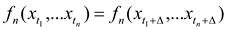2015-04-20
2015-04-20 1197
1197В двухшаговом методе наименьших квадратов по сути каждое уравнение структурной формы оценивается независимо от других уравнений, то есть не учитывается возможная взаимосвязь случайных ошибок уравнений структурной формы между собой. В трёхшаговом методе наименьших квадратов (ТМНК, 3SLS) первые два шага совпадают с ДМНК и добавляется:
Шаг 3. На основе ДМНК-оценок остатков структурных уравнений получают оценку ковариационной матрицы вектора случайных ошибок системы и с её помощью получают новую оценку коэффициентов с помощью обобщенного метода наименьших квадратов.
При наличии корреляций между уравнениями ТМНК-оценки теоретически должны быть лучше ДМНК-оценок.
55. Примеры одновременных систем регрессионных уравнений
При статистическом моделировании экономических ситуаций часто необходимо построение систем уравнений, когда одни и те же переменные в различных регрессионных уравнениях могут одновременно выступать, с одной стороны, в роли результирующих, объясняемых переменных, а с другой стороны - в роли объясняющих переменных. Такие системы уравнений принято называть системами одновременных уравнений. При этом в соотношения могут входить переменные, относящиеся не только к текущему периоду t, но и к предшествующим периодам. Такие переменные называются лаговыми. Переменные за предшествующие годы обычно выступают в качестве объясняющих переменных.
В качестве иллюстрации приведем пример из экономики. Рассмотрим модель спроса и предложения. Как известно, спрос D на некоторый продукт зависит от его цены р. От этого же параметра, но с противоположным по знаку коэффициентом, зависит и предложение этого продукта. Силы рыночного механизма формируют цену таким образом, что спрос и предложение уравниваются. Нам нужно построить модель описанной ситуации. Для этого имеются данные об уровне равновесных цен и спросе (который равен предложению). Представленную ситуацию можно формализовать в виде следующей линейной модели:
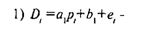 (3.1)
(3.1)
спрос пропорционален цене с коэффициентом пропорциональности a1<0, т.е. связь отрицательная;
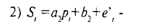 (3.2)
(3.2)
предложение пропорционально цене с коэффициентом пропорциональности а2>0, т.е. связь положительная;
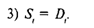 (3.3)
(3.3)
Здесь еl, е'l\, (l=1,...,n) - ошибки модели, имеющие нулевое математическое ожидание.
Первые два из представленных уравнений, если их рассматривать отдельно, могут показаться вполне обычными. Мы можем определить коэффициенты регрессии для каждого из этих уравнений. Но в этом случае остается открытым вопрос о равенстве спроса и предложения, т.е. может не выполняться третье равенство, в котором спрос выступает в качестве зависимой переменной. Поэтому расчет параметров отдельных уравнений в такой ситуации теряет смысл.
56. Экономический анализ построенного регрессионного уравнения.
57. Приростный анализ регрессионных уравнений
58. Понятие фиктивных переменных. Учет качественных факторов
Метод сезонных фиктивных переменных относится к методам моделирования сезонных компонент временного ряда. Суть данного метода заключается в построении модели регрессии, которая наряду с фактором времени включает сезонные фиктивные переменные.
Фиктивной переменной (dummy variable) называется атрибутивный или качественный фактор, представленный с помощью определённого цифрового кода.
Моделью регрессии с переменной структурой называется модель регрессии, включающая в качестве факторной (факторных) переменных фиктивную переменную.
Предположим, что задача состоит в исследовании временного ряда Xij, где i – это номер сезона (периода времени внутри года, например, месяца или квартала),
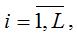
L – число сезонов в году, j – номер года,
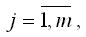
m – общее количество лет. Количество уровней исходного временного ряда равно n=L*m.
При построении модели регрессии с переменной структурой необходимо учитывать, что число сезонных фиктивных переменных всегда должно быть на единицу меньше сезонов внутри года, т. е. должно быть равно величине L-1. Например, при моделировании годовых данных модель регрессии помимо фактора времени должна содержать одиннадцать фиктивных компонент (12-1). При моделировании поквартальных данных модель регрессии должна содержать три фиктивные компоненты (4-1) и т. д.
Каждому из сезонов соответствует определённое сочетание фиктивных переменных. Сезон, для которого значения всех фиктивных переменных равны нулю, является базой сравнения. Для остальных сезонов одна из фиктивных переменных принимает значение, равное единице. Например, если имеются поквартальные данные, то значения фиктивных переменных D2,D3,D4 будут принимать следующие значения для каждого из кварталов:
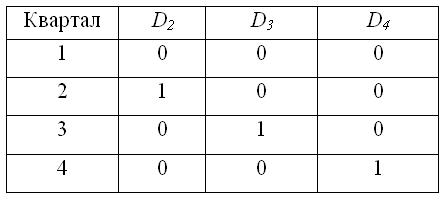
Тогда общий вид модели регрессии с переменной структурой будет иметь вид:
yt=β0+ β1*t+δ2*D2+δ3*D3+δ4*D4+εt.
Данная модель регрессии представляет собой одну из разновидностей аддитивной модели временного ряда.
На основе общей модели регрессии с переменной структурой можно составить базисную модель или модель тренда для первого квартала:
yt=β0+ β1*t+εt.
Также на основе общей модели регрессии с переменной структурой можно составить частные модели регрессии:
1) частная модель регрессии для второго квартала:
yt=β0+ β1*t+δ2+εt;
2) частная модель регрессии для третьего квартала:
yt=β0+ β1*t+δ3+εt;
3) частная модель регрессии для четвёртого квартала:
yt=β0+ β1*t+δ4+εt.
Данные частные модели регрессии отличаются друг от друга только на величину свободного члена δi.
Коэффициент β1 характеризует среднее абсолютное изменение уровней временного ряда под влиянием основной тенденции.
Сезонная компонента для каждого сезона рассчитывается как разность между средним значением свободных членов всех частных моделей регрессий и значением постоянного члена одной из моделей.
Среднее значение свободных членов всех частных моделей регрессий рассчитывается по формуле:
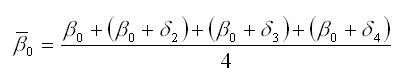
Для поквартальных данных оценка сезонных отклонений осуществляется по формулам:
1) оценка сезонного отклонения для первого квартала:
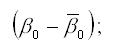
2) оценка сезонного отклонения для второго квартала:
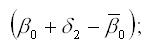
3) оценка сезонного отклонения для третьего квартала:
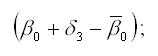
4) оценка сезонного отклонения для четвёртого квартала:
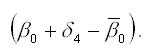
Сумма сезонных отклонений должна равняться нулю.
59. Тест Чоу на структурные изменения.Общее представление об анализе временных рядов и задач, решаемых на его основе.
60. Общее представление об анализе врем рядов…..
61. Общие положения о компонентном анализе временных рядов.
Предположим, что на основе собранных данных была построена модель регрессии. Перед исследователем стоит задача о том, стоит ли вводить в полученную модель дополнительные фиктивные переменные или базисная модель является оптимальной. Данная задача решается с помощью метода или теста Чоу. Он применяется в тех ситуациях, когда основную выборочную совокупность можно разделить на части или подвыборки. В этом случае можно проверить предположение о большей эффективности подвыборок по сравнению с общей моделью регрессии.
Будем считать, что общая модель регрессии представляет собой модель регрессии модель без ограничений. Обозначим данную модель через UN. Отдельными подвыборками будем считать частные случаи модели регрессии без ограничений. Обозначим эти частные подвыборки как PR.
Введём следующие обозначения:
PR1 – первая подвыборка;
PR2 – вторая подвыборка;
ESS(PR1) – сумма квадратов остатков для первой подвыборки;
ESS(PR2) – сумма квадратов остатков для второй подвыборки;
ESS(UN) – сумма квадратов остатков для общей модели регрессии.
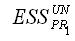
– сумма квадратов остатков для наблюдений первой подвыборки в общей модели регрессии;
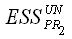
– сумма квадратов остатков для наблюдений второй подвыборки в общей модели регрессии.
Для частных моделей регрессии справедливы следующие неравенства:
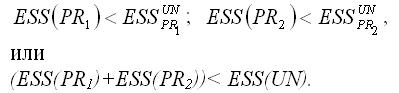
Условие (ESS(PR1)+ESS(PR2))= ESS(UN) выполняется только в том случае, если коэффициенты частных моделей регрессии и коэффициенты общей модели регрессии без ограничений будут одинаковы, но на практике такое совпадение встречается очень редко.
Основная гипотеза формулируется как утверждение о том, что качество общей модели регрессии без ограничений лучше качества частных моделей регрессии или подвыборок.
Альтернативная или обратная гипотеза утверждает, что качество общей модели регрессии без ограничений хуже качества частных моделей регрессии или подвыборок
Данные гипотезы проверяются с помощью F-критерия Фишера-Снедекора.
Наблюдаемое значение F-критерия сравнивают с критическим значением F-критерия, которое определяется по таблице распределения Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n-2m-2.
Наблюдаемое значение F-критерия рассчитывается по формуле:где ESS(UN)– ESS(PR1)– ESS(PR2) – величина, характеризующая улучшение качества модели регрессии после разделения её на подвыборки;
m – количество факторных переменных (в том числе фиктивных);
n – объём общей выборочной совокупности.
При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл>Fкрит, то основная гипотеза отклоняется, и качество частных моделей регрессии превосходит качество общей модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т.е. Fнабл≤Fкрит, то основная гипотеза принимается, и разбивать общую регрессию на подвыборки не имеет смысла.
Если осуществляется проверка значимости базисной регрессии или регрессии с ограничениями (restricted regression), то выдвигается основная гипотеза вида:
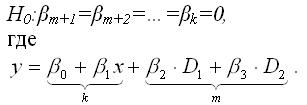
Справедливость данной гипотезы проверяется с помощью F-критерия Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы свободы k1=m+1 и k2=n–k–1.
Наблюдаемое значение F-критерия преобразуется к виду:
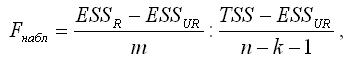
При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл›Fкрит, то основная гипотеза отклоняется, и в модель регрессии необходимо вводить дополнительные фиктивные переменные, потому что качество модели регрессии с ограничениями выше качества базисной или ограниченной модели регрессии.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл≤Fкрит, то основная гипотеза принимается, и базисная модель регрессии является удовлетворительной, вводить в модель дополнительные фиктивные переменные не имеет смысла.
62.Методы определения тренда в структуре временного ряда.
Временным рядом называется ряд наблюдаемых значений изучаемого показателя, расположенных в хронологическом порядке или в порядке возрастания времени.
Отдельно взятый временной ряд можно представить как выборочную совокупность из бесконечного ряда значений показателей во времени.
Уровнями временного ряда называются наблюдения
из которых состоит данный ряд.
Временной ряд называется моментным рядом, если уровень временного ряда фиксирует значение изучаемого показателя на определённый момент времени.
Временной ряд называется интервальным рядом, если уровень временного ряда характеризует значение показателя за определённый период времени.
Временной ряд называется производным рядом, если уровни ряда представлены в виде производных величин (средних или относительных показателей).
Исследование данных, представленных в виде временных рядов, преследует две основные цели:
1) характеристика структуры временного ряда;
2) прогнозирование будущих уровней временного ряда на основании прошлых и настоящих уровней.
Достижение поставленных целей возможно с помощью идентификации модели временного ряда.
Идентификацией модели временного ряда называется процесс выявления основных компонент, которые содержит изучаемый временной ряд.
Временные ряды могут содержать два вида компонент – систематическую и случайную составляющие.
Систематическая составляющая временного ряда является результатом воздействия постоянно действующих факторов.
Выделяют три основных систематических компоненты временного ряда:
1) тренд;
2) сезонность;
3) цикличность.
Трендом называется систематическая линейная или нелинейная компонента, изменяющаяся во времени.
Сезонностью называются периодические колебания уровней временного ряда внутри года.
Цикличностью называются периодические колебания, выходящие за рамки одного года. Промежуток времени между двумя соседними вершинами или впадинами в масштабах года определяют как длину цикла.
Систематические составляющие характеризуются тем, что они могут одновременно присутствовать во временном ряду.
Случайной составляющей называется случайный шум или ошибка, которая воздействует на временной ряд нерегулярно.
К основным причинам, по которым возникает случайный шум, относят факторы резкого и внезапного действия, а также действия текущих факторов.
Катастрофическими колебаниями называется случайный шум, в основе возникновения которого лежат факторы резкого и внезапного действия.
Шум, в основе возникновения которого лежит действие текущих факторов, может быть связан также с ошибками наблюдений.
Отдельный уровень временного ряда обозначается как yt. Его можно представить в виде функции от основных компонент временного ряда следующим образом:
yt=f(T,S,C,ε),
где T – это трендовая компонента,
S – это сезонная компонента,
C – это циклическая компонента,
ε – случайный шум.
Существует несколько основных моделей временных рядов, к которым относятся:
1) аддитивная модель временного ряда, в которой компоненты представляют собой слагаемые:
yt=Tt+St+Ct+εt;
2) мультипликативная модель временного ряда, в которой компоненты представляют собой сомножители:
yt=Tt*St*Ct*εt;
3) комбинированная модель временного ряда:
yt=Tt*St*Ct+εt.
63.Метод выделения трендовой составляющей во временном ряду на основе подбора гладких функций.
64.Метод скользящих средних для выделения тренда.
Наличие во временном ряду трендовой компоненты не всегда можно определить с помощью графика. Поэтому для выявления этой компоненты используются специальные критерии проверки гипотезы о существовании тренда во временном ряду.
Рассмотрим следующие критерии проверки гипотезы о существовании тренда во временном ряду:
1) критерий, основанный на сравнении средних уровней временного ряда;
2) критерий «восходящих и нисходящих» серий;
3) критерий серий, основанный на медиане выборочной совокупности.
При проверке гипотезы о существовании тренда во временном ряду с помощью критерия, основанного на сравнении средних уровней, временной ряд из N наблюдений делится на две равные части. Объём первой части yi равен
и объём второй части yj равен
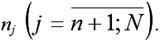
Обе части временного ряда рассматриваются как самостоятельные выборочные совокупности, подчиняющиеся нормальному закону распределения.
Для каждой из выборок yi и yj рассчитываются следующие выборочные характеристики:
1) средние арифметические значения:
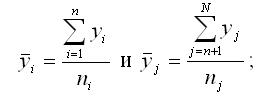
2) выборочные дисперсии:
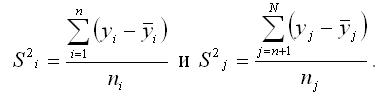
При проверке предположения о наличии во временном ряду трендовой компоненты выдвигается основная гипотеза о равенстве генеральных средних для двух образованных выборочных совокупностей:
H0:μi=μj.
Альтернативной или обратной является гипотеза о неравенстве генеральных средних для двух образованных выборочных совокупностей:
H0:μi≠μj.
Основная гипотеза вида H0:μi=μj проверяется при справедливости предположения о равенстве генеральных дисперсий:
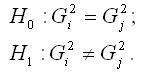
Гипотеза о равенстве дисперсий проверяется с помощью F-критерия Фишера.
Наблюдаемое значение F-критерия сравнивают с критическим значением F-критерия, которое определяется по таблице распределения Фишера-Снедекора.
Критическое значение F-критерия Фишера определяется по таблице распределения Фишера-Снедекора в зависимости от уровня значимости а и двух степеней свободы
k1=n–1 и k2=N–n–2.
Наблюдаемое значение F-критерия при проверке основной гипотезы вида
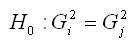
определяется по формуле:
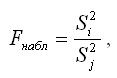
при условии, что
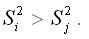
При проверке выдвинутых гипотез возможны следующие ситуации.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) больше критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т. е. Fнабл>Fкрит, то основная гипотеза отклоняется.
Если наблюдаемое значение F-критерия (вычисленное по выборочным данным) меньше или равно критического значения F-критерия (определённого по таблице распределения Фишера-Снедекора), т.е. Fнабл≤Fкрит, то основная гипотеза принимается.
Гипотеза о равенстве генеральных средних проверяется с помощью t-критерия Стьюдента.
Наблюдаемое значение t-критерия (вычисленное на основе выборочных данных) сравнивают с критическим значением t-критерия, которое определяется по таблице распределения Стьюдента.
Критическое значение t-критерия tкрит(а,N–2) определяется по таблице распределения Стьюдента, где а – уровень значимости, (N–2) – число степеней свободы.
Наблюдаемое значение t-критерия при проверке основной гипотезы вида H0:μi=μj определяется по формуле:
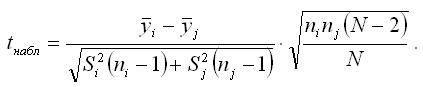
При проверке гипотез возможны следующие ситуации.
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) больше критического значения t-критерия (определённого по таблице распределения Стьюдента), т. е. tнабл>tкрит, то основная гипотеза отвергается, и генеральные средние двух выборок не равны между собой. Следовательно, в исходном временном ряду присутствует трендовая компонента.
Если наблюдаемое значение t-критерия (вычисленное по выборочным данным) меньше или равно критического значения t-критерия (определённого по таблице распределения Стьюдента), т.е. tнабл≤tкрит, то основная гипотеза принимается, и генеральные средние двух выборок равны между собой. Следовательно, в исходном временном ряду отсутствует трендовая компонента.
65.Выделение сезонной компоненты (аддитивная и мультипликативная модели).
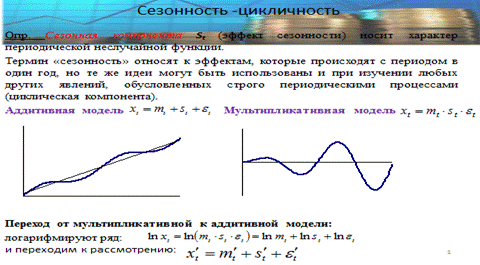
66.Применение спектрального анализа для определения наличия структурных компонент временного ряда
Одним из общепринятых способов анализа структуры стационарных временных рядов является использование дискретного преобразования Фурье для оценки спектральной плотности или спектра ряда. Этот метод может применяться:
· для получения описательных статистик одного временного ряда или описательных статистик зависимостей между двумя временными рядами;
· для выявления периодических и квазипериодических свойств временных рядов;
· для проверки адекватности моделей, построенных другими методами;
· для сжатого представления данных;
· для интерполяции динамики временных рядов.

67.Оценка сезонной компоненты с помощью тригонометрических функций.



68.Оценка сезонной компоненты методом сезонных индексов.


69.Оценка сезонной компоненты методом фиктивных переменных

70.Стационарность случайных стохастических процессов в широком и узком смысле