 2020-01-14
2020-01-14 167
1671) Последовательное сканирование файла — сканируется файл с проверкой ключа каждой записи. Эффективен только для файлов с последовательным доступом. Записи должны быть упорядочены по ключу.
2) Блочный поиск — записи упорядочиваются по ключу. И при сканировании файла можно рассматривать не каждую запись, а каждую сотую в последовательности возрастающих ключей. Затем область поиска сужается.
3) Двоичный поиск — рассматривается запись в середине области, в которой выполняется поиск и ее запись сравнивается с поисковым ключом. Делится пополам.
4) Индекс на последовательный файл — последовательное сканирование файла для нахождения записи требует много времени, если оно выполняется над всем файлом. Но сканирование можно использовать для небольшой области, которая представляет весь файл. Пусть файл упорядочен по ключу. Для адресации к такому упорядоченному файлу используется таблица, называемая индексом.
5) Индекс на произвольные файлы — записи располагаются в произвольной последовательности, как правило, в порядке ввода в БД. Непоследовательный файл можно индексировать точно также, как и последовательный. Но для этого требуется значительно больший по размеру индекс, т.к. он должен содержать по одному элементу для каждой записи файла, а не для блока записей. Кроме того, в нем должны содержаться полные абсолютные адреса.
6) Адресация с помощью ключа, эквивалентного адресу. Известны много методов преобразования ключа непосредственно в адрес в файле. Когда такое преобразование возможно, оно обеспечивает самую быструю адресацию. Например, в некоторых банковских системах номера счетов изменялись так, чтобы номер счета или его часть являлись бы адресом записи в БД.
7) Алгоритм преобразования ключа в адрес дает почти ту же скорость, что и предыдущий. Но характеризуется неэффективным использованием памяти. Поскольку ключи преобразуются в непрерывное множество адресов, в файле остаются свободные участки.
8) Хеширование. При запоминании новой записи специальная программа ставит в соответствие значению первичного ключа номер страницы, куда следует поместить запись. Таким образом, перемешиваются по страницам все записи. Записи, для которых хеширование выдает одинаковые страницы, называются синонимами. Синонимы объединяются в связанный список, начало которого находится в заголовке таблицы. Если при заполнении очередного синонима для него не хватило места на одной странице, он размещается на другой странице, но включается в цепь синонимов той области, куда был хеширован. При извлечении записи по первичному ключу СУБД подключает программу хеширования, вычисляет номер страницы, а затем просматривает цепь синонимов на этой странице до нахождения нужной записи.
2.3.2 Организация индексных таблиц
Индекс можно определять как таблицу, воспринимающую на входе информацию о некоторых значениях атрибутов и выдающую на выходе информацию, соответствующую быстрому поиску записей, которые имеют заданное значение атрибутов.
Индексная таблица должна быть упорядочена по входному индексу.
Следует различать индексирование по первичному ключу и вторичное индексирование.
Первичное индексирование
СУБД, размещая записи на странице данных, формирует специальные индексные таблицы. Они используются для нахождения адреса записи по значению первичного ключа. При этом СУБД производит поиск записи не в файле, а в индексе. Если записи файла упорядочены по ключу, индекс обычно содержит не ссылки на каждую запись, а ссылки на блоки записи, внутри которых можно выполнять поиск или сканирование.
Рассмотрим один из известных механизмов индексирования. Пусть записи имеют ключи со значениями из натурального ряда. Перед загрузкой записи должны быть упорядочены по значению ключей.
Особенности первичного индексирования:
1) Ключ индексирования должен иметь уникальное неизменное значение;
2) Первоначальная загрузка должна выполняться обязательно с предварительной сортировкой;
3) Формирование индексной таблицы происходит одновременно с загрузкой записей файлов, а значение ключей индексирования влияют на размещение записей в памяти.
Вторичное индексирование
При обработке БД возникает потребность извлечения записи по значению данных, отличных от первичного ключа, например, извлечь данные из записи о студентах данной специальности или по специальности — номер группы. Последовательный просмотр большого числа записей может оказаться неэффективным. Другой вариант состоит в использовании вторичного индексирования.
Вторичные ключи могут идентифицировать записи неединственным образом. Одному вторичному ключу могут соответствовать несколько записей

КБД — ключ БД
Особенности вторичного индексирования:
1) Вторичные ключи могут иметь неуникальное значение. Допускается изменение значений вторичных ключей. При этом системой автоматически будут корректироваться соответствующие таблицы.
2) Вторичное индексирование служит только для выборки данных и никак не используется при размещении данных в памяти.
3) Таблицы вторичного индексирования можно создавать не только при первоначальной загрузке, но и в любое другое время.
Организация индексных таблиц должна обеспечивать быстрое нахождение адреса записи по значению ключа. Один из механизмов индексирования нам уже известен, это иерархия индексных таблиц с последовательным просмотром внутри таблицы. Этот механизм работает только если записи перед загрузкой накапливаются и упорядочиваются. Если же загрузка БД происходит в реальном времени, то этот механизм малоэффективен. Рассмотрим другие механизмы индексирования.
Бинарное деление
Индексная таблица при этом механизме индексирования состоит из множества записей, связанных адресными ссылками в иерархическую структуру. Такие записи называют индексными.
Каждая индексная запись (ИЗ) содержит
1) Значение ключа записи;
2) Адрес этой записи (ключ БД);
3) Адресная ссылка на ИЗ с ключом меньше данного;
4) Адресная ссылка на ИЗ с ключом больше данного.
При этом механизму не требуется, чтобы записи предварительно накапливались и упорядочивались. Каждой записи БД соответствует одна ИЗ. Первая ИЗ становится корневой.
Пример:
| # записи | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Ключ записи | 12 | 8 | 4 | 9 | 6 | 13 | 14 | 16 | 100 | 10 | 25 | 31 |
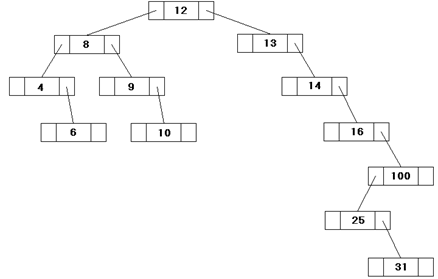
Поиск записи по значению ключа выполняется по тому же алгоритму, начиная с корня БД. Механизм основан на известном дихотомическом поиске. Наряду с достоинствами, бинарные деревья имеют значительные недостатки. В нашем примере для извлечения записи с ключом записи, равным 31, требуется 7 шагов, а для записи, с КЗ=6 — 4 шага, хотя обе записи конечны. Такое дерево называется несбалансированным.
Сбалансированные деревья — деревья, в которых все конечные вершины равноудалены от корня. Если бинарное дерево растет вниз и корень неизменен, то В-дерево растет вверх и корень меняется.
В-дерево n-ого порядка должно удовлетворять следующим условиям:
1) Любая вершина может содержать n адресных ссылок и n-1 ключей. Ссылка влево от ключа обеспечивает переход к вершинам дерева с меньшими значениями ключа, вправо — с большими.
2) Любая неконечная вершина может иметь не менее n/2 подчиненных вершин.
3) Если неконечные вершины содержат k ключей, то им подчинена k+1 вершина на следующем уровне иерархии.
4) Все конечные вершины В-дерева расположены на одном уровне.
Алгоритм формирования В-дерева предполагает первоначальное заполнение корня до тех пор, пока не будут сформированы все ее n-1 ключей. Затем при появлении очередной записи выделяется новая корневая вершина и несколько подчиненных ей вершин. При запоминании нового ключа поиск места для него начинается с корня В-дерева. При этом используется алгоритм, рассмотренный для бинарного дерева.
Пример:
Пусть сгружается та же последовательность записей с формированием бинарного дерева с n=3. Тогда каждая запись такого дерева рассчитана на хранение 2-х ключей и 3-х ссылок. Первоначально корневая вершина содержит только ключ 12.
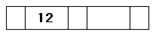
Затем он сдвигается вправо, уступая место ключу 8, так как внутри записи ключи расположены в порядке возрастания значений.
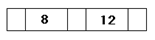
Далее, поскольку для ключа 4 нет записи в корневой записи, происходит ее деление. Из трех ключей (4, 8, 12) выбирается средний ключ (8), чтобы ключи 4 и 12 попали в две подчиненные записи.

При этом будет выполнено ограничение 2) и 3). Это общее правило для деревьев 3-го порядка.
В итоге получим следующее дерево:
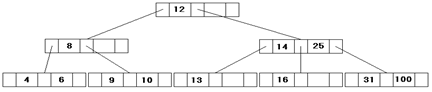
Связанные списки
В сетевых иерархических моделях данных связь с данными

поддерживается групповыми отношениями. Наиболее распространенный способ реализации группового отношения — построение связанных списков.
Последняя подчиненная запись содержит либо ссылку на владельца, либо признак конца цепи (замкнутый или разомкнутый список). Рассмотренный тип ссылок называется ссылками на следующий. В цепном связанном списке могут использоваться и другие типы ссылок:
- ссылка на владельца обеспечивает движение по групповому отношению вверх;
- ссылка на предыдущий обеспечивает просмотр в обратном направлении и повышает эффективность процедур удаления записей из группового отношения. Ссылка на предыдущий формируется у всех участников списка, включая запись владельца. Владелец при этом будет содержать кроме ссылки на первую подчиненную запись еще и ссылку на последнюю.
Пусть, например, необходимо удалить В2. Удаление будет корректным, если В1 будет указывать на В3. Для этого необходимо сделать шаг назад, для чего и нужна ссылка на предыдущий узел.
Существует несколько видов отображения групповых отношений на физическую память. Чаще всего — левосторонний обход структуры дерева, за последней записью первого дерева размещается корень следующего и т.д.
| Стр.1 | А1 | В1 | М1 | М2 | В2 |
| Стр.2 | В3 | М3 | М4 | М5 | Н1 |
2.4 Обновление и восстановление данных
При динамической реорганизации страниц записи плотно размещаются в начале каждой страницы, а в конце расположен свободный участок. Тогда адрес начала свободного участка хранится в начале таблицы.
При удалении некоторой записи таблица сжимается и увеличивается длина свободного участка. Для учета свободных участков на странице СУБД поддерживает инвентарные страницы. Одна инвентарная страница создается для группы страниц данных и содержит сведения о наличии на них свободных участков памяти.
Запоминание новых записей
При запоминании СУБД ищет место для записи в области хранения. Поиск ведется сначала через инвентарные страницы, а затем — на страницах данных. Если для учета свободных участков используется цепи участков, то СУБД выбирает первый свободный участок, пригодный по длине. Если длина записи меньше длины свободного участка, то участок оформляется в виде нового свободного участка. В результате может образоваться несколько небольших свободных участков, не позволяющих запомнить новую запись.
При динамической реорганизации страниц такого случиться не может, так как на каждой странице поддерживается один свободный участок. После запоминания записи СУБД корректирует содержимое соответствующей инвентарной страницы.
Корректировка
Если элементы данных имеют фиксированную длину, то обновленные значения помещаются на место прежних. Если система допускает переменную длину, то обновленная запись может иметь длину отличную от прежней. В этом случае либо реорганизуется страница, либо перемещается запись на другой участок памяти.
Транзакция
Восстановление данных в СУБД означает возвращение БД в согласованное, непротиворечивое состояние, если какой-нибудь сбой сделал текущее состояние противоречивым. Принцип, на котором строится такое восстановление, это избыточность, которая образуется на физическом уровне. Если любая часть информации содержащейся в БД, может быть восстановлена из другой (хранимой в БД или извне), то такая БД восстановимая. Проблемы восстановления и параллелизма являются аспектами одной проблемы — проблемы транзакции.
Транзакция — это последовательность операций над БД, рассматриваемая СУБД как единое целое.
Особенности транзакции:
1) Всегда связана с изменениями в БД, вызываемых операциями INSERT, DELETE, ACCEPT в SQL;
2) Транзакция — логически связанная последовательность одной или нескольких таких операций, которые преобразуют одно непротиворечивое состояние БД в другое, но не гарантируют этого в промежуточные моменты времени.
Пример:
Пусть мы хотим изменить значение первичного ключа какого-либо кортежа. Для этого используется команда UPDATE. По ней за один раз можно обновить только одну таблицу. Поэтому одной операцией UPDATE не обойтись, так как кортеж — это этап в других отношениях. В данном примере мы сталкиваемся с проблемой целостности по ссылкам. БД становится противоречивой после выполнения первой команды UPDATE. Тогда транзакция будет включать в себя столько операций UPDATE, сколько раз этот кортеж входит в другие отношения.
Что будет, если внутри транзакции будет аварийный отказ? Все зависит от того, поддерживает ли система обработку транзакций. Система, обрабатывающая транзакции, гарантирует, что если в транзакцию входит обновление базы данных, а затем произошла ошибка (до того, как транзакция достигла нормального завершения), то эти обновления будут аннулированы.
Таким образом, возможны два исхода выполнения транзакции:
1) Транзакция полностью исполняется;
2) Транзакция полностью аннулируется.
С точки зрения конечного пользователя транзакция кажется атомарной — ее обслуживают системные компоненты — монитор (диспетчер) транзакций (МТ). МТ не является частью СУБД, наоборот, СУБД подчиняется МТ. МТ определяет две команды:
1) COMMIT — фиксация;
2) ROLLBACK — откат.
В зависимости от типа МТ они могут выглядеть по-разному.
Точка синхронизации (ТС) представляет собой граничную точку между двумя последовательными транзакциями. ТС устанавливается при инициализации программы и при выполнении команд МТ:
1) COMMIT — сообщает об успешной транзакции и устанавливает ТС. Все обновления, сделанные транзакцией, фиксируются. Снимаются все блокировки записей, все открытые курсоры закрываются.
2) ROLLBACK — сообщает о неудачном завершении транзакции и устанавливает ТС. Все обновления программы (после установки последней ТС) аннулируются. Снимаются все блокировки записей, все открытые курсоры закрываются.
Восстановление транзакции
Производится в ситуациях:
1) Индивидуальный откат транзакции;
a) явное завершение оператором ROLLBACK,
b) откат производится самой системой (выбор транзакции как "жертвы" в синхронизационном тупике);
2) Восстановление после внезапной потери содержимого ОЗУ (мягкий сбой);
3) Восстановление после поломки основного внешнего носителя (жесткий сбой).
Во всех трех случаях основа восстановления — избыточное хранение данных. Они хранятся в журнале, содержащем последовательность записей об изменении БД. Журнализация изменений часто связана не только с управлением транзакциями, но и с буферизацией страниц БД в оперативной памяти.
Если бы запись об изменении БД сразу записывалась во внешнюю память, это привело бы к замедлению работы системы. Поэтому записи журнала тоже буферизируются.
Существуют два вида буферов:
1) Буфер журнала;
2) Буфер страниц БД.
Оба буфера всегда восстанавливаются во внешнюю память. Проблема состоит в выработке восстановления буфера во внешнюю память. Основным принципом такого восстановления является то, что запись об изменении объекта БД должна попадать во внешнюю память раньше, чем измененный объект помещается во внешнюю память. Такой протокол называется "пиши сначала в журнал"

Индивидуальный откат транзакции
1) Выбирается очередная запись из списка данной транзакции;
2) Выбирается противоположная по смыслу операция;
3) Любая из этих обратных операций также журнализируется;
4) При успешном завершении отката заносится в журнал запись о конце транзакции.
Восстановление после мягкого сбоя
1) Страницы БД буферизируются в ОЗУ и восстанавливаются независимо;
2) Несмотря на применение WAL после мягкого сбоя набор атрибутов БД во внешней памяти может оказаться несогласованным, т.е. часть страницы во внешней памяти соответствует БД до изменения, часть — после изменения.
Состояние внешней памяти БД называется физически согласованным, если наборы всех страниц согласованны, т.е. соответствуют состоянию объекта либо до, либо после изменений.
Будем считать, что в журнале отмечаются точки согласованности БД, т.е. моменты времени, в которые во внешней памяти создаются согласованные результаты операций, завершенных до соответствующего момента времени, и отсутствуют результаты операций, которые не завершились, а буфер журнала вытолкнут во внешнюю память. Тогда к моменту мягкого сбоя будут следующие состояния транзакций:

Пусть удалось восстановить внешнюю память БД к согласованному состоянию и времени tфс, тогда для:
T1 — никаких действий не производить.
T2 — нужно повторно выполнить оставшуюся часть операций, так как во внешней памяти полностью отсутствуют следы операций, которые выполнялись транзакцией после времени tфс.
Это приведет к согласованному состоянию БД, так как транзакция Т2 успешно завершилась до момента мягкого сбоя и в журнале содержатся все действия (REDO).
T3 — выполняется в обратном направлении первая часть операций (UNDO).
Во внешней памяти БД полностью отсутствуют результаты операций транзакций Т3, которые были выполнены после tфс. С другой стороны, во внешней памяти существуют результаты операций Т3, которые были выполнены до tфс.
Т4 — выполняются повторно полностью все операции (REDO).
Т5 — никакие действия не предпринимаются.
Во внешней памяти БД полностью отсутствуют результаты операций транзакции Т5.
Восстановление после жесткого сбоя
При восстановлении последнего состояния БД после жесткого сбоя журналы и данные явно недостаточны. Основой восстановления в этом случае является журнал и архивные копии БД. Восстановление начинается с обратного копирования БД из архивной копии. Затем для всех закончившихся транзакций выполняется REDO, т.е. операции повторно выполняются в прямом смысле. Более точно происходит следующее:
1) По журналу в прямом направлении выполняются все операции;
2) Для транзакций, которые не закончились к моменту сбоя, выполняется откат.
Так как жесткий сбой не сопровождается утратой буферов ОЗУ, можно восстановить БД до такого уровня, что даже можно выполнить незавершенные транзакции.
Хотя к ведению журнала предъявляются особые требования по части надежности, возможна его утрата. Тогда единственным способ восстановления БД является возврат к архивной копии. В этом случае не удается получить последнее согласованное состояние БД.
2.5 БД в сетях
По характеру организации хранения данных и обращения к ним различают персональные (локальные), централизованные и распределенные базы данных.
1) Персональные — все части СУБД размещаются на компьютере пользователя локальной БД. Если к одной БД обращаются несколько пользователей одновременно, то каждый пользователь должен иметь свою копию. Этот вариант в корпоративной работе практически не встречается, т.к. в нем чрезвычайно трудно синхронизировать содержимое нескольких копий БД. Это проблема согласования (репликации) БД.
2) Централизованные — такие БД, которые хранятся на одном компьютере, находящемся в узле сети, с помощью которой различные подразделения получают доступ к данным. Централизованные базы данных обычно организуются в рамках локальной вычислительной сети.
3) Распределенные — такие БД, в которых данные распространяются по сети.
Приведенные понятия следует отличать от понятия распределенной обработки данных, которая может быть организована и при централизованном хранении БД. Пусть большая БД расположена на мощном компьютере. Можно организовать доступ к этой БД из других компьютеров, подключенных к сети. При этом выборка и предварительная обработка данных будет выполняться мощной машиной, а окончательная обработка и представление данных — менее мощным ПК пользователя-клиента.
Архитектура взаимодействия клиента и сервера

I. Локальные и файл-серверные БД.
В каждый момент времени клиент работает с некоторой локальной копией БД, причем управление данными целиком возлагается на клиентские программы. Именно они должны заботиться о синхронизации копий данных на каждой машине. В обоих случаях ядро располагается на машине клиента и вместе с программой образует локальную СУБД, количество которых равно количеству пользователей.
Архитектура "файл-сервер" обладает следующими недостатками:
1) Вся тяжесть вычислительной работы ложится на компьютер клиента, например, если в результате запроса клиент должен получить две записи из таблицы объемом 100.000 записей все они будут скопированы с файл-сервера на ПК клиента.
2) Так как БД — набор файлов на сетевом сервере, то доступ к таблице регулируется только сетевой ОС, что делает такие БД беззащитными.
3) Бизнес-правила в системах файл-сервера реализуются в программе клиента, что не исключает проектирование противоречащих друг другу бизнес-правил в различных программах.
4) Недостаточно развитый аппарат транзакции локальной СУБД служит потенциальным источником ошибок при одновременном внесении изменений.
II. Клиент-серверные БД.

В архитектуре "клиент-сервер" между ядром и БД появляется сервер БД.
Сервер БД — специальная программа, управляющая БД. Клиент формирует запрос к серверу на языке SQL. Большинство существующих серверов умеют обрабатывать язык SQL.
SQL-сервер обеспечивает интерпретацию и выполнение запроса, формирование результата и выдачу этого результата клиенту.
При этом сам клиент не участвует в физическом выполнении запроса. ПК клиента лишь посылает запрос серверу и получает результат. В итоге снижается нагрузка на сеть, т.к. по сети передаются только те данные, которые нужны клиенту. Обычно такой сервер работает в среде многозадачной ОС.
III. Трехзвенная архитектура клиент-сервер.
Теперь клиентские машины могут не иметь ядра, а клиентские программы уже не включают в себя громоздкие коды компонентов-источников. Реализация большей части клиентских бизнес-правил переводится на сервер приложений. Поэтому такая клиентская программа называется облегченным, или тонким, клиентом. Такой клиент не требует больших ресурсов памяти и может загружаться с сервера. Это главное преимущество трехзвенной архитектуры.
На рисунке показан вариант размещения сервера приложений на машине сервера БД. Это наиболее популярный вариант, но не обязательный. Сервер приложений может размещаться на любой машине, оснащенной ядром

2.6 Доступ к данным в Windows
На сегодняшний день существуют две параллельно развивающиеся конкурирующие технологии взаимодействия между объектами и программами. Это COM (Component Object Model) и CORBA (Command Object Require Broker Architecture). COM развивается компанией Microsoft, CORBA — другими.
Технология COM
Предназначена для того, чтобы одна программа (клиент) смогла заставить работать объект, который является частью другой программы (сервера) так, как если бы этот объект был частью клиента, причем обе программы в общем случае могут быть:
1) Расположены на разных машинах;
2) Написаны на разных языках;
3) Использоваться в разных ОС;
4) Располагаться на машинах разного типа.
Ключевое понятие COM — это интерфейс. Интерфейс имеет уникальный идентификатор и набор параметров, описывающих методы, события и свойства общего объекта. Идентификатор интерфейса является частным случаем глобального системного идентификатора. В Windows входят функции, генерирующие эти идентификаторы. Вероятность совпадения двух идентификаторов ничтожно мала.
Параметры идентификатора в общем случае описывают типы и имена используемых полей, количество и типы параметров обращения к доступным методам и свойствам, имена методов и свойства и т.д. Получив идентификатор внешнего СОМ-объекта, клиент может его использовать также, как и свои собственные.
Сервер СОМ представляет собой исполняемую программу или.DLL, содержащую один или несколько объектов СОМ. В зависимости от местоположения клиента и сервера возможны 3 варианта:
1) Клиент и сервер расположены на одной машине и запускаются в одном процессе. В этом случае сервер представляет собой.DLL.
Клиент с помощью интерфейса объекта непосредственно обращается к методам объектов в своем собственном адресном пространстве.

2) Клиент и сервер располагаются на одной машине, но запускаются в разных процессах. Например, таблица Excel вставляется в документ Word. В этом случае сервер представляет собой программу.

3) Клиент и сервер располагаются на разных машинах. Сервером может быть как программа, так и.DLL. В этом случае используют распространенный вариант COM — DCOM.

Если сервер запускается в другом процессе или на другой машине, между объектом и клиентом располагаются два посредника: Proxy (уполномоченный) и Stub (заглушка).
Клиент посещает параметры вызова в стек и обращается к методу интерфейса объекта. Это обращение перехватывается Proxy, упаковывает параметры вызова в пакет СОМ и направляет его в Stub другого процесса. Stub распаковывает параметры, помещает в стек и делает вызов нужного метода объекта. Таким образом, метод объекта выполняется в собственном адресном пространстве процесса сервера.
Понятие открытого интерфейса Windows

Для унификации связи Microsoft поддерживает так называемую открытую архитектуру. Целью открытой архитектуры является соединение ПК и информационными службами. WOSA представляет собой некоторый изолирующий слой между прикладной программой и источником данных.
Такой архитектурой определены два стандартных интерфейса:
1) API — интерфейс прикладных программ. Разработчики приложений используют только этот интерфейс для доступа к любому числу информационных служб.
2) SPI — интерфейс, обеспечения информационных служб. Поставщики служб пишут драйверы, обеспечивающие доступ к этим службам.
Преимущества:
1) Существует доступ пользователя к информационным службам без изучения различных приложений;
2) Поставщики могут сделать доступными свои приложения для большого числа пользователей;
3) Разработчики. Их приложения получают новые возможности без использования различных интерфейсов.
Глава 3. Работа с таблицами базы данных на примере СУБД Microsoft Access
Таблицы – фундаментальные объекты реляционной базы данных, в которых хранится основная часть данных приложения. Отдельная таблица чаще всего хранит информацию по конкретной теме (например, сведения о служащих компании или адреса заказчиков). Информация в таблице организуется в строки (записи) и столбцы (поля). Таблице присущи два компонента: структура таблицы и данные таблицы.








