 2020-01-14
2020-01-14 405
405
Прежде чем приступать к работе с базой данных, в первую очередь необходимо выбрать модель представления данных. Она должна отвечать следующим требованиям:
· Наглядность представления информации;
· Простота ввода информации;
· Удобство поиска и отбора информации;
· Возможность использования информации, введенной в другую базу;
· Возможность быстрой перенастройки базы данных (добавление новых полей, новых записей, их удаление).
При разработке БД можно выделить следующие этапы работы.
I этап. Постановка проблемы
На этом этапе формируется задание по созданию БД. В нем подробно описывается состав базы, назначение и цели ее создания, а также перечисляется, какие виды работ предполагается осуществлять в этой базе данных (отбор, дополнение, изменение данных, печать или вывод отчета и т.д.).
II этап. Анализ объекта
На этом этапе необходимо рассмотреть, из каких объектов может состоять ваша БД, каковы свойства этих объектов. После разбиения БД на отдельные объекты необходимо рассмотреть свойства каждого из этих объектов, другими словами, установить, какими параметрами описывается каждый объект. Все эти сведения можно располагать в виде отдельных записей и таблиц. Далее необходимо рассмотреть тип данных каждой отдельной единицы записи (текстовый, числовой и т.д.). Сведения о типах данных также следует занести в составляемую таблицу.
III этап. Синтез модели
На этом этапе по проведенному выше анализу необходимо выбрать определенную модель БД. Далее рассматриваются достоинства и недостатки каждой модели, сопоставить их с требованиями и задачами вашей БД и выбрать ту модель, которая сможет максимально обеспечить реализацию поставленной задачи. После выбора модели необходимо нарисовать ее схему с указанием связей между таблицами или узлами.
IV этап. Способы представления информации, программный инструментарий
После создания модели необходимо, в зависимости от выбранного программного продукта, определить форму представления информации. В большинстве СУБД данные можно хранить в двух видах:
· С использованием форм;
· Без использования форм.
Форма – созданный пользователем графический интерфейс для ввода данных в базу.
V этап. Синтез компьютерной модели объекта и технология его создания
После рассмотрения инструментальных возможностей выбранного программного продукта можно приступить к реализации БД на компьютере. В процессе создания компьютерной модели можно выделить некоторые стадии, типичные для любой СУБД.
Стадия 1. Запуск СУБД, создание нового файла базы данных или открытие созданной ранее базы
В процессе выполнения данной стадии необходимо запустить СУБД, создать новый файл (новую базу) или открыть существующую.
Стадия 2. Создание исходной таблицы или таблиц.
Создавая исходную таблицу, необходимо указать имя и тип каждого поля. Имена полей не должны повторяться внутри одной таблицы. В процессе работы с БД можно дополнять таблицу новыми полями. Созданную таблицу необходимо сохранить, дав ей имя, уникальное в пределах создаваемой базы.
Стадия 3. Создание экранных форм.
Первоначально необходимо указать таблицу, на базе которой будет создаваться форма. Ее можно создавать при помощи Мастера форм или самостоятельно, указав, какой вид она должна иметь (например, в виде столбца или таблицы). При создании формы можно указывать не все поля, которые содержит таблица, а только некоторые из них. Имя формы может совпадать с именем таблицы, на базе которой она создана. На основе одной таблицы можно создать несколько форм, которые могут отличаться видом или количеством используемых из данной таблицы полей. После создания форму необходимо сохранить. Созданную форму можно редактировать, изменяя местоположение, размеры и формат полей.
Стадия 4. Заполнение БД.
Процесс заполнения БД может проводиться в двух видах: в виде таблицы и в виде формы. Числовые и текстовые поля можно заполнять в виде таблицы, а поля типа МЕМО и OLE – в виде формы.
VI этап. Работа с созданной базой данных
Работа с БД включает в себя такие действия, как:
· Поиск необходимых сведений;
· Сортировка данных;
· Отбор данных;
· Вывод на печать;
· Изменение и дополнение данных.
Рассмотрим все этапы создания и принципы работы с базами данных на примере СУБД Microsoft Access.
2.1 Методы проектирования реляционной БД
Когда перечень атрибутов составлен, очередная задача состоит в их агрегации, то есть компоновке атрибутов в объекты. Это и есть суть процесса проектирования реляционной базы данных.
Существует несколько подходов к проектированию РБД.
1) Декомпозиция (для небольших БД);
2) Синтез;
3) Использование модели объекта связи (метод ER-диаграмм).
2.1.1 Метод декомпозиции
Характеризуется тем, что сначала создается одно УО, которое затем разбивается на ряд отношений, находящихся в НФ. Использование таблицы кажется на первый взгляд удобным, на самом деле при работе с такой таблицей возникают аномалии обновления.
Возможный ключ — представляет собой атрибут или набор атрибутов, который может быть использован для данного отношения в качестве первичного ключа.
Детерминант — если А=>В — ФЗ и В не зависит функционально от любого подмножества А, то говорят, что А представляет собой детерминант В.
Большинство потенциальных аномалий в БД будет устранено при декомпозиции любого отношения в НФБК.
Отношение находится в НФБК, если и только если каждый детерминант отношения является возможным ключом.
Пример:
1. Функциональные зависимости:

2. Диаграмма ФЗ:
Из диаграммы видно, что УО на находится ни в 2НФ, ни в 3НФ.

Расположим рядом перечень всех детерминантов и всех возможных ключей.
| Возможный ключ | Детерминант |
| 1. Таб№, Имя_Р | Таб№, Имя_Р, ФИО Отдел Таб№ Телефон |
Поскольку не каждый детерминант в данном отношении является возможным ключом, следовательно, отношение "сотрудник" не находится в НФБК и его нужно подвергнуть декомпозиции.
Общий подход декомпозиции заключается в следующих шагах:
1) Разработка универсального отношения БД; для построенного УО находится первичный ключ.
2) Определение всех ФЗ между атрибутами отношения;
3) Определение того, находится ли отношение в НФБК, если да, то проектирование завершается, если нет, то отношение должно быть разбито на два.
4) Повторение шагов 2) и 3) для каждого нового отношения, построенного в результате декомпозиции.
Разбиение отношения на два отношения на шаге 2) осуществляется по следующему правилу.
Пусть отношение  не находится в НФБК. Определяется ФЗ, например,
не находится в НФБК. Определяется ФЗ, например,  , которое является причиной того, что r не находится в НФБК, т.е. С является детерминантом но не является возможным ключом.
, которое является причиной того, что r не находится в НФБК, т.е. С является детерминантом но не является возможным ключом.
Создаются два новых отношения,  и
и  , где зависимая часть была выделена из отношения и опущена при формировании отношения r1, и полностью использована при формировании отношения r2. Теперь нужно проверить, находится ли полученное отношение в НФБК. Про отношение
, где зависимая часть была выделена из отношения и опущена при формировании отношения r1, и полностью использована при формировании отношения r2. Теперь нужно проверить, находится ли полученное отношение в НФБК. Про отношение 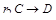 говорят, что оно является проекцией отношения r. Этот тип декомпозиции называется декомпозицией без потерь.
говорят, что оно является проекцией отношения r. Этот тип декомпозиции называется декомпозицией без потерь.
На этом же этапе должно быть принято решение, какую ФЗ выбрать для проведения первой проекции. Не исключено, что в итоге выбора той или иной I (начальной) проекции будут получены разные БД. Простым правилом выбора …  , с последующим использованием для I проекции правой зависимости (
, с последующим использованием для I проекции правой зависимости ( ). Если таких цепочек нет, то безразлично, с чего начинать.
). Если таких цепочек нет, то безразлично, с чего начинать.
Это правило можно сформулировать и так: следует избегать выбора ФЗ, правая часть которой сама (целиком или частично), является детерминантом другой ФЗ.
Отношение, получаемое в результате декомпозиции, должно удовлетворять требованиям:
1) Возможность восстановить в точности исходное отношение путем естественного соединения отношений — результатов декомпозиции;
2) Сохранение всех ФЗ исходного отношения.
Пусть в отношении r со схемой R имеется множество ФЗ. Говорят, что схема R разложима без потерь на отношения  с сохранением ФЗ, если для любого кортежа
с сохранением ФЗ, если для любого кортежа  . Кортеж может быть восстановлен
. Кортеж может быть восстановлен

соединением его проекций. Невыполнение этих требований приведет к получению набора отношений, порождающих не согласующиеся данные.
Условия разложения без потерь:
а) для разложения, состоящего из двух отношений. Если отношение R1 и R2 являются разложением с сохранением множества ФЗ, это разложение обеспечивает соединение без потерь, если  либо
либо 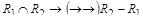 . Здесь операции " Ç " и " – " определены над списками атрибутов отношений. Это правило можно сформулировать по-другому: отсутствие потерь при декомпозиции гарантируется, если от общего атрибута двух получаемых отношений зависит хотя бы один атрибут из двух оставшихся.
. Здесь операции " Ç " и " – " определены над списками атрибутов отношений. Это правило можно сформулировать по-другому: отсутствие потерь при декомпозиции гарантируется, если от общего атрибута двух получаемых отношений зависит хотя бы один атрибут из двух оставшихся.
б) для разложения, состоящего более чем из двух отношений (метод табло). Процедура состоит в построении таблицы, строками которой являются имена, полученные при декомпозиции отношений, а столбцы — список атрибутов  этих отношений без повторений. Таблица заполняется символами
этих отношений без повторений. Таблица заполняется символами 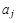 , если элемент i-й строки в j-м столбце соответствует атрибуту Aj в отношении Ri, в противном случае ничего не ставится. После заполнения таблицы следует итеративный просмотр всех ФЗ
, если элемент i-й строки в j-м столбце соответствует атрибуту Aj в отношении Ri, в противном случае ничего не ставится. После заполнения таблицы следует итеративный просмотр всех ФЗ  . Если для атрибутов из Х найдутся строки, где в соответствующих местах стоят aj, то пустые элементы этих строк, соответствующие столбцам атрибутов из Y, заменяются на aj*. Если в результате появится строка таблицы, заполненная полностью aj и aj*, то данное соединение без потерь. В противном случае — с потерями.
. Если для атрибутов из Х найдутся строки, где в соответствующих местах стоят aj, то пустые элементы этих строк, соответствующие столбцам атрибутов из Y, заменяются на aj*. Если в результате появится строка таблицы, заполненная полностью aj и aj*, то данное соединение без потерь. В противном случае — с потерями.
Метод декомпозиции применим для задач с малым числом атрибутов и отношений.
2.1.2 Метод синтеза
Отметим еще одно важное правило, лежащее в основе метода синтеза.
Все ФЗ с одинаковыми детерминантами нужно выделять в одну группу и каждой такой группе отводить свои собственные отношения. Получаемые отношения проверяются на соответствие с НФБК.
Этот прием следует применять в том случае, когда использование метода декомпозиции может привести к потере ФЗ, например, при выделении из  зависимости
зависимости  будут получены отношения
будут получены отношения  и
и  , ни одно из которых не будет содержать зависимость
, ни одно из которых не будет содержать зависимость  . В этом случае метод декомпозиции не работает.
. В этом случае метод декомпозиции не работает.
Правильно (метод синтеза):  ,
, 
Использование описанного выше правила декомпозиции может быть осложнено присутствием избыточных ФЗ (ИФЗ).
ИФЗ — зависимость, не заключающая в себе такой информации, которая не могла бы быть получена на основе других зависимостей, использованных при проектировании БД.
Поскольку ИФЗ не содержит уникальной информации, она может быть удалена из набора ФЗ. ИФЗ удаляется до начала проектирования (т.е. декомпозиции).
Возникновение ИФЗ связано с:
a) наличием транзитивных зависимостей;
b) добавлением.
Пример:
a) Исходный набор ФЗ После удаления ИФЗ

b) Эта форма избыточности имеет несколько видов:
1) Если  , то
, то  является правильной, но избыточной;
является правильной, но избыточной;
2) Если , то 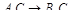 избыточна.
избыточна.
Рассмотренные ПВ ФЗ из исходных ФЗ входят в состав так называемых аксиом вывода (АВ).
АВ — правило, согласно которому, если отношение удовлетворяет определенным ФЗ, то оно должно удовлетворять и другим определенным ФЗ.
Рассмотрим 6 основных правил вывода (АВ).
1) Рефлексивность. А®А,

2) Добавление (расширение)

а) если А®В, то А,С®В
б) если АàВ, то А, С à В,С ИФЗ
3) Транзитивность. Если А®B и B®C, то А®С ИФЗ

4) Псевдотранзитивность. Если А®B и B,С®D, то А,С®D ИФЗ


5) Объединение (аддитивность). Если А®B и А®С, то А®В,С
6) Декомпозиция (проективность). Если А®В,С, то А®B и А®С

Используя аксиомы вывода f1-f6 можно получить другие правила вывода для ФЗ. Например, с использованием аксиом f1 и f2 можно получить A,B®B. Первые три аксиомы называются аксиомами Армстронга, оставшиеся три следуют из них. Использование полной системы аксиом позволяет вывести все функциональные зависимости, допустимые в множестве ФЗ. Пусть F – множество ФЗ для схемы отношений R. Множество ФЗ, которые логически следуют из F, называют замыканием F (F+). Если F=F+, то говорят, что F — полное семейство зависимости. Вычисление F+ для F являются трудоемкой задачей, поскольку мощность F+ может быть велика даже при небольшой мощности F. Вычисление же X+ для данного множества атрибутов Х не представляет трудности. Х+— это замыкание Х относительно F, если есть множество атрибутов А таких, что зависимость Х®А может быть выведена из F по аксиомам f1,f2, f4.
2.1.3 Метод объектной связи
Отличается от метода декомпозиции тем, что ФЗ привлекаются не на начальном, а на конечном этапе проектирования.
Предположим, что проектируется БД, предназначенная для хранения информации о преподавателях и курсах, которые они читают. Двумя главными сущностями здесь являются преподаватель и курс. Они соотносятся с помощью связи "читает", что позволяет нам сказать "преподаватель читает курс". Связь "читает" может быть представлена двумя способами.
1) Метод ER-диаграмм в ER-экземплярах;
2) Метод ER-типов.

1) 2)
Необходимо различать понятия сущности и отношения. Сущность переходит в отношение путем выделения ее из ER-диаграмм. Отсюда различие между ключом сущности и ключом отношения, они не всегда совпадают. В процессе перехода сущность ® отношение ключ сущности может быть дополнен некоторым атрибутом и стать ключом отношения. В большинстве случаев для определения набора отношений используется диаграмма ER-типа (вторая схема).

Нетрудно подсчитать, что для двух объектов общее число возможных состояний  . 4 типов соответствия; 2 класса принадлежности, 2 объекта.
. 4 типов соответствия; 2 класса принадлежности, 2 объекта.
Общий подход к проектированию
Связь "читает" — бинарная, так как соединяет две сущности.
1) Строится диаграмма ER-типа, включающая в себя все сущности и связи;
2) Строится набор предварительных отношений с указанием предполагаемого первичного ключа для каждого отношения;
3) Составляется список всех атрибутов (тех из них, которые не были перечислены в ER-диаграмме в качестве ключей сущности), каждый из этих атрибутов приписывается одному из предварительных отношений с тем условием, чтобы эти отношения находились в НФБК. Для каждого отношения должны быть определены межатрибутные функциональные зависимости, с помощью которых проверяется соответствие отношений НФБК. Если полученные в итоге отношения не находятся в НФБК или если некоторым атрибутам не находятся логически обоснованных мест в предварительных отношениях, необходимо пересмотреть ER-диаграмму.
Предварительные отношения для бинарных связей с типом соответствия 1:1.
Перечень общих правил генерации отношений можно получить, опираясь на:
1) Тип соответствия;
2) Класс принадлежности;
как определяющие факторы.
Правило 1: Если степень бинарной связи равна 1:1 и класс принадлежности обеих сущностей обязательный, то требуется только одно отношение. Первичным ключом этого отношения может быть ключ любой из этих двух сущностей. В этом случае гарантируется однократное появление каждого значения ключа в любом экземпляре отношения.
Правило 2: Если степень бинарной связи равна 1:1 и класс одной из сущностей необязательный, то необходимо построение двух отношений, под каждую сущность необходимо выделение одного отношения. Ключ сущности, для которого класс принадлежности является необязательным, добавляется в качестве атрибута в отношение, выделенное для сущности с обязательным классом принадлежности.
В том случае, если класс принадлежности ни одной из сущностей не является необязательным, недостаточно использования и двух отношений, т.к. возникают проблемы с внесением ключа сущности в отношение, выделенное под другую сущность.
Правило 3: Если степень бинарной связи равна 1:1 и класс принадлежности ни одной из сущностей не является необязательным, то используется три отношения — по одному для каждой сущности — ключи которых служат в качестве первичных в соответствующих отношениях и одного для связи. Отношение, выделенное для связи, будет иметь по одному ключу сущности от каждой сущности. Читает (Пр#,К#, …)
Предварительные отношения для бинарных связей с типом соответствия 1:M.
Для них требуется два правила. Фактором, определяющим выбор и использование одного из этих правил, является класс принадлежности многосвязной сущности. Класс принадлежности односвязной сущности не влияет на конечный результат в обоих случаях.
 K# K#
| Курс | Пр# | ФИО |
| 12 11 03 01 — | история политология физика математика — | 3 3 4 5 6 | Иванов Иванов Петров Сидоров Андреев |
Правило 4: Если степень бинарной связи равна 1:М и класс принадлежности М-связной сущности обязательный, то достаточно использовать два отношения: по одному на каждую сущность, при условии что ключ сущности служит в качестве первичного ключа для соответствующего отношения. Ключ же односвязной сущности должен быть добавлен как атрибут в отношение, отводимое М-связной сущности.
То есть получим таблицы
| К# | Курс | Пр# | Пр# | ФИО |
Если односвязная сущность вырождена в атрибут, то есть имеет в своем составе один атрибут, то возникает проблема.
Пример:
1) Товар хранится в ячейках на складе. В одной ячейке могут храниться товары разного рода, но каждый товар только в одной ячейке.
Ячейка вырождена.

2) Сотрудники занимают должность

Анализ примеров позволяет сделать вывод: если односвязная сущность представлена только ключом, то, в зависимости от класса принадлежности односвязной сущности, применяют разные правила:
а) Когда класс принадлежности односвязной сущности обязателен, то в "товар" добавляем "номер ячейки", получаем одно отношение.
б) Если класс принадлежности односвязной сущности необязателен, то имеем два отношения, так как "должность", которую никто не занимает, нужно хранить в БД.
Правило 5: Если степень бинарной связи равна 1:М и класс принадлежности М-связной сущности необязателен, то необходимо использовать три отношения: по одному на сущность и одно для связи. Связь должна иметь среди своих атрибутов ключ сущности от каждой сущности.
Предварительные отношения для бинарных связей с типом соответствия М:М.
Правило 6: Если степень бинарной связи равна М:М, то для хранения данных необходимо три отношения: по одному на сущность и одно для связи. Ключи сущности входят в связь. Если одна из сущностей вырождена, то — два отношения (т.е. достаточно будет двух таблиц).
Предварительные отношения для многосторонних связей.
Правило 7: В случае трехсторонней связи необходимо использовать четыре отношения: по одному на сущность и одно для связи. Отношение, порождаемое связью, имеет в себе среди атрибутов ключи сущности от каждой сущности.
Если связь n-сторонняя, требуется N+1 отношений: N для сущностей и 1 для связи.

По правилу 6 имеем три отношения. Количество характеристика связи.
Имеем четыре отношения.

Использование ролей в ER-моделях.
Одних только сущностей и связей может оказаться недостаточно для моделирования. Одна из таких ситуаций возникает тогда, когда экземпляры некоторой сущности должны играть разные роли. Рассмотрим на примере.
Пример:
Пусть необходима база данных для хранения информации о персонале предприятия. Различают две категории служащих: мастеров и сборщиков, мастера получают фиксированный оклад, у сборщиков почасовая оплата. Построим ER-диаграмму.

Используем правило 4, получим отношение:
Мастер (М#, …)
Сборщик(C#, …, M#)
Проблема возникает при добавлении не ключевых атрибутов в предварительные отношения. Предположим, что такими не ключевыми атрибутами являются ФИО служащего, телефон рабочий, телефон домашний, адрес, ставка, оклад, разряд. Нет проблем при размещении следующих атрибутов к отношениям:
Мастер (М#, тел. рабочий, оклад)
Сборщик(C#, ставка, разряд, М#)
Не размещенными остались атрибуты: ФИО, домашний телефон, адрес. Для полноты их следовало бы поместить в оба отношения, однако, как это было в общем правиле проектирования, каждый ключевой атрибут следует размещать только в одном отношении. Можно, конечно, оставшиеся три атрибута преобразовать в шесть атрибутов. Однако это не будет удачным решением, поскольку может привести к следующей проблеме: предположим, необходимо найти номер домашнего телефона служащего X. Т.к. неизвестно: Х – мастер или сборщик, необходимо просмотреть оба отношения с целью нахождения именно Х. А если существуют два служащих с именами Х (мастер и сборщик), то может быть выбран неправильный номер телефона. Для решения этой проблемы необходимо завести отношение "служащие" (то есть построить таблицу служащих). Мастер и сборщик — это те роли, которые они могут играть. Тогда ER-диаграмма имеет вид:
Шифр М#, C# и Сл# определены на одном домене.

Правило: исходная сущность служит источником генерации одного отношения. Ролевые элементы и связи, их соединяющие, порождают такое число отношений, которое определяется ранее описанными правилами. Причем каждая роль трактуется как обычная сущность.

Приведенный пример характеризуется
а) наличием связи между ролевыми объектами;
б) ролевые объекты не вырождены;
Особый случай возникает при наличии связи между вырожденными сущностями. Рассмотрим пример со спортивными командами, которые соревнуются друг с другом.
Получим два отношения:
Команда (K#, …)
Расписание (КХ#, КГ#, дата, счет)
Пример:


2.2 Организация СУБД
Понятие СУБД относится к набору средств ПО, необходимых для использования фактографических БД. Различают документальные и фактографические БД.
Документальные БД хранят совокупность произвольных текстовых документов.
Фактографические БД хранят множество сведений и фактов, хранящихся в информационной системе, удовлетворяющих фиксированной совокупности форматов.
СУБД — это набор ПС, позволяющий:
1) Описать и манипулировать данными, для чего предназначены соответствующие языки: язык описания данных (ЯОД) и язык манипулирования данными (ЯМД). Термин ЯД означает либо оба, либо один из названных языков. ЯД может быть включен в универсальный язык, либо представлять собой оригинальное языковое средство. В первом случае, включаемый язык называется подъязыком данных, во втором автономным ЯД.
2) Поддерживать модели данных пользователя.
3) Обеспечить защиту и целостность данных. Защита — это использование БД, пользователями имеющими на это право. Целостность — поддержка согласованности данных.
Логически в современных СУБД можно выделить:
1) Внутренняя часть — ядро СУБД (Data Base Engine — DBE).
2) Компилятор языка БД (SQL).
3) Набор утилит.
Ядро отвечает за следующие процессы:
1) Управление данными во внешней памяти.
2) Управление буферами оперативной памяти.
3) Управление транзакциями.
4) Журнализация.
Выделяют следующие компоненты ядра (DBE):
1) Менеджер данных.
2) Менеджер буфера.
3) Менеджер транзакций.
4) Менеджер журнала.

Ядро СУБД обладает собственным интерфейсом, недоступным пользователю напрямую. Этот интерфейс используется программами, производимыми компилятором SQL и утилитами БД.
При использовании архитектуры "клиент-сервер" ядро является основной составляющей сервера.
Основная функция компилятора — компиляция операторов языка БД в некоторую программу. Основной проблемой реляционных СУБД является то, что языки этих систем (SQL) являются непроцедурными.
2.2.1 Требования к современной СУБД
Традиционные файловые системы характеризуются тесной связью между физическими данными и прикладной программой. В ней отсутствуют практически все средства, предлагаемые СУБД.
Перечислим основные проблемы, возникающие в файловых системах:
1) Зависимость данных;
2) Жесткость и статичность;
3) Дублирование данных;
4) Отсутствие интеграции;
5) Невозможность обработки нетипичных запросов.
Современные СУБД разрабатываются с целью устранения этих недостатков.
Основные требования:
1) Независимость данных. Одна из самых важных задач при разработке БД — спроектировать ее так, чтобы изменение БД можно было выполнить без модификации прикладных программ. Для реализации этого требования структура БД должна отвечать требованиям физической и логической независимости данных. Физическая независимость данных — когда в файловой организации данных и в аппаратных средствах вносятся изменения, они должны быть отражены в ПО БД (т.е. в СУБД), но не должны затрагивать прикладные программы. Логическая независимость данных — представление данных в прикладной программе должно быть защищено от изменения:
- в глобальной логической структуре;
- в требованиях данных других прикладных программ.
Примеры возможных изменений:
а) модификация старых прикладных программ;
б) добавление новых прикладных программ, использующих новые типы данных;
в) добавление новых полей и создание новых связей.
Для достижения такой независимости необходимо отделить представление данных в каждой прикладной программе от общего логического представления и обеспечить возможность добавления новых полей в запись без перезаписи тех прикладных программ, которые используют эту запись. Тогда перечисленные изменения приведут к модификации общего логического представления и не коснутся прикладной программы.
Должны существовать три отдельных представления организации БД:
- физическое;
- общелогическое (концептуальная модель);
- представление данных в прикладных программах.
Итак, при логической независимости данных изменения ни в СУБД, ни в других прикладных программах не должны привести, в идеале, к изменению программы пользователя.
2) Универсальность. СУБД должна поддерживать разные модели данных.
3) Совместимость. Сохранение работоспособности при развитии программного и аппаратного обеспечения.
4) Минимальная избыточность данных.
5) Целостность данных.

а) физическая — защита данных от физических разрушений. Обеспечивается средствами ведения журнального файла, в котором регистрируются все изменения БД с некоторого момента времени. На момент начала ведения журнального файла создается копия БД.
б) логическая — предупреждает неверное использование данных. Обеспечивается механизмом управления доступом к данным. Ограничение доступа ко всей БД, доступ не ко всей записи, а только к ее части, заданной областью допустимых значений.
в) семантическая — поддерживает осмысленное сочетание разных данных.
6) Защита данных от несанкционированного доступа.
а) конфиденциальность —защита от несанкционированного получения данных;
б) целостность — защита от несанкционированного изменения данных;
в) доступность — защита от несанкционированного удержания данных.
7) Обеспечение коллективного доступа к данным. Поскольку данные интегрированы, возникает проблема синхронизации параллельного доступа к одним и тем же данным многих пользователей. Обычно проблема возникает при записи. Также проблема возникает, когда процедура обновления завершается аварийно. В этом случае до разблокировки необходимо выполнить откат, или восстановление назад. При откате будут уничтожены все изменения БД, инициированные процедурой обновления.
8) СУБД должна поддерживать как централизованные, так и распределенные БД.
2.2.2 Архитектура СУБД
Существует несколько уровней представления данных:
1) Описание конкретного конечного пользователя, имеющего локальное описание;
2) Общее логическое описание, интегрирующее описание локальных пользователей;
3) Описание физической организации БД.
Описание модели на каком-либо языке называется схемой. В соответствии с уровнями представления различают:
1) Подсхема, или внешняя схема — представление локального пользователя;
2) Концептуальная схема, или модель описания логической структуры БД на языке СУБД.
3) Физическая, или внутренняя схема.
Указанные виды схем связывают больше с этапом эксплуатации БД, когда БД уже спроектирована, и общая логическая схема нашла свое отражение в конкретной СУБД.
На этапе проектирования можно выделить логическое пользовательское представление и информационную схему предметной области.
Все эти разновидности уровней описания принято связывать с понятием архитектура СУБД.
Описание предметной области, выполненное без ориентации на используемые в дальнейшем программные и технические средства, называется инфологической моделью предметной области, а сам этап проектирования — инфологическим проектированием. Концептуальная модель БД является моделью логического уровня, то есть обрабатывает логические связи между элементами данных безотносительно к их содержанию и среде хранения.
Эта модель строится в соответствии терминам той конкретной СУБД, в среде которой проектируется БД. Этот этап называется даталогическим проектированием.
Описание физической структуры БД называется схемой хранения. Этот этап называется физическим проектированием. На этом этапе могут выполняться следующие работы:
1) Выбор типа носителя;
2) Способ организации данных;
3) Метод доступа;
4) Определение размера физического блока;
5) Выбор методов сжатия или отказ от них;
6) Проблема утилизации и т.д.
В большинстве настольных СУБД этот этап проектирования скрыт от пользователя.
Описание логической структуры БД с точки зрения конкретного пользователя называется подсхемой. Это внешняя модель БД. Если СУБД поддерживает схему, схему хранения и подсхему, то она является СУБД с трехуровневой архитектурой. Если СУБД поддерживает уровень подсхем, то перед проектировщиком возникает задача их определения. Это можно рассматривать как еще один этап проектирования. Если определена подсхема, то пользователь имеет доступ только к тем данным, которые отражены в соответствующей подсхеме, что является одним из способов защиты информации от несанкционированного доступа к данным. В подсхеме могут также задаваться допустимые режимы обработки, что служит дополнительным механизмом защиты информации от разрушения.
В тех случаях, когда СУБД не поддерживает подсхемы, перечисленные функции могут выполнять другие компоненты системы. Близким к понятию подсхем является понятие "представление".


2.2.3 Работа СУБД

На рисунке представлена последовательность основных действий, реализуемых СУБД в процессе считывания записи для прикладной программы.
1) Прикладная программа А выдает запрос СУБД на чтение записи.
2) СУБД получает в распоряжение подсхему, исполняемую программой А, и осуществляет в ней поиск описания данных, на которые выдан запрос.
3) СУБД получает в распоряжение схему (глобальное логическое описание данных) и с ее помощью определяет необходимый тип логических данных.
4) СУБД просматривает описание физической организации БД и определяет, какую физическую запись требуется считать.
5) СУБД выдает операционной системе команду чтения требуемой записи.
6) Операционная система взаимодействует с физической памятью, в которой хранятся данные.
7) Запрошенные данные передаются из памяти в системный буфер.
8) СУБД осуществляет сравнение схемы и подсхемы, выделяет ту логическую запись, которая запрошена прикладной программой. Любое преобразование данных, необходимость которого возникает из-за различий в описании одних и тех же данных в схеме и подсхеме, выполняется СУБД.
9) СУБД передает данные из системного буфера в рабочую область прикладной программы А.
10) СУБД передает прикладной программе информацию о результатах выполнения различных процедур по обслуживанию ее запросов. Эта информация содержит также сведения о возможных ошибках.
11) Прикладная программа обрабатывает данные, помещенные в рабочую область.
2.3 Организация данных
2.3.1 Физическая организация данных
Проблема физической организации данных: каким образом можно представить структуры данных в памяти компьютера в виде последовательной цепи?
Аспекты проблемы:
1) Как можно найти необходимую запись среди множества данных? Группа битов, которую можно прочитать с помощью одной машинной инструкции, называется одной физической записью. Программы идентифицируют логическую запись с помощью ключа.
Ключ® машинный адрес
Переход от ключа к адресу определяет сущность способа адресации, которые будут рассмотрены ниже.
2) Каким образом организовать данные, чтобы поиск был эффективным, а выборку записей можно было бы осуществлять по нескольким ключам?
3) Каким образом древовидные сетевые структуры можно представить в виде последовательности битов?
4) Как добавить новую запись к данным, уничтожить старые записи, не нарушая структуры адресации и поиска, а также структуру данных?
Ключ БД — RID (Record IDentificator)
Каждой записи СУБД присваивается внутренний идентификатор. Ключ БД не следует приравнивать ключу записи. Если значение ключа записей задается пользователем, то RID устанавливается системой при размещении.
Пример:
1) RID состоит из номера страницы и номера записи на странице;
2) Последовательный номер записи в файле.








