2015-05-18
2015-05-18 729
729Метод наименьших квадратов относится к важному разделу организационно-экономического моделирования и прикладной статистики - многомерному статистическому анализу. В многомерном статистическом анализе исходные данные - это как минимум пара чисел (ti, Xi) (а не одно число).
Предполагается, что переменная X линейно зависит от переменной t, т.е.
X (t) = a (t – t ср.) + b -
Это - теоретическая модель, а практически известны исходные данные – набор пар чисел (ti, Xi), i = 1, 2, 3, …, n, где:
ti – независимая переменная (например, время, а в случае определения выборочной функции спроса - цена pi),
Xi – зависимая переменная (например, индекс инфляции, курс доллара, а в случае определения выборочной функции спроса это будет спрос D (pi)).
Предполагается, что переменные связаны линейной зависимостью:
Xi = a (ti – t ср.) + b + ei , i = 1, 2, 3, …, n.
Это - реальная зависимость, учитывающая погрешности (ei), искажающие зависимость, параметры a и b нам неизвестны и подлежат оцениванию, а
t ср.= 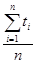 .
.
Обычно параметры a и b оценивают методом наименьших квадратов.
Согласно этому методу для расчета наилучшей функции, приближающей линейным образом зависимость X от t, следует рассмотреть функцию двух переменных:
f (a,b) = 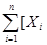 - a (ti – t ср) – b ]2.
- a (ti – t ср) – b ]2.
Фактически – это есть сумма квадратов разностей между реальными значениями функции и теоретически определенными значениями функции от независимой переменной.
Оценки метода наименьших квадратов – это такие значения a и b, при которых функция f (a,b) достигает минимума по всем значениям аргументов. Чтобы найти эти оценки, надо вычислить частные производные от функции f (a,b) по аргументам a и b, т.е. 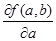 и
и 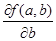 , и приравнять их к 0.
, и приравнять их к 0.
Из полученных уравнений путем внутриматематических преобразований получим оценки:
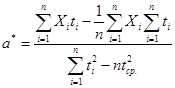
 ,
,
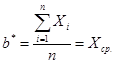
Следовательно, восстановленная функция, с помощью которой можно прогнозировать, имеет вид:
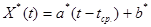 .
.
Это - теоретическая функция, в которой вместо параметров подставлены их оценки, что позволяет проводить прогнозирование на какой-то интервал независимой переменной t вперед, а также интерполировать эти данные на моменты между наблюдениями.
Если взять другие обозначения, то линейная зависимость может выглядеть так:
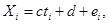 i = 1, 2, 3, …., n. (1)
i = 1, 2, 3, …., n. (1)
Сравнивая выражения:
Xi = a (ti – t ср.) + b +ei = ati – at ср. + b +ei
и (1), легко перейти от одного к другому:
c =a, d = b – at ср.
Аналогичные соотношения справедливы и для оценок:
c* = a*, d* = b* -a*t ср,
Xi* = c*ti + d*.
Оценкой погрешности (невязки) ei является кажущаяся невязка
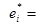 Xi - Xi*.
Xi - Xi*.
Возникает вопрос, насколько точно оценивается зависимость. Чтобы ответить на него, надо ввести модель порождения данных:
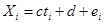 ,
,
где e 1, e 2…… en - независимые, одинаково распределенные случайные величины с математическим ожиданием 0 и дисперсией 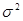 .
.
Таким образом, модель описывается тремя параметрами: c, d и . Параметры c и d мы умеем оценивать, а для оценки 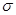 2 используется следующая формула:
2 используется следующая формула:
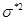 =
= 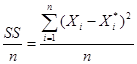 ,
,
где SS - так называемая остаточная сумма квадратов, - оценка дисперсии.
Доверительные интервалы для прогностической функции записываются следующим образом (см. п.3.1 главы 3 настоящего учебника):
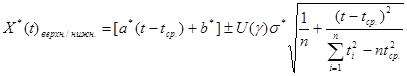 ,
,
где 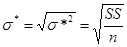 ,
,
U (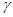 ) –квантиль стандартного нормального распределения порядка
) –квантиль стандартного нормального распределения порядка 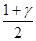 .
.
При доверительной вероятности = 0,95 находим из таблиц U () = 1,96, при = 0,99 имеем U () = 2,58, и U () = 1,64 при = 0,9.