательностью (массивом) из трех слов.
2. Для передачи кодовых слов используется асимметричный двоичный канал, в котором Р1–0 ¹Р0–1.
На рис.3.1 представлены диаграммы сигналов для данного случая. Каждый отсчет измеряемой величины представлен в двоичном канале как последовательность трех десятичных цифр, каждая из которых, в свою очередь, отображается словом кода с постоянным весом, например, кодом «2 из 5». Ниже приведен вариант такого отображения.
0 – 11000 2 – 10010 4 – 01100 6 – 01001 8 – 00101
1 – 10100 3 – 10001 5 – 01010 7 – 00110 9 – 00011
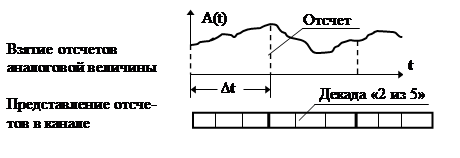
Рис. 3.1. Диаграмма сигналов к задаче 3.6
Требуется вычислить:
РНИ - вероятность предъявления получателю неискаженного отсчета (сообщения).
РОШ - вероятность предъявления отсчета с незамеченной ошибкой.
По-видимому, следует начать с нахождения аналогичных вероятностей для одной декады.
По условию задачи вероятности ложного опознавания бит Р1–0, и Р0–1 являются константами, которые не зависят от времени, от размещения бит в кодовом слове. Следовательно, для нахождения вероятности можно оперировать некоторым «стандартным форматом», каким является, например, отображение цифры 0 или 9. Здесь компактно расположены w символов «1» и (n – w) символов «0». Тогда:
1. По теореме о вероятности совместного наступления независимых событий вероятность получения неискаженной декады
РНИ.ДЕК. = (Р1–1)w*(P0–0)n-w, (3.6)
где Р1–1, Р0–0 - вероятности правильного опознавания соответственно символов «1» и «0».
2. Видно, что ошибки в кодовом слове не будут замечены, если совместно будет неправильно опознано одинаковое количество символов «1» и «0». Вероятность получения декады с незамеченной ошибкой может быть представлена как
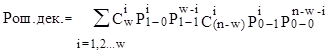 . (3.7)
. (3.7)
3. Отсчет имеет смысл неискаженного сообщения, если все три декады не искажены. Вероятность такого события
РНИ. = (РНИ.ДЕК.)3. (3.8)
4. Отсчет не имеет ценности для получателя, если хотя бы в одной декаде содержится незамеченная ошибка
Pош=åС3j*P jош.дек.*(Pни дек.)3– j. (3.9)
j=1,2,3








