 2015-05-18
2015-05-18 1290
1290В прогнозных расчетах по уравнению регрессии определяется предсказываемое 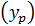 значение как точечный прогноз
значение как точечный прогноз 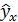 при
при 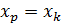 ,т. е. путем подстановки в уравнение регрессии
,т. е. путем подстановки в уравнение регрессии 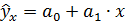 соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки
соответствующего значения х. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки 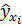 ,т. е
,т. е 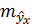 , и соответственно интервальной оценкой прогнозного значения (у*)
, и соответственно интервальной оценкой прогнозного значения (у*)
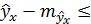 у*
у* 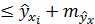 .
.
Чтобы понять, как строится формула для определения величин стандартной ошибки ,обратимся к уравнению линейной регрессии: . Подставим в это уравнение выражение параметра а:
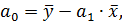
тогда уравнение регрессии примет вид:
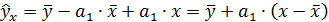 .
.
Отсюда вытекает, что стандартная ошибка зависит от ошибки 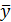 и ошибки коэффициента регрессии b, т. е.
и ошибки коэффициента регрессии b, т. е.
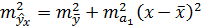 .(4.16)
.(4.16)
Из теории выборки известно, что 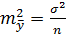 . Используя в качестве оценки
. Используя в качестве оценки 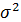 остаточную дисперсию на одну степень свободы
остаточную дисперсию на одну степень свободы 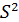 ,получим формулу расчета ошибки среднего значения переменной y.
,получим формулу расчета ошибки среднего значения переменной y.
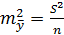 .(4.17)
.(4.17)
Ошибка коэффициента регрессии, как уже было показано, определяется формулой
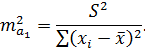
Считая, что прогнозное значение фактора 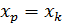 ,получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е.
,получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, т. е. 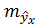 :
:
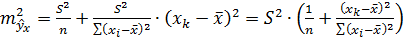 . (4.18)
. (4.18)
Соответственно 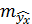 имеет выражение:
имеет выражение:
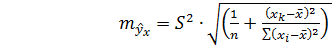 . (4.19)
. (4.19)
Рассмотренная формула стандартной ошибки предсказываемого среднего значения y при заданном значении 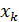 характеризует ошибку положения линии регрессии. Величина стандартной ошибки , как видно из формулы, достигает минимума при
характеризует ошибку положения линии регрессии. Величина стандартной ошибки , как видно из формулы, достигает минимума при 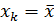 , и возрастает по мере того, как «удаляется» от
, и возрастает по мере того, как «удаляется» от 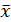 в любом направлении. Иными словами, чем больше разность между и x, тем больше ошибка с которой предсказывается среднее значение y для заданного значения .Можно ожидать наилучшие результаты прогноза, если признак-фактор х находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении от . Если же значение оказывается за пределами наблюдаемых значений х, используемых при построении линейной регрессии, то результаты прогноза ухудшаются в зависимости от того, насколько отклоняется от области наблюдаемых значений фактора x.
в любом направлении. Иными словами, чем больше разность между и x, тем больше ошибка с которой предсказывается среднее значение y для заданного значения .Можно ожидать наилучшие результаты прогноза, если признак-фактор х находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении от . Если же значение оказывается за пределами наблюдаемых значений х, используемых при построении линейной регрессии, то результаты прогноза ухудшаются в зависимости от того, насколько отклоняется от области наблюдаемых значений фактора x.
Для нашего примера составит:
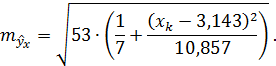
При
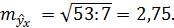
При 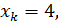
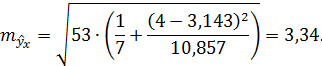
Соответственно составит эту же величину и при 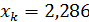 . Для прогнозируемого значения 95%-ные доверительные интервалы при заданном определяются выражением
. Для прогнозируемого значения 95%-ные доверительные интервалы при заданном определяются выражением
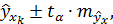
т.е. 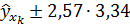 , или
, или 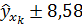 .
.
При , прогнозное значение y составит:
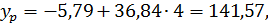
которое представляет собой точечный прогноз.
Прогноз линии регрессии в интервале составит:
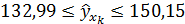
Однако фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки 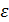 , дисперсия которой оценивается как остаточная дисперсия на одну степень свободы
, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы 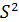 . Поэтому предсказываемого индивидуального значения y должна включать не только стандартную ошибку
. Поэтому предсказываемого индивидуального значения y должна включать не только стандартную ошибку 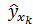 , но и случайную ошибку S.
, но и случайную ошибку S.
Средняя ошибка прогнозируемого индивидуального значения y 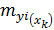 составит:
составит:
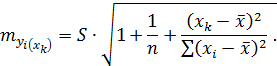
По данным рассматриваемого примера получим:
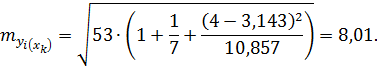
Доверительные интервалы прогноза индивидуальных значений y при 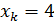 с вероятностью 0,95 составят:
с вероятностью 0,95 составят: 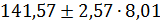 , или 141,57
, или 141,57 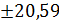 , это означает, что
, это означает, что 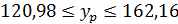 .
.
Интервал достаточно широк, прежде всего, за счет малого объема наблюдений.
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
Рассмотренная формула средней ошибки индивидуального значения признака y 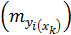 может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
Предположим, что в нашем примере с функцией издержек выдвигается предположение, что в предстоящем году в связи со стабилизацией экономики при выпуске продукции в 8 тыс. ед. затраты на производство не превысят 250 млн руб. Означает ли это действительно изменение найденной закономерности или же данная величина затрат соответствует регрессионной модели?
Чтобы ответить на этот вопрос, найдем точечный прогноз при х = 8, т. е.
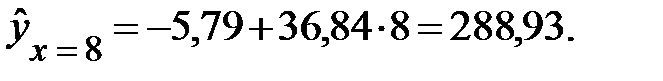
Предполагаемое же значение затрат, исходя из экономической ситуации, - 250,0. Для оценки существенности различия этих величин определим среднюю ошибку прогнозируемого индивидуального значения:
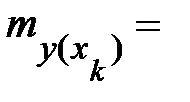
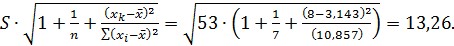
Сравним ее с величиной предполагаемого снижения издержек производства, т. е. 38,93:
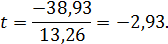
Поскольку оценивается значимость только уменьшения затрат, то используется односторонний 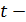 критерий Стьюдента. При ошибке в 5 % с пятью степенями свободы
критерий Стьюдента. При ошибке в 5 % с пятью степенями свободы 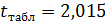 . Следовательно, предполагаемое уменьшение затрат значимо отличается от прогнозируемого по модели при 95 %-ном уровне доверия. Однако если увеличить вероятность до 99 %, при ошибке в 1 % фактическое значение критерия оказывается ниже табличного 3,365, и рассматриваемое различие в величине затрат статистически не значимо.
. Следовательно, предполагаемое уменьшение затрат значимо отличается от прогнозируемого по модели при 95 %-ном уровне доверия. Однако если увеличить вероятность до 99 %, при ошибке в 1 % фактическое значение критерия оказывается ниже табличного 3,365, и рассматриваемое различие в величине затрат статистически не значимо.

