2015-02-24
2015-02-24 4515
4515Проверка соответствия модели реальному процессу строится на основе анализа временного ряда остатков, полученного после удаления неслучайной составляющей. Отметим, что в случае, когда временной ряд остатков обнаруживает некоторые закономерности, необходимо подбирать модель для остатков и тогда на предмет адекватности анализируется временной ряд финальной остаточной компоненты.
Временной ряд остатков получается как разность фактических и полученных по модели уровней (в случае аддитивной модели временного ряда): 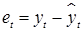 .
.
Временной ряд остатков должен представлять собой реализации значений случайной величины, имеющей нормальное распределение с нулевым математическим ожиданием и конечной дисперсией и остатки не должны быть линейно зависимы друг от друга (автокоррелированы). Т.е. ряд остатков должен представлять собой белый шум (имеющий нормальное распределение).
Для проверки нормальности распределения остатков используют графический способ: построение гистограммы остатков с наложенной нормальной плотностью, позволяющей визуально оценить симметричность и близость к нормальному закону распределения; квантиль-квантильный график остатков в зависимости от ожидаемого нормального значения − остатки должны «лежать» на прямой ожидаемого нормального распределения. Также пакеты прикладных программ позволяют тестировать на нормальность с помощью критериев согласия Пирсона, Колмогорова-Смирнова, Шапиро-Уилка и др.
Тестирование на отсутствие в остатках автокорреляции удобно осуществлять с помощью статистики Бокса-Пирса или ее модификации − Льюнга-Бокса. Для проверки на автокорреляцию первого порядка может быть использован широко известный критерий Дарбина-Уотсона[4].
Важнейшим показателем качества модели является ее точность, оцениваемая по значению ошибки, которая может быть получена либо как ошибка ретроспективного прогноза, либо как ошибка прогноза, полученного по контрольной части выборки; либо как разность между прогнозным и фактически реализовавшимся значением.
Для сравнения различных альтернативных прогнозов необходим показатель качества прогноза. Используются следующие меры качества построенных прогнозов.
Коэффициент несовпадения ретроспективного предсказания Pt с наблюдавшимися значениями At, предложенный Тейлом:
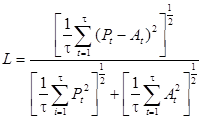 ,
,
где t − горизонт прогнозирования.
Коэффициент легко вычисляется, и его значения принадлежат отрезку [0, 1], причем на концах отрезка он имеет следующую содержательную интерпретацию: при L =0 – отличное качество прогноза; при L =1 – плохое качество прогноза. Может применяться как в случае статистического, так и в случае качественного прогнозирования.
Среднеабсолютная процентная ошибка (Mean Absolute Percentage Error):
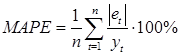 .
.
Показатель MAPE, как правило, используется для сравнения точности прогнозов разнородных объектов прогнозирования, поскольку он характеризует относительную точность прогноза.
Для прогнозов высокой точности MAPE <10%, хорошей − 10%< MAPE <20%, удовлетворительной − 20%< MAPE <50%, неудовлетворительной − MAPE >50%.
Целесообразно пропускать значения ряда, для которых yt = 0.
Средняя процентная ошибка (Mean Percentage Error) и средняя ошибка (Mean Error). MPE характеризует относительную степень смещенности прогноза. При условии, что потери при прогнозировании, связанные с завышением фактического будущего значения, уравновешиваются занижением, идеальный прогноз должен быть несмещенным, и обе меры должны стремиться к нулю. Средняя процентная ошибка не определена при нулевых данных и не должна превышать 5%:
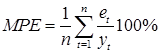 .
.
Абсолютное смещение характеризует средняя ошибка:
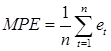 .
.
Средний квадрат ошибки (Mean Square Error) и сумма квадратов (Sum Square Error). Соответственно:
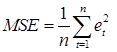 и
и 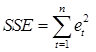 .
.
Чаще всего MSE и SSE используются при выборе оптимального метода прогнозирования. В большинстве пакетов программ по прогнозированию именно эти два показателя принимаются в качестве критериев при оптимальном выборе параметров моделей. Часто также используется для проведения сравнительной оценки моделей средняя квадратическая ошибка:
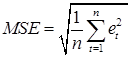 ,
,
причем в знаменателе может стоять величина (n − q), где q − число оцениваемых в модели параметров.