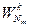2015-05-06
2015-05-06 475
475Вернемся к рассмотрению процедуры БПФ. Мы говорили, что на каждой ступени вычисляются группы однородных операций:
- умножение на матрицу D поворачивающих множителей;
- умножение на матрицу 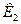 ;
;
- перестановка элементов вектора результатов.
Основная сложность в записи алгоритма БПФ состоит именно в описании перестановок элементов вектора.
Если рассмотреть граф БПФ (например, для N=8, рис3.1), то можно увидеть, что на первой итерации как бы независимо отрабатывается 4 фрагмента исходного вектора, содержащие по 2 элемента: такие фрагменты назовем подвекторами. В данном случае это подвектор X={x0, x4}; X={x1, x5}; X={x2, x6}; X={x3, x7}. На второй итерации отрабатывается 2 подвектора по 4 элемента, а на третий - один вектор из восьми элементов.
Таким образом, суть алгоритма БПФ состоит в разбиении на подвектора по 2 элемента, их независимой обработке, и формированию из промежуточных подвекторов вдвое большей длины (очевидно, что число таких подвекторов уменьшается от итерации к итерации), что выполняется до тех пор, пока не образуется один вектор длиной N элементов.
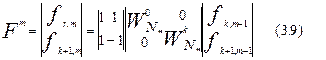 |
Подобная процедура может быть описана как [11]:
где l=2m-1, 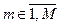 , k=(n)mod l,
, k=(n)mod l, 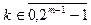 ,
, 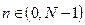 - текущий индекс элемента вектора, k - соответствует номеру Б0 при обработке подвектора,
- текущий индекс элемента вектора, k - соответствует номеру Б0 при обработке подвектора, 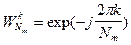 ,
, 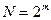 - длина подвектора, причём для m=0 вектор
- длина подвектора, причём для m=0 вектор 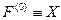 . Номер обрабатываемого на данной итерации блока данных определяется целой частью (n)mod l
. Номер обрабатываемого на данной итерации блока данных определяется целой частью (n)mod l
Выражение (3.9) определяет обработку отдельного, но любого подвектора на каждой итерации из общего их числа 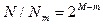 . Индекс n определяется следующим образом:
. Индекс n определяется следующим образом:
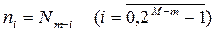 ,
,
где 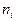 - начальный индекс для i-го подвектора.
- начальный индекс для i-го подвектора.
В свою очередь, (3.9) может быть переписано в виде системы из двух уравнений:
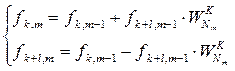 (8.10)
(8.10)
Это выражение соответствует базовой операции, для которой указаны правила формирования текущих индексов по “входным” и “выходным” бабочкам, а также правила вычисления поворачивающего множителя