 2014-09-02
2014-09-02 920
920Рассмотренные выше разновидности ШР (ISA, MCA, EISA) имеют общий недостаток – сравнительно низкое быстродействие. Быстродействие и разрядность процессоров и микросхем памяти (а следовательно, и локальной системной шины) возрастали, а характеристики ШР улучшались "экстенсивно", в основном за счет увеличения их разрядности. Для ряда ПУ, быстродействие которых определяется "человеческим фактором", например, клавиатуры, «мыши», высокого быстродействия ШР и не требуется. Однако при наличии таких ПУ, как жесткие диски, видеосистемы и т.д., низкое быстродействие ШР оказывает самое непосредственное влияние на производительность системы в целом. Проблема быстродействия ШР встала наиболее остро с появлением графических пользовательских интерфейсов, таких как Windows, при работе с которыми возникает потребность в передаче и обработке очень больших массивов данных.
Достаточно очевидным решением этой проблемы является осуществление обмена между наиболее быстродействующими ПУ и ядром ЭВМ не через ШР, а через дополнительную быстродействующую магистраль, выходящую непосредственно на шину процессора. В этом случае ПУ получают доступ к самой быстродействующей шине компьютера наряду с внешним кэш. Такая конфигурация получила название локальной шины расширения или просто локальной шины (local bus). Подключение локальной шины такого типа иллюстрируется упрощенной схемой на рис. 10.2.
Первая локальная шина появилась в 1992 году в результате совместных усилий фирм Dell Computer и Intel. Хотя система оказалась поначалу весьма дорогостоящей, она продемонстрировала преимущества подключения видеосистемы к той точке, где можно было воспользоваться высоким быстродействием шины процессора. Этот первый вариант локальной шины был официально назван локальной шиной ввода/вывода I486 (I486 local bus I/O). К концу 1992 года стоимость компьютеров с локальной шиной стала снижаться, и многие фирмы начали производить аналогичные системы.
Для организации в компьютере локальной шины необязательно устанавливать слоты расширения: адаптер устройства, использующего локальную шину, можно смонтировать непосредственно на системной плате. В первых компьютерах с локальной шиной использовался именно такой вариант.
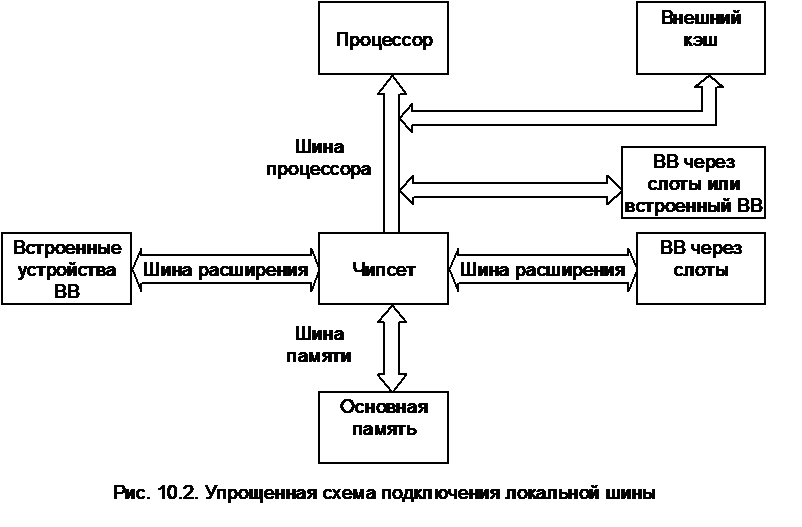
Локальная шина не заменяла собой прежние стандарты, а дополняла их. Основными шинами расширения в компьютере по-прежнему оставались ISA или EISA, но к ним добавлялся один или несколько слотов локальной шины. При этом сохранялась совместимость со старыми платами расширения, а быстродействующие адаптеры устанавливались в слоты локальной шины, реализуя при этом все свои возможности.
Компьютеры с локальной шиной стали особенно популярны среди пользователей Windows и OS/2, поскольку в слоты локальной шины можно было установить
32-разрядные платы так называемых видеоускорителей, которые значительно увеличивали быстродействие системы при работе с графическими изображениями. Производительность Windows и OS/2 существенно снижалась из-за ограничений, существующих даже в лучших платах VGA, подключаемых к шинам ISA или EISA. Обычные платы VGA могли выводить на экран до 600 000 точек в секунду, в то время как видеоадаптеры, соединенные с локальной шиной, по утверждениям изготовителей, за то же время выводили 50-60 млн. точек. В реальных условиях быстродействие, конечно, ниже, но разница все равно оказывалась существенной.
принципы организации систем
прямого доступа к памяти
Материал, изложенный в предыдущих разделах, предполагал, что передача данных между ОП и ПУ, как правило, осуществляется с помощью процессора. Это так называемая программно-управляемая передача данных (программно-управляемый ввод/вывод ), которая осуществляется при непосредственном участии и под управлением процессора. В англоязычной литературе – Programmed Input/Output (PIO). Процессор при этом выполняет соответствующую процедуру ввода/вывода (ВВ), являющуюся либо частью основной программы, либо оформленную как подпрограмма. Данные между ОП и ПУ пересылаются через процессор. Операции ВВ инициируются текущей командой программы или запросом прерывания от ПУ. Это соответствует принципам функционирования классической неймановской машины, описание которой приведено в гл.1. Более подробно процедура программно-управляемой передачи данных (программно-управляемого ВВ) рассмотрена в гл. 9.
Между тем такой вариант обмена между ОП и ПУ во многих случаях является далеко не самым оптимальным, а иногда вообще невозможным. Причин тому несколько. Рассмотрим очень коротко основные из них.
· При программно-управляемом ВВ процессор "отвлекается" от выполнения основной программы решения задачи. Операции ВВ достаточно просты, чтобы эффективно загружать логически сложную быстродействующую аппаратуру процессора. В результате при использовании программно-управляемого ВВ снижается производительность ЭВМ в целом.
· При пересылке любой единицы данных (байт, слово) процессор выполняет достаточно много команд, чтобы обеспечить буферизацию данных, преобразование форматов, подсчет количества переданных единиц данных, формирование адресов памяти и регистров ПУ. В результате скорость передачи данных при программно-управляемом ВВ (т.е. через процессор) может оказаться недостаточной для работы с высокоскоростными ПУ, например с накопителями на жестких дисках, видеосистемами, быстродействующими аналого-цифровыми и цифро-аналоговыми преобразователями различного назначения, и т.д.
· Большинство современных сложных ПУ, таких как видеосистемы, сетевые карты, жесткие диски и т.д., осуществляют обмен с ОП целыми блоками информации. В этом случае перечисленные выше непроизводительные временные затраты процессора становятся особенно существенными.
· Обмен в режиме прерывания, несмотря на все свои достоинства (см. гл. 6), требует еще помимо перечисленных выше непроизводительных временных затрат время на сохранение вектора состояния текущей программы в стеке и его последующего восстановления. Кроме того, прерывание в большинстве случаев возможно только после завершения текущей команды.
Несмотря на широкое использование программно-управляемого ВВ, для ускорения операций обмена данными между ОП и ПУ и разгрузки процессора от управления этими операциями в современных ЭВМ используется специальный режим обмена, получивший название режим прямого доступа к памяти или просто прямой доступ к памяти (ПДП). В англоязычной литературе – Direct Memory Access (DMA). Ниже, в зависимости от контекста излагаемого материала, будут употребляться обе аббревиатуры – ПДП и DMA.
Прямым доступом к памяти называется режим, при котором обмен данными между ОП и регистрами ПУ осуществляется без участия центрального процессора за счет специальных, внешних по отношению к нему, электронных схем. Простейший вариант такого обмена рассмотрен в гл. 9.
Введение режима ПДП (реализация каналов ПДП) всегда усложняет аппаратную часть ЭВМ, однако позволяет повысить скорость выполнения операций обмена ОП-ПУ, разгружает центральный процессор от обслуживания операций ВВ, повышает общую производительность ЭВМ. При наличии кэш-памяти достаточного объема режим ПДП в ряде случаев позволяет реализовать параллельное выполнение операций обмена и обработку команд текущей программы процессором, что также повышает общую производительность ЭВМ. Более того, наличие механизма прямого доступа к памяти позволяет поддерживать многопроцессорность вычислительной системы. На последнем моменте необходимо остановиться более подробно.
Дело в том, что термин ПДП (как и DMA), используемый при изложении материала настоящего раздела, в общем случае не совсем точно отражает суть процессов, происходящих в ЭВМ. Точнее, прямой доступ к памяти (к ОП) является только частным случаем организации процедур доступа к системной магистрали со стороны множества устройств, в том числе и процессоров. Под доступом к системной магистрали понимается возможность какого-либо устройства, имеющего соответствующее аппаратно-программное обеспечение (ведущее устройство, интеллектуальное устройство магистрали), занимать на какое-то время системную магистраль и полностью управлять ею, вырабатывая все необходимые управляющие сигналы. При этом могут осуществляться связи не только ОП-ПУ, но и ПУ-ПУ. Между тем смысл понятия "память" можно расширить и понимать под памятью не только ОП, но и адресуемые регистры ПУ. В этом случае использование термина ПДП (как и DMA) будет вполне корректно.
Следует иметь в виду, что термин "периферийное устройство (ПУ)" здесь используется достаточно условно. В англоязычной литературе ведущее устройство магистрали, инициирующее обмен, принято называть master. Устройство, к которому обращается master, является подчиненным, и его принято называть slave. Таким образом, более правильно говорить о реализации связей master-slave (M-S), а не ПУ-ПУ или ОП-ПУ. Мастером может быть только интеллектуальное устройство, имеющее средства управления магистралью (СУМ), которые, как минимум, должны "уметь" формировать и модифицировать адреса обращения, вести контроль за размером переданного блока информации и генерировать управляющие сигналы магистрали. Между тем в зависимости от текущего состояния вычислительного процесса одно и то же интеллектуальное устройство магистрали может выступать и как master, и как slave. Устройства магистрали, не имеющие СУМ, всегда являются подчиненными, т.е. slave.
Естественно, что предоставление магистрали в распоряжение того или иного устройства (захват магистрали) может происходить только на приоритетной основе. Эта процедура получила название арбитраж магистрали, а устройство, ее реализующее, – арбитр магистрали. В ряде случаев арбитр может строиться как отдельное устройство, размещенное на системной магистрали. В других случаях арбитраж магистрали выполняет сам процессор. Наличие процедуры арбитража позволяет размещать на системной магистрали несколько интеллектуальных устройств, в том числе и процессоров. В соответствии с принятой дисциплиной обслуживания (арбитража) каждое из них будет получать в свое распоряжение системную магистраль и устанавливать связи как с ОП, так и с регистрами других устройств магистрали. Следует отметить при этом, что в процедуре арбитража всегда предусматриваются средства, предотвращающие монопольный захват магистрали одним устройством. Часть этих средств может быть сосредоточена в арбитре, другая часть может быть распределена между устройствами магистрали, использующими режим ПДП.








