 2015-05-14
2015-05-14 2050
2050Чтобы дать более полное представление о многопроцессорных вычислительных системах, помимо высокой производительности необходимо назвать и другие отличительные особенности. Прежде всего это необычные архитектурные решения, направленные на повышение производительности (работа с векторными операциями, организация быстрого обмена сообщениями между процессорами или организация глобальной памяти в многопроцессорных системах и др.).
Приведем вначале систематику Флинна. В соответствии с ней все компьютеры делятся на четыре класса в зависимости от числа потоков команд и данных.
1. SISD (Single Instruction Single Data) – одиночный поток команд, одиночный поток данных (последовательные компьютеры фон Неймана). К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. Примерами компьютеров с архитектурой SISD являются большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems. Это обычные скалерные, однопроцессорные системы.
Помимо RISC и CISC компьютеров, архитектура SISD породила еще и машины с суперскалярной обработкой. Смысл которой – наличие в аппаратуре средств, позволяющих одновременно выполнять две и более скалярные операции, т.е. команд обработки пары чисел (например, процессоры DEC серии Alpha).
2. SIMD ((Single Instruction Multiple Data) – характеризуются наличием одиночного потока команд, но множественного потока данных. К этому классу относятся однопроцессорные, векторно-конвейерные суперкомпьютеры, например Cray – 1и более современный Cray Y-MP. В этом случае мы имеем дело с одним потоком (векторных) команд, а потоков данных много; каждый элемент вектора входит в отдельный поток данных.
Эти системы обычно имеют большое количество процессоров, в пределах от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. Когда данные обрабатываются посредством векторных модулей, результаты могут быть выданы на один, два или три такта частотогенератора (такт частотогенератора является основным временным параметром системы). При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа является, например, компьютеры Hitachi S3600.
Вспомним:
Основу конвейерной обработки составляет – одновременное выполнение нескольких различных этапов одной операции на различных ступенях конвейера.
При выполнении векторной обработки – одна и та же операция применяется ко всем элементам вектора.
Пример: проект SOLOMON.
К этому же классу ВС относятся матричные процессоры, например знаменитый ILIAC – IV. Они также имеют векторные команды и реализуют векторную обработку, но не посредством конвейеров, как в векторных суперкомпьютерах, а с помощью матриц процессоров.
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
В отличие от ограниченного конвейерного функционирования векторного процессора, матричный процессор (синоним для большинства SIMD-машин) может быть значительно более гибким. Обрабатывающие элементы таких процессоров - это универсальные программируемые ЭВМ, так что задача, решаемая параллельно, может быть достаточно сложной и содержать ветвления. Обычное проявление этой вычислительной модели в исходной программе примерно такое же, как и в случае векторных операций: циклы на элементах массива, в которых значения, вырабатываемые на одной итерации цикла, не используются на другой итерации цикла.
Модели вычислений на векторных и матричных ЭВМ настолько схожи, что эти ЭВМ часто обсуждаются как эквивалентные.
3. MIMD (Multiple Instruction Multiple Data) – множественный поток команд и множественный поток данных.
К этому классу принадлежат не векторные суперЭВМ, но и все многопроцессорные ВС. Эта архитектура включает все уровни параллелизма, от конвейера операций до независимых операций и команд. Употребляя термин MIMD надо иметь ввиду не только много процессоров, но и множество вычислительных процессов, одновременно выполняемых в ВС.
Машины типа MIMD. Термин "мультипроцессор" покрывает большинство машин типа MIMD и (подобно тому, как термин "матричный процессор" применяется к машинам типа SIMD) часто используется в качестве синонима для машин типа MIMD. В мультипроцессорной системе каждый процессорный элемент (ПЭ) выполняет свою программу достаточно независимо от других процессорных элементов. Процессорные элементы, конечно, должны как-то связываться друг с другом, что делает необходимым более подробную классификацию машин типа MIMD. В мультипроцессорах с общей памятью (сильносвязанных мультипроцессорах) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена. В противоположность этому варианту в слабосвязанных многопроцессорных системах (машинах с локальной памятью) вся память делится между процессорными элементами и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом. Системы со слабой связью, это многомашинные комплексы, в которых отдельные компьютеры объединяются с помощью либо сетевых средств, либо с помощью общей внещней памяти.
Базовой моделью вычислений на MIMD-мультипроцессоре является совокупность независимых процессов, эпизодически обращающихся к разделяемым данным. Существует большое количество вариантов этой модели. На одном конце спектра - модель распределенных вычислений, в которой программа делится на довольно большое число параллельных задач, состоящих из множества подпрограмм. На другом конце спектра - модель потоковых вычислений, в которых каждая операция в программе может рассматриваться как отдельный процесс. Такая операция ждет своих входных данных (операндов), которые должны быть переданы ей другими процессами. По их получении операция выполняется, и полученное значение передается тем процессам, которые в нем нуждаются. В потоковых моделях вычислений с большим и средним уровнем гранулярности, процессы содержат большое число операций и выполняются в потоковой манере.
4. MISD (Multiple Instruction Single Data) – этот класс долгое время пустовал, более того, в литературе вы встретите утверждение, что этот класс не представляет практического интереса. Это объясняется тем, что не существовало примеров практической реализации систем, в которых одни и те же данные обрабатывались бы большим числом процессоров. Теперь ситуация изменилась, для MISD найдена адекватная организация ВС – распределенная мультипроцессорная система с общими данными. Наиболее простой пример такой ВС – обычная локальная сеть ПК, работающая с единой базой данных, когда много процессоров обрабатывают один поток данных.
Однако надо иметь ввиду, что как только все пользователи переключаются на обработку собственных данных, недоступных для других абонентов сетиMISD система превращается в систему с множеством потоков команд и множеством потоком данных, т.е. MIMD архитектуру.
Системы с масссовым параллелизмом
Многие современные супер-ЭВМ представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
О MSIMD системах говорят иногда, как о сильносвязанных комплексах класса MIMD, представляющих собой симметричные многопроцессорные серверы с общим полем ОП. Например, DEC Alpha Server 8200/8400 или SGI Power Chellenge.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать "крупнозернистый" параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы. Машины типа MSIMD, как можно себе представить, дают возможность использовать лучший из этих двух принципов декомпозиции: векторные операции ("мелкозернистый" параллелизм) для тех частей программы, которые подходят для этого, и гибкие возможности MIMD-архитектуры для других частей программы.
Многопроцессорные системы за годы развития вычислительной техники претерпели ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Однако в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами:
1. Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
Архитектура MIMD может использовать все преимущества современной микропроцессорной технологии на основе строгого учета соотношения стоимость/производительность. В действительности практически все современные многопроцессорные системы строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от многопроцессорных SISD-машин, упомянутых выше, команды и данные связаны, потому что они представляют различные части одной и той же выполняемой задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач, с целью сокращения времени выполнения основной задачи. Наличие большого разнообразия попадающих в данный класс систем, делает классификацию Флинна не полностью адекватной. Действительно и четырех-процессорный SX-5 компании NEC и тысяче-процессорный Cray T3E оба попадают в этот класс. Это заставляет искать другой подход к классификации, иначе описывающий классы компьютерных систем.
Одной из отличительных особенностей многопроцессорной вычислительной системы является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для многопроцессорной системы, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам. Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, другая - на использовании общей памяти. В многопроцессорной системе с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика".
Таким образом, существующие MIMD-машины распадаются на два основных класса в зависимости от количества объединяемых процессоров, которое определяет и способ организации памяти и методику их межсоединений.
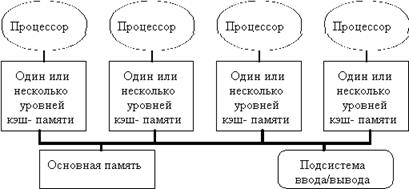 |
К первой группе относятся машины с общей (разделяемой) основной памятью, объединяющие до нескольких десятков (обычно менее 32) процессоров. Сравнительно небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью одной шины. Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным. Структура подобной системы представлена на рис. 2.14.
Рис. 2.14 Мультипроцессорная система с общей памятью.
Вторую группу машин составляют крупномасштабные системы с распределенной памятью. Для того чтобы поддерживать большое количество процессоров приходится распределять основную память между ними, в противном случае полосы пропускания памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой. На рис. 2.15 показана структура такой системы.
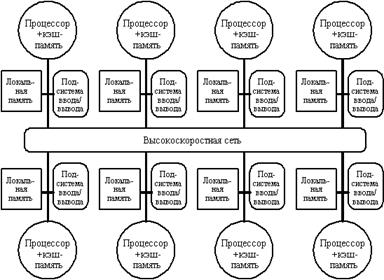 |
Рис. 2.15 Мультипроцессорная система с распределенной памятью
С ростом числа процессоров просто невозможно обойти необходимость реализации модели распределенной памяти с высокоскоростной сетью для связи процессоров. С быстрым ростом производительности процессоров и связанным с этим ужесточением требования увеличения полосы пропускания памяти, масштаб систем (т.е. число процессоров в системе, для которых требуется организация распределенной памяти), уменьшается, также как и уменьшается число процессоров, которые удается поддерживать на одной разделяемой шине и общей памяти.
Распределение памяти между отдельными узлами системы имеет два главных преимущества. Во-первых, это эффективный с точки зрения стоимости способ увеличения полосы пропускания памяти, поскольку большинство обращений могут выполняться параллельно к локальной памяти в каждом узле. Во-вторых, это уменьшает задержку обращения (время доступа) к локальной памяти. Наиболее известными системами с общей памятью (SMP-системами) являются SMP-cервера и рабочие станции на базе процессоров Intel (IBM, HP, Compaq, Dell, ALR, Unisys, DG, Fujitsu и др.) Вся система работает под управлением единой ОС (обычно UNIX-подобной, но для Intel-платформ поддерживается Windows NT). ОС автоматически (в процессе работы) распределяет процессы по процессорам, но иногда возможна и явная привязка.
Системами с раздельной памятью являются суперкомпьютеры МВС-1000, IBM RS/6000 SP, SGI/CRAY T3E, системы ASCI, Hitachi SR8000, системы Parsytec. Машины последней серии CRAY T3E от SGI, основанные на базе процессоров Dec Alpha 21164 с пиковой производительностью 1200 Мфлопс/с (CRAY T3E-1200), способны масштабироваться до 2048 процессоров.
2.7 Концепция кластерных систем
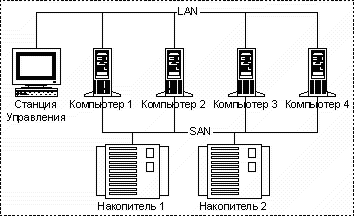
Рисунок 2.16 Кластерная система
· LAN – Local Area Network, локальная сеть
· SAN – Storage Area Network, сеть хранения данных
Впервые в классификации вычислительных систем термин "кластер" определила компания Digital Equipment Corporation (DEC).








