2015-06-14
2015-06-14 905
905Этап 1. Исключение постоянной систематической погрешности − наиболее сложная задача, требующая глубокого анализа процесса измерений. К подготовительным мероприятиям этого анализа относятся:
предварительная поверка или калибровка измерительного прибора;
вычисление или экспериментальное определение погрешности для введения поправки;
создание и поддержание с необходимой стабильностью условий измерений.
При выполнении измерений для исключения постоянной систематической погрешности используются следующие приемы:
замещение измеряемой величины (параметра) равновеликой ей величиной с известным значением или регулируемой образцовой мерой;
измерения несколькими независимыми способами с последующим вычислением среднего значения;
компенсация погрешности по знаку (способ двойных измерений);
измерение несколькими измерительными приборами с последующим вычислением среднего из показаний всех приборов, при этом систематические погрешности всех приборов можно рассматривать как случайные величины.
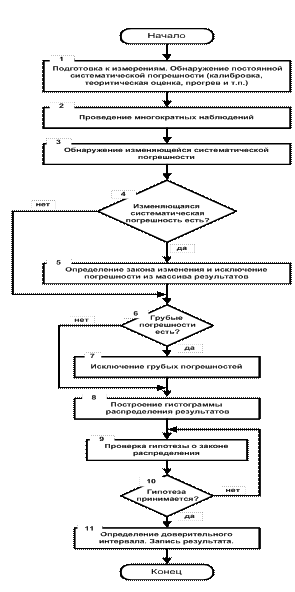
Рисунок 5.4 − Схема алгоритма обработки результатов наблюдений
Этап 2. Провести многократные наблюдения в соответствии с п.2.6 раздела 2.
Этап 3. Изменяющиеся систематические погрешности исключаются введением поправок, для чего необходимо обнаружить систематические погрешности.
Существуют несколько способов обнаружения изменяющейся систематической погрешности. Наиболее простой способ – графический.
Пример построения графика d Q ниi = Q ниi − 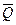 = f(n) показан на рис.5.5.
= f(n) показан на рис.5.5.
Из рис.5.5. видно, что, несмотря на случайные изменения, последовательность неисправленных отклонений результатов наблюдений от среднего значения d Q ниi = Q ниi − обнаруживает тенденцию к убыванию (или к возрастанию в иных случаях).
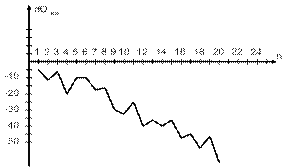
Рисунок 5.5 – График зависимости d Q = f(n)
Этап 4. Для того, чтобы исправить результаты наблюдений введением в них поправок, необходимо выяснить характер зависимости погрешности. Для выяснения характера зависимости погрешности используют метод наименьших квадратов, регрессионный или корреляционный анализ.
Чаще всего эту зависимость удается аппроксимировать линейной зависимостью вида (метод наименьших квадратов)
| Q (t) = a + b t,, | (5.10) |
где a и b − параметры прямой; t − время наблюдения (или иной неслучайный параметр, характеризующий условия проведения измерений).
Значения a и b определяется из выражений
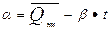 ;
; 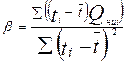 (5.11)
(5.11)
где 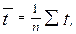 ;
; 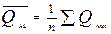 (5.12)
(5.12)
Исправленные результаты наблюдений находятся по выражению
Qi = Qниi − b ti.
Для удобства вычислений по формуле 5.12 результаты необходимо свести в табл.5.2.
Таблица 5.2 − Результаты многократных наблюдений
| Номер наблюдения | ti, мин | Qниі | btі | Qі |
| 0,00 | ||||
| 0,50 | ||||
| 1,00 | ||||
| 1,50 | ||||
| и т.д. |
Этап 5. По исправленным значениям Q i, сведенным в табл.5.2, рассчитывается исправленное значение среднего арифметического по выражению (5.5).
Этап 6. Проверка наличия грубых погрешностей. Следует иметь в виду, что решение такой задачи в любом случае с определенной малой вероятностью может оказаться ошибочным. Поэтому при принятии решения об исключении или сохранении резко отклоняющихся результатов наблюдений (если таковые есть), нужно внимательно проанализировать условия, в которых получился результат.
Чтобы оценить принадлежность наблюдения Qi к данной совокупности и принять решение об исключении или оставлении Qi в составе массива, находят отношение
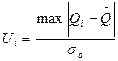 , , |
после чего сравнивают его с табличным значением (табл.5.4) h для n = 30 и q=5%.
Таблица 5.4
| Объем выборки n | q % = | 1−P % | Объем выборки n | q % = | 1−P % |
| 1,83 | 1,94 | 2,36 | 2,53 | ||
| 2,03 | 2,18 | 2,64 | 2,87 | ||
| 2,25 | 2,41 | 2,70 | 2,93 |
Этап 7. Если полученные значения U i превосходят значения h, то соответствующее значение 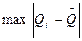 исключается из массива результатов.
исключается из массива результатов.
Этап 8. Данный этап является начальным этапом для обработки случайных погрешностей. Выдвижение гипотезы о виде распределения случайных погрешностей осуществляется на основе построения гистограммы. Для ее построения (см. рис.5.1) результаты наблюдений группируют по интервалам и подсчитывают число наблюдений, попавших в каждый из них. Число интервалов L выбирают по формуле
L = 1,0 + 3,2 lg n, где n − число наблюдений.
После вычисления L округляют до ближайшего наибольшего целого.
Длину интервала группирования d Q вычисляют по формуле
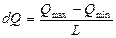 , , |
округляют до четного числа в сторону увеличения и затем определяют границы интервалов. Для этого строят числовую ось, на которой отмечают Q исправленных результатов, в обе стороны от него откладывают сначала по половине d Q, а затем по целому интервалу, пока крайние интервалы не перекроют Q max и Q min, как показано на рис.5.6.
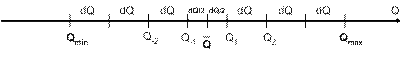
Рисунок 5.6 – К построению гистограммы
Затем подсчитывают число наблюдений, попадающих в каждый интервал mі и на каждом интервале, как на основании, строят прямоугольник с высотой, равной mі либо Wі, где
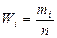 . . |
Масштаб графика рекомендуется выбирать так, чтобы высота гистограммы относилась к ее основанию как 3:5.
Этап 9. На основании вида построенной гистограммы выдвигается гипотеза о законе распределения случайной погрешности (табл. 5.1).
При этом необходимо отметить, что, поскольку наиболее общим распределением, к которому, при n®¥, стремятся все остальные распределения, является нормальное распределение, то в данной работе, независимо от вида построенной гистограммы, выдвигается и проверяется гипотеза о принадлежности результатов наблюдений нормальному распределению.
Правила проверки гипотезы о принадлежности результатов наблюдений нормальному распределению подробно изложены в ГОСТ 8.207−76. При этом выбор всех необходимых табличных значений для выполнения составного критерия осуществляется при доверительной вероятности Р = 95 %, что вполне приемлемо для инженерных расчетов, и на уровне значимости критерия q (вероятность совершения ошибки)
q = 1 − Р = 5 %, (0.05).
При числе наблюдений n > 50 гипотезу проверяют по одному из критериев: χ2 Пирсона или ω2 Мизеса − Смирнова.
При числе наблюдений 50 > n > 15 гипотезу проверяют по составному критерию, приведенному в приложении 1 ГОСТ 8.207−76.
При числе наблюдений n < 15 гипотезу о принадлежности результатов наблюдений нормальному распределению не проверяют.
Этап 10. Для массива результатов, не содержащего изменяющейся систематической и грубой погрешностей, по формулам (5.5...5.9) производится оценка , S Q, 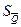 .
.
Этап 11. При нормальном законе распределения истинное значение измеряемой величины Qи с доверительной вероятностью Р находится внутри интервала e с границами
e = ( − t q, n * ; + t q, n * ),
где t q, n − q−процентная точка распределения Стьюдента, которая зависит от числа наблюдений n, уровня значимости q = 1−Р и выбирается по таблице приложения 2 из ГОСТ 8.207−76. Запись результатов производится в форме
| Qист = ± e (Р). | (5.13) |
Примечание.
В том случае, когда распределение результатов наблюдений не соответствует нормальному закону, значение t q, n выбирается из таблицы 2 приложения 2 ГОСТ 8.207−76 для наиболее подходящего вида распределения.
(1, с.15−31; 2, с.14,15,17−26)
ЛИТЕРАТУРА
1. Кукуш В.Д. Электрорадиоизмерения. − М.: Радио и связь, 1985.−368 с.
2. Елизаров А. С. Электрорадиоизмерения. − Минск: Высшая школа, 1986.− 320 с.
3 Метрология и электрорадиоизмерения в телекоммуникационных системах: Учебник для вузов/Под ред. В.И. Нефедова. – М.: Высш. шк., 2001. – 383 с.