 2020-07-12
2020-07-12 86
86. 
Следовательно, факторные признаки влияют на результативный в пределах 72,25%. Это достаточное влияние. Согласно закону Парето степень влияния должна быть не меньше 80%.
Линейная модель, описывающая корреляционную зависимость, имеет следующий общий вид:

Используя данные таблиц, получаем систему нормальных уравнений
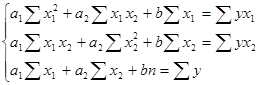

Решая систему, получаем: а1 = -0,07, а2 = -0,8, b = 16,52
Итак, искомое уравнение регрессии имеет вид: 
Найдем параметры уравнения регрессии упрощенным способом:
 ,
, 
 ,
, 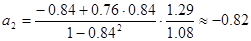
 ,
, 
Найдем среднюю ошибку аппроксимации. Для этого, подставив значения факторных признаков, соответствующих данному значению y в модель, получаем теоретические значения y *. Вычисления производим в таблице:
| Y | Х1 | Х2 | Yрасч | Y-Yрасч | е |
| 11,3 | 10 | 4,8 | 11,98 | -0,68 | 0,0602 |
| 14,2 | 9 | 3,5 | 13,09 | 1,11 | 0,0782 |
| 13,6 | 6 | 2,1 | 14,42 | -0,82 | 0,0603 |
| 14,3 | 3 | 2,7 | 14,15 | 0,15 | 0,0105 |
| 15,1 | 1 | 1,8 | 15,01 | 0,09 | 0,0060 |
| СУМИМ | 0,2151 |
Итак, значение средней ошибки аппроксимации равно е = 1/5*0,2151*100% = 4,3%, что говорит о хорошей точности модели.
Определим значения дельта – коэффициентов. Имеем:
 ,
, 
 ,
, 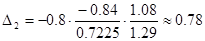
Сумма дельта – коэффициентов равна 1, следовательно, есть все основания полагать, что вычисления произведены верно. Итак, признак  влияет на признак Y в пределах 20%, а степень влияния признака Х2 равна 80%.
влияет на признак Y в пределах 20%, а степень влияния признака Х2 равна 80%.
Найдем величины средних коэффициентов эластичности:
 ,
, 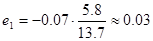
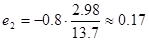
Таким образом, изменение признака Х1 на 1% влечет за собой изменение признака Y на 3%, а вследствие изменения признака X2, изменение признака Y составит 17%
Перейдем к модели с парной регрессией.
Поскольку одновременно минимум дельта-коэффициента и среднего коэффициента эластичности соответствует признаку X1, то он исключается из модели. Так как  , то связь признается линейной и тесной. Уравнение прямой линии регрессии найдем упрощенным способом
, то связь признается линейной и тесной. Уравнение прямой линии регрессии найдем упрощенным способом
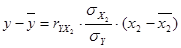 ,
,  ,
,

Задача 3. Деятельность предприятия в 2019 году характеризовалась данными, помещенными в таблицу:
| Месяцы | Варианты (показатели деятельности предприятия) | |||||||||
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Январь | 1,200 | 1000 | 25 | 10 | 0,50 | 7,300 | 500 | 79 | 15 | 5,172 |
| Февраль | 1,250 | 850 | 20 | 7 | 0,70 | 7,381 | 480 | 81 | 23 | 5,178 |
| Март | 1,300 | 930 | 35 | 6 | 1,40 | 7,560 | 600 | 83 | 25 | 5,200 |
| Апрель | 1,380 | 980 | 40 | 15 | 0,50 | 8,320 | 650 | 78 | 26 | 5,215 |
| Май | 1,400 | 970 | 42 | 20 | 0,40 | 8,403 | 540 | 77 | 27 | 5,322 |
| Июнь | 1,390 | 953 | 35 | 4 | 0,90 | 7,700 | 800 | 95 | 32 | 5,417 |
| Июль | 1,370 | 940 | 30 | 10 | 0,30 | 7,050 | 560 | 115 | 44 | 5,417 |
| Август | 1,350 | 948 | 25 | 15 | 0,20 | 7,400 | 565 | 123 | 50 | 5,500 |
| Сентябрь | 1,500 | 997 | 150 | 95 | 0,85 | 7,703 | 810 | 149 | 76 | 5,800 |
| Октябрь | 1,680 | 1000 | 200 | 73 | 0,71 | 7,800 | 815 | 94 | 85 | 6,300 |
| Ноябрь | 1,900 | 1320 | 210 | 80 | 0,62 | 8,500 | 821 | 96 | 87 | 6,512 |
| Декабрь | 2,000 | 1450 | 215 | 97 | 0,95 | 9,230 | 930 | 100 | 92 | 7,020 |
Вариант 5. Уровень y – количество прогулов без уважительных причин, чел. час.
Необходимо:
1. Произвести все необходимые вычисления;
2. Построить линейную, параболическую и показательную функции тренда(результаты представить графически);
3. Найти индексы сезонности.
4. Построить модель неслучайной составляющей в виде а) произведения функции тренда и индексов сезонности (результаты представить графически), б) тригонометрического ряда (m= 1, 2, 3) (результаты представить графически);
5. Оценить точность построенных моделей неслучайной составляющей;
6. По наиболее точной модели осуществить прогноз своего показателя на январь, февраль и март 2020 года.
Решение
| Месяцы | t | t | прогулы, Y | Yt | t^2 |
| Январь | 1 | -6 | 0,5 | -3 | 36 |
| Февраль | 2 | -5 | 0,7 | -3,5 | 25 |
| Март | 3 | -4 | 1,4 | -5,6 | 16 |
| Апрель | 4 | -3 | 0,5 | -1,5 | 9 |
| Май | 5 | -2 | 0,4 | -0,8 | 4 |
| Июнь | 6 | -1 | 0,9 | -0,9 | 1 |
| Июль | 7 | 1 | 0,3 | 0,3 | 1 |
| Август | 8 | 2 | 0,2 | 0,4 | 4 |
| Сентябрь | 9 | 3 | 0,85 | 2,55 | 9 |
| Октябрь | 10 | 4 | 0,71 | 2,84 | 16 |
| Ноябрь | 11 | 5 | 0,62 | 3,1 | 25 |
| Декабрь | 12 | 6 | 0,95 | 5,7 | 36 |
| Сумма | 0 | 8,03 | -0,41 | 182 | |
| ср знач | 0,669 | -0,034 |
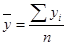 ,
, 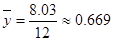
Нахождение параметров уравнения прямой линии тренда

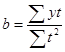 ,
, 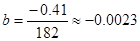
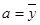 ,
, 
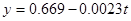
Интерпретация параметров тренда.
Коэффициент регрессии (b) в линейном тренде показывает средний за период цепной абсолютный прирост уровней ряда. В нашем примере b = -0,0023, следовательно среднегодовое количество прогулов без уважительной причины в среднем за год снижается на 0,0023 чел/час. Свободный член (а) в линейном тренде выражает начальный уровень ряда в момент (период времени) t = 0. В нашей нумерации t = 0 приходится на период времени между июнь и июль, что несколько затрудняет его интерпретацию. В нашем случае а =0,669 чел.час. – это среднее число прогулов за вторую половину июня и первую половину июля.
С помощью этого уравнения найдем выравненные уровни и рассчитаем стандартную ошибку уравнения регрессии Syx.

| t | прогулы, Y | Yрасч | (Y-Yрасч)^2 | |
| -6 | 0,5 | 0,683 | 0,033 | |
| -5 | 0,7 | 0,681 | 0,000 | |
| -4 | 1,4 | 0,678 | 0,521 | |
| -3 | 0,5 | 0,676 | 0,031 | |
| -2 | 0,4 | 0,674 | 0,075 | |
| -1 | 0,9 | 0,671 | 0,052 | |
| 1 | 0,3 | 0,667 | 0,134 | |
| 2 | 0,2 | 0,664 | 0,216 | |
| 3 | 0,85 | 0,662 | 0,035 | |
| 4 | 0,71 | 0,660 | 0,003 | |
| 5 | 0,62 | 0,658 | 0,001 | |
| 6 | 0,95 | 0,655 | 0,087 | |
| Сумма | 0 | 8,03 | 8,03 | 1,19 |

Чем меньше стандартная ошибка, тем лучше подобрана модель тренда. Сравнение Syx , рассчитанных для различных моделей дает возможность выбрать лучшую из них.
Показательная функция:  .
.
Линеаризация показательной функции достигается путем ее логарифмирования:
 .
.
Это – линейное уравнение. Правда, при определении его параметров мы получим натуральные логарифмы a и b.
Расчет по данным нашего примера даст следующие результаты (при условии, что  ):
):
| t | lnY | t*lnY | t^2 | Yрасч | (Y-Yрасч)^2 |
| -6 | -0,693 | 4,159 | 36,000 | 0,600 | 0,010 |
| -5 | -0,357 | 1,783 | 25,000 | 0,599 | 0,010 |
| -4 | 0,336 | -1,346 | 16,000 | 0,598 | 0,644 |
| -3 | -0,693 | 2,079 | 9,000 | 0,596 | 0,009 |
| -2 | -0,916 | 1,833 | 4,000 | 0,595 | 0,038 |
| -1 | -0,105 | 0,105 | 1,000 | 0,594 | 0,094 |
| 1 | -1,204 | -1,204 | 1,000 | 0,592 | 0,085 |
| 2 | -1,609 | -3,219 | 4,000 | 0,590 | 0,152 |
| 3 | -0,163 | -0,488 | 9,000 | 0,589 | 0,068 |
| 4 | -0,342 | -1,370 | 16,000 | 0,588 | 0,015 |
| 5 | -0,478 | -2,390 | 25,000 | 0,587 | 0,001 |
| 6 | -0,051 | -0,308 | 36,000 | 0,586 | 0,133 |
| 0 | -6,2759 | -0,36455 | 182 | 7,113 | 1,259 |
 ,
, 


Построим квадратичную модель полученных данных 








