 2020-05-25
2020-05-25 679
679Формальные языки
Определение 1.1.1. Будем называть натуральными числами неотрицательные целые числа. Множество всех натуральных чисел {0, 1, 2,...} обозначается N.
Определение 1.1.2. Алфавитом называется конечное непустое множество. Его элементы называются символами (буквами).
Определение 1.1.3. Словом (цепочкой, строкой, string) в алфавите  называется конечная последовательность элементов .
называется конечная последовательность элементов .
Пример 1.1.4. Рассмотрим алфавит = {a, b, c}. Тогда baaa является словом в алфавите .
Определение 1.1.5. Слово, не содержащее ни одного символа (то есть последовательность длины 0), называется пустым словом и обозначается  .
.
Определение 1.1.6. Множество всех слов в алфавите обозначается  .
.
Замечание 1.1.7. Множество счетно. В самом деле, в алфавите множество всех слов данной длины конечно, следовательно,  является объединением счетного числа конечных множеств.
является объединением счетного числа конечных множеств.
Определение 1.1.8. Множество всех непустых слов в алфавите обозначается  .
.
Пример 1.1.9. Если = {a}, то = {a,aa,aaa,aaaa,...}.
Определение 1.1.10. Если  , то L называется языком (или формальным языком) над алфавитом .
, то L называется языком (или формальным языком) над алфавитом .
Поскольку каждый язык является множеством, можно рассматривать операции объединения, пересечения и разности языков, заданных над одним и тем же алфавитом (обозначения  ).
).
Пример 1.1.11. Множество {a, abb} является языком над алфавитом {a, b}.
Определение 1.1.12. Пусть . Тогда язык  называется дополнением языка L относительно алфавита . Когда из контекста ясно, о каком алфавите идет речь, говорят просто, что язык является дополнением языка L.
называется дополнением языка L относительно алфавита . Когда из контекста ясно, о каком алфавите идет речь, говорят просто, что язык является дополнением языка L.
Определение 1.1.13. Если x и y - слова в алфавите , то слово xy (результат приписывания слова y в конец слова x) называется конкатенацией,(катенацией, сцеплением) слов x и y. Иногда конкатенацию слов x и y обозначают  .
.
Определение 1.1.14. Если x - слово и  , то через xn обозначается слово
, то через xn обозначается слово  . Положим
. Положим  (знак
(знак  читается "равно по определению"). Всюду далее показатели над словами и символами, как правило, являются натуральными числами.
читается "равно по определению"). Всюду далее показатели над словами и символами, как правило, являются натуральными числами.
Пример 1.1.15. По принятым соглашениям ba3 = baaa и (ba)3 = bababa.
Пример 1.1.16. Множество  является языком над алфавитом {a,b}. Этот язык содержит слова b, ba, aba, baa, abaa, baaa, aabaa, abaaa, baaaa и т. д.
является языком над алфавитом {a,b}. Этот язык содержит слова b, ba, aba, baa, abaa, baaa, aabaa, abaaa, baaaa и т. д.
Определение 1.1.17. Длина слова w, обозначаемая |w|, есть число символов в w, причем каждый символ считается столько раз, сколько раз он встречается в w.
Пример 1.1.18. Очевидно, что |baaa| = 4 и  .
.
Определение 1.1.19. Через |w|a обозначается количество вхождений символа a в слово w.
Пример 1.1.20. Если 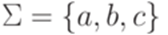 , то |baaa|a = 3, |baaa|b = 1 и |baaa|c = 0.
, то |baaa|a = 3, |baaa|b = 1 и |baaa|c = 0.
Операции над языками
Определение 1.2.1. Пусть  . Тогда
. Тогда

Язык  называется конкатенацией языков L1 и L2.
называется конкатенацией языков L1 и L2.
Пример 1.2.2. Если L1 = {a,abb} и L2 = {bbc,c}, то  .
.
Определение 1.2.4. Пусть . Тогда

Пример 1.2.5. Если L = {akbal | 0 < k < l}, то L2 = {akbalbam | 0 < k < l - 1, m > 1}.
Определение 1.2.7. Итерацией языка (Kleene closure) языка L (обозначение L*) называется язык

Эта операция называется также звездочкой Клини (Kleene star, star operation).
Пример 1.2.8. Если  и L = {aa,ab,ba,bb}, то
и L = {aa,ab,ba,bb}, то

Определение 1.2.11. Обращением или зеркальным образом слова w (обозначается wR) называется слово, в котором символы, составляющие слово w, идут в обратном порядке.
Пример 1.2.12. Если w = baaca, то wR = acaab.
Определение 1.2.13. Пусть . Тогда
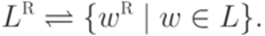
Язык LR называется обращением языка L.
Определение 1.2.15. Говорят, что слово x - префикс (начало) слова y (обозначение  ), если y = xu для некоторого слова u.
), если y = xu для некоторого слова u.
Пример 1.2.16. Очевидно, что  ,
,  ,
,  и
и  .
.
Определение 1.2.17. Пусть . Тогда через Pref(L) обозначается множество, состоящее из всех префиксов слов языка L:

Множество Pref(L) называется множеством префиксов языка L.
Определение 1.2.18 Говорят, что слово x - суффикс (конец) слова y (обозначение  ), если y = ux для некоторого слова u.
), если y = ux для некоторого слова u.
Определение 1.2.19. Пусть . Тогда через Suf(L) обозначается множество, состоящее из всех суффиксов слов языка L:

Множество Suf(L) называется множеством суффиксов языка L.
Определение 1.2.20. Говорят, что слово x - подслово (substring) слова y, если y = uxv для некоторых слов u и v.
Определение 1.2.21. Пусть . Тогда через Subw(L) обозначается множество, состоящее из всех подслов слов языка L. Множество Subw(L) называется множеством подслов языка L.
Определение 1.2.22. Слово a1a2...an (длины  ) называется подпоследовательностью (subsequence) слова y, если существуют такие слова u0, u1,..., un, что u0a1u1a2...anun = y.
) называется подпоследовательностью (subsequence) слова y, если существуют такие слова u0, u1,..., un, что u0a1u1a2...anun = y.
Замечание 1.2.23. Все подслова слова y являются также подпоследовательностями слова y.
Определение 1.2.24. Пусть . Тогда через Subseq(L) обозначается множество, состоящее из всех подпоследовательностей слов языка L. Множество Subseq(L) называется множеством подпоследовательностей языка L.
Пример 1.2.25. Рассмотрим язык L = { cba, c} над алфавитом {a, b, c}. Очевидно, что  .
.
Определение 1.2.26. Функция 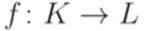 называется биекцией (bijection), если каждый элемент множества Lявляется образом ровно одного элемента множества K (относительно функции f).
называется биекцией (bijection), если каждый элемент множества Lявляется образом ровно одного элемента множества K (относительно функции f).
Определение 1.2.27. Множества K и L называются равномощными (of equal cardinality), если существует биекция из K в L.
Гомоморфизмы
Определение 1.3.1. Пусть  и
и 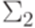 - алфавиты. Если отображение
- алфавиты. Если отображение  удовлетворяет условию
удовлетворяет условию  для всех слов
для всех слов  и
и  , то отображение h называется гомоморфизмом (морфизмом).
, то отображение h называется гомоморфизмом (морфизмом).
Замечание 1.3.2. Можно доказать, что если  - гомоморфизм, то
- гомоморфизм, то  .
.
Замечание 1.3.3. Пусть  и
и  . Тогда отображение
. Тогда отображение  , заданное равенством
, заданное равенством 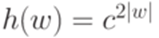 , является гомоморфизмом.
, является гомоморфизмом.
Замечание 1.3.4. Каждый гомоморфизм однозначно определяется своими значениями на однобуквенных словах.
Замечание 1.3.5. Если  - гомоморфизм и
- гомоморфизм и  , то через h(L) обозначается язык
, то через h(L) обозначается язык  .
.
Пример 1.3.6. Пусть 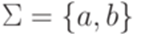 и гомоморфизм
и гомоморфизм  задан равенствами h(a) = abba и
задан равенствами h(a) = abba и  . Тогда
. Тогда

Определение 1.3.7. Если - гомоморфизм и  , то через h-1(L) обозначается язык
, то через h-1(L) обозначается язык  .
.
Пример 1.3.8. Рассмотрим алфавит  . Пусть гомоморфизм
. Пусть гомоморфизм  задан равенствами h(a) = ab и h(b) = abb. Тогда
задан равенствами h(a) = ab и h(b) = abb. Тогда

Порождающие грамматики
Определение 1.4.1. Порождающей грамматикой (грамматикой типа 0, generative grammar, rewrite grammar) называется четверка  , где N и - конечные алфавиты,
, где N и - конечные алфавиты,  ,
,  , P конечно и
, P конечно и  . Здесь - основной алфавит (терминальный алфавит), его элементы называются терминальными символами или терминалами (terminal), N - вспомогательный алфавит (нетерминальный алфавит), его элементы называются нетерминальными символами, нетерминалами, вспомогательными символами или переменными (nonterminal, variable), S - начальный символ (аксиома, start symbol). Пары
. Здесь - основной алфавит (терминальный алфавит), его элементы называются терминальными символами или терминалами (terminal), N - вспомогательный алфавит (нетерминальный алфавит), его элементы называются нетерминальными символами, нетерминалами, вспомогательными символами или переменными (nonterminal, variable), S - начальный символ (аксиома, start symbol). Пары  называются правилами подстановки, просто правилами или продукциями (rewriting rule, production) и записываются в виде
называются правилами подстановки, просто правилами или продукциями (rewriting rule, production) и записываются в виде  .
.
Пример 1.4.2. Пусть даны множества N = {S},  ,
,  . Тогда
. Тогда  является порождающей грамматикой.
является порождающей грамматикой.
Замечание 1.4.3. Будем обозначать элементы множества строчными буквами из начала латинского алфавита, а элементы множества N - заглавными латинскими буквами. Обычно в примерах мы будем задавать грамматику в виде списка правил, подразумевая, что алфавит N составляют все заглавные буквы, встречающиеся в правилах, а алфавит - все строчные буквы, встречающиеся в правилах. При этом правила порождающей грамматики записывают в таком порядке, что левая часть первого правила есть начальный символ S.
Замечание 1.4.4. Для обозначения n правил с одинаковыми левыми частями  часто используют сокращенную запись
часто используют сокращенную запись  .
.
Определение 1.4.5. Пусть дана грамматика G. Пишем  , если
, если  ,
,  и
и  для некоторых слов
для некоторых слов  в алфавите
в алфавите  . Если , то говорят, что слово
. Если , то говорят, что слово  непосредственно выводимо из слова
непосредственно выводимо из слова  .
.
Замечание 1.4.6. Когда из контекста ясно, о какой грамматике идет речь, вместо  можно писать просто
можно писать просто  .
.
Пример 1.4.7. Пусть

Тогда  .
.
Определение 1.4.8. Если  , где , то пишем
, где , то пишем  и говорим, что слово
и говорим, что слово  выводимо из слова
выводимо из слова  . Другими словами, бинарное отношение
. Другими словами, бинарное отношение  является рефлексивным, транзитивным замыканием бинарного отношения , определенного на множестве
является рефлексивным, транзитивным замыканием бинарного отношения , определенного на множестве  .
.
При этом последовательность слов  называется выводом (derivation) слова
называется выводом (derivation) слова 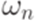 из слова в грамматике G. Число n называется длиной (количеством шагов) этого вывода.
из слова в грамматике G. Число n называется длиной (количеством шагов) этого вывода.
Замечание 1.4.9. В частности, для всякого слова 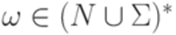 имеет место
имеет место  (так как возможен вывод длины 0).
(так как возможен вывод длины 0).
Пример 1.4.10. Пусть  . Тогда
. Тогда  . Длина этого вывода - 3.
. Длина этого вывода - 3.
Определение 1.4.11. Язык, порождаемый грамматикой G, - это множество  . Будем также говорить, что грамматика G порождает (generates) язык L(G).
. Будем также говорить, что грамматика G порождает (generates) язык L(G).
Замечание 1.4.12. Существенно, что в определение порождающей грамматики включены два алфавита - и N. Это позволило нам в определении 1.4.11 "отсеять" часть слов, получаемых из начального символа. А именно, отбрасывается каждое слово, содержащее хотя бы один символ, не принадлежащий алфавиту .
Пример 1.4.13. Если  , то
, то 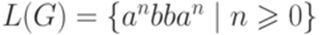 .
.
Определение 1.4.14. Две грамматики эквивалентны, если они порождают один и тот же язык.
Пример 1.4.15. Грамматика

и грамматика

эквивалентны.
Классы грамматик
Определение 1.5.1. Контекстной грамматикой (контекстно-зависимой грамматикой, грамматикой непосредственно составляющих, НС-грамматикой, грамматикой типа 1, context-sensitive grammar, phrase-structure grammar) называется порождающая грамматика, каждое правило которой имеет вид  , где
, где  ,
, 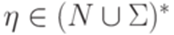 ,
,  ,
, 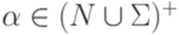 .
.
Пример 1.5.2. Грамматика

не является контекстной (последние три правила не имеют требуемого вида).
Определение 1.5.3. Контекстно-свободной грамматикой (бесконтекстной грамматикой, КС-грамматикой, грамматикой типа 2, context-free grammar) называется порождающая грамматика, каждое правило которой имеет вид  , где
, где  ,
,  .
.
Пример 1.5.4. Грамматика

является контекстной, но не контекстно-свободной (последние пять правил не имеют требуемого вида).
Определение 1.5.5. Линейной грамматикой (linear grammar) называется порождающая грамматика, каждое правило которой имеет вид  или
или  , где ,
, где ,  ,
,  ,
,  .
.
Грамматика

является контекстно-свободной, но не линейной (первые два правила не имеют требуемого вида).
Определение 1.5.7. Праволинейной грамматикой (рациональной грамматикой, грамматикой типа 3, right-linear grammar) называется порождающая грамматика, каждое правило которой имеет вид или  , где , , .
, где , , .
Пример 1.5.8. Грамматика

является линейной, но не праволинейной (первое правило не имеет требуемого вида).
Пример 1.5.9. Грамматика

праволинейная. Она порождает язык  .
.
Пример 1.5.10. Грамматика

праволинейная.
Пример 1.5.11. Грамматика

праволинейная. Обобщенный вариант языка, порождаемого этой грамматикой, используется в доказательстве разрешимости арифметики Пресбургера.
Определение 1.5.12. Правила вида  называются - правилами или эпсилон-правилами.
называются - правилами или эпсилон-правилами.
Лемма 1.5.13. Каждая праволинейная грамматика является линейной. Каждая линейная грамматика является контекстно-свободной. Каждая контекстно-свободная грамматика без -правил является контекстной грамматикой.
Определение 1.5.14. Классы грамматик типа 0, 1, 2 и 3 образуют иерархию Хомского (Chomsky hierarchy).
Определение 1.5.15. Язык называется языком типа 0 (контекстным языком, контекстно-свободным языком, линейным языком, праволинейным языком), если он порождается некоторой грамматикой типа 0 (соответственно контекстной грамматикой, контекстно-свободной грамматикой, линейной грамматикой, праволинейной грамматикой). Контекстно-свободные языки называются также алгебраическими языками.
Пример 1.5.16. Пусть дан произвольный алфавит
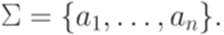
Тогда язык является праволинейным, так как он порождается грамматикой
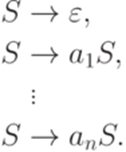
Два наиболее распространенных способа конечного задания формального языка - это грамматики и автоматы. Автоматами в данном контексте называют математические модели некоторых вычислительных устройств. В этой лекции рассматриваются конечные автоматы, соответствующие в иерархии Хомского праволинейным грамматикам. Более сильные вычислительные модели будут определены позже, в лекциях "10", "14" и "15". Термин "автоматный язык" закреплен за языками, распознаваемыми именно конечными автоматами, а не какими-либо более широкими семействами автоматов (например, автоматами с магазинной памятью или линейно ограниченными автоматами).
В разделе 2.1 определяются понятия конечного автомата (для ясности такой автомат можно называть недетерминированным конечным автоматом) и распознаваемого конечным автоматом языка. В следующем разделе дается другое, но эквивалентное первому определение языка, распознаваемого конечным автоматом. Оно не является необходимым для дальнейшего изложения, но именно это определение поддается обобщению на случаи автоматов других типов.
В разделе 2.3 доказывается, что тот же класс автоматных языков можно получить, используя лишь конечные автоматы специального вида (они читают на каждом такте ровно один символ и имеют ровно одно начальное состояние). Во многих учебниках конечными автоматами называют именно такие автоматы.
Целую серию классических результатов теории формальных языков составляют теоремы о точном соответствии некоторых классов грамматик некоторым классам автоматов. Первая теорема из этой серии, утверждающая, что праволинейные грамматики порождают в точности автоматные языки, доказывается в разделе 2.4.
Другая серия результатов связана с возможностью сузить некоторый класс грамматик, не изменив при этом класс порождаемых ими языков. Обычно в таком случае грамматики из меньшего класса называются грамматиками в нормальной форме. В разделе 2.5* формулируется результат такого типа для праволинейных грамматик. Сама эта теорема не представляет большого интереса, но аналогичные результаты, доказываемые позже для контекстно-свободных грамматик, используются во многих доказательствах и алгоритмах.
Не все конечные автоматы подходят для конструирования распознающих устройств, пригодных для практических приложений, так как в общем случае конечный автомат не дает точного указания, как поступать на очередном шаге, а разрешает продолжать вычислительный процесс несколькими способами. Этого недостатка нет у детерминированных конечных автоматов (частного случая недетерминированных конечных автоматов), определенных в разделе 2.6. В разделе 2.7 доказывается, что каждый автоматный язык задается некоторым детерминированным конечным автоматом.








