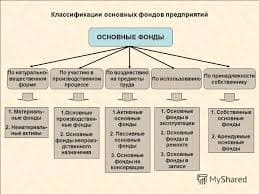
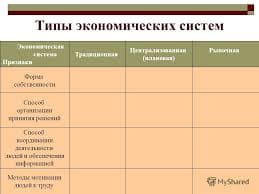
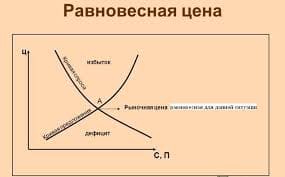
2015-08-13
2015-08-13 5104
5104Все языки манипулирования данными (ЯМД), созданные до появления
реляционных баз данных и разработанные для многих систем управления базами данных (СУБД) персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их.
Рассматриваемый же ниже непроцедурный язык SQL (Structured Query Language - структурированный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных.
Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволило создать компактный язык с небольшим (менее 30) набором предложений. SQL может использоваться как интерактивный (для выполнения запросов) и как встроенный (для построения прикладных программ). В нем существуют:
– предложения определения данных (определение баз данных, а также определение и уничтожение таблиц и индексов);
– запросы на выбор данных (предложение SELECT);
– предложения модификации данных (добавление, удаление и изменение данных);
– предложения управления данными (предоставление и отмена привилегий на доступ к данным, управление транзакциями и другие). Кроме того, он предоставляет возможность выполнять в этих предложениях:
– арифметические вычисления (включая разнообразные функциональные преобразования), обработку текстовых строк и выполнение операций сравнения значений арифметических выражений и текстов;
– упорядочение строк и (или) столбцов при выводе содержимого таблиц на печать или экран дисплея;
– создание представлений (виртуальных таблиц), позволяющих пользователям иметь свой взгляд на данные без увеличения их объема в базе данных;
– запоминание выводимого по запросу содержимого таблицы, нескольких таблиц или представления в другой таблице (реляционная операция присваивания).
– агрегирование данных: группирование данных и применение к этим группам таких операций, как среднее, сумма, максимум, минимум, число элементов и т.п.
В SQL используются следующие основные типы данных, форматы которых могут несколько различаться для разных СУБД:
INTEGER - целое число (обычно до 10 значащих цифр и знак);
SMALLINT - "короткое целое" (обычно до 5 значащих цифр и знак);
DECIMAL(p,q) - десятичное число, имеющее p цифр (0 < p < 16) и знак; с помощью q задается число цифр справа от десятичной точки (q < p, если q = 0, оно может быть опущено);
FLOAT - вещественное число с 15 значащими цифрами и целочисленным порядком, определяемым типом СУБД;
CHAR(n) - символьная строка фиксированной длины из n символов (0 < n <256);
VARCHAR(n) - символьная строка переменной длины, не превышающей n символов (n > 0 и разное в разных СУБД, но не меньше 4096);
DATE - дата в формате, определяемом специальной командой (по умолчанию mm/dd/yy); поля даты могут содержать только реальные даты, начинающиеся за несколько тысячелетий до н.э. и ограниченные пятым-десятым тысячелетием н.э.;
TIME - время в формате, определяемом специальной командой, (по умолчанию hh.mm.ss);
DATETIME - комбинация даты и времени;
MONEY - деньги в формате, определяющем символ денежной единицы ($, руб,...) и его расположение (суффикс или префикс), точность дробной части и условие для показа денежного значения.
В некоторых СУБД еще существует тип данных LOGICAL, DOUBLE и ряд других. Тем не менее, в целях обеспечения переносимости баз данных между различными в том числе и вычислительными платформами, целесообразно использовать ограниченный набор так называемых «канонических» типов данных. В данном лабораторном курсе мы будем ограничивать этот набор типами INTEGER, VARCHAR, DATE и FLOAT.
Ориентированный на работу с таблицами SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому в разных СУБД он либо используется вместе с языками программирования высокого уровня (например, такими как Си или Паскаль), либо включен в состав команд специально разработанного языка СУБД (язык систем dBASE, R:BASE и т.п.).
Унификация полных языков современных профессиональных СУБД достигается за счет внедрения объектно-ориентированного языка четвертого поколения 4GL. Последний позволяет организовывать циклы, условные предложения, меню, экранные формы, сложные запросы к базам данных с интерфейсом, ориентированным как на алфавитно-цифровые терминалы, так и на оконный графический интерфейс (X-Windows, MS Windows).
Все запросы на получение практически любого количества данных из одной или нескольких таблиц выполняются с помощью единственного предложения SELECT. В общем случае результатом реализации предложения SELECT является другая таблица. К этой новой (рабочей) таблице может быть снова применена операция SELECT и т.д., то есть такие операции могут быть вложены друг в друга. Представляет исторический интерес тот факт, что именно возможность включения одного предложения SELECT внутрь другого послужила мотивировкой использования прилагательного "структурированный" в названии языка SQL.
Предложение SELECT может использоваться как:
– самостоятельная команда на получение и вывод строк таблицы, сформированной из столбцов и строк одной или нескольких таблиц (представлений);
– элемент WHERE- или HAVING-условия (сокращенный вариант предложения, называемый "вложенный запрос");
– фраза выбора в командах CREAT VIEW, DECLARE CURSOR или INSERT;
– средство присвоения глобальным переменным значений из строк сформированной таблицы (INTO-фраза).
Нами будут рассмотрены только две первые функции предложения SELECT, а здесь – его синтаксис, ограниченный конструкциями, используемыми при реализации этих функций. Здесь в синтаксических конструкциях используются следующие обозначения:
– звездочка (*) для обозначения "все" - употребляется в обычном для программирования смысле, то есть "все случаи, удовлетворяющие определению";
– квадратные скобки ([]) – означают, что конструкции, заключенные в эти скобки, являются необязательными (т.е. могут быть опущены);
– фигурные скобки ({}) – означают, что конструкции, заключенные в эти скобки, должны рассматриваться как целые синтаксические единицы, т.е. они позволяют уточнить порядок разбора синтаксических конструкций, заменяя обычные скобки, используемые в синтаксисе SQL;
– многоточие (...) – указывает на то, что непосредственно предшествующая ему синтаксическая единица факультативно может повторяться один или более раз;
– прямая черта (|) – означает наличие выбора из двух или более возможностей. Например обозначение ASC|DESC указывает, можно выбрать один из терминов ASC или DESC; когда же один из элементов выбора заключен в квадратные скобки, то это означает, что он выбирается по умолчанию (так, [ASC]|DESC означает, что отсутствие всей этой конструкции будет восприниматься как выбор ASC);
– точка с запятой (;) – завершающий элемент предложений SQL;
– запятая (,) – используется для разделения элементов списков;
– пробелы () – могут вводиться для повышения наглядности между любыми синтаксическими конструкциями предложений SQL;
– прописные жирные латинские буквы и символы – используются для написания конструкций языка SQL и должны (если это специально не оговорено) записываться в точности так, как показано;
– строчные буквы – используются для написания конструкций, которые должны заменяться конкретными значениями, выбранными пользователем, причем для определенности отдельные слова этих конструкций связываются между собой символом подчеркивания (_);
– термины таблица, столбец,... – заменяют (с целью сокращения текста синтаксических конструкций) термины имя_таблицы, имя_столбца,..., соответственно;
– термин таблица – используется для обобщения таких видов таблиц, как базовая_таблица, представление или псевдоним; здесь псевдоним служит для временного (на момент выполнения запроса) переименования и (или) создания рабочей копии базовой_таблицы (представления).
Предложение SELECT имеет следующий формат:
SELECT [DISTINCT | ALL]{*
| [<выражение для столбца> [[AS] <псевдоним>]] [,…]}
FROM <имя таблицы> [[AS] <псевдоним>] [,…]
[WHERE <предикат>]
[[GROUP BY <список столбцов>]
[HAVING <условие на агрегатные значения>] ]
[ORDER BY <список столбцов>]
Рассмотрим вышеприведенный формат подробнее.
SELECT – ключевое слово, обозначающее начало запроса языка SQL.
Следом за ключевым словом SELECT должен быть приведен список столбцов таблицы или таблиц участвующих в запросе, которые должны присутствовать в результирующей таблице.
DISTINCT – ключевое слово, позволяющее исключить попадание в выборку результатов-дубликатов.
* - ключевой элемент показывающий что в выборку попадут все столбцы таблицы или таблиц.
AS – ключевое слово, позволяющее определить псевдоним для имени столбца.
Это весьма полезно, например, в тех случаях когда в запросе участвуют таблицы с одинаковыми именами столбцов.
FROM – ключевое слово которое позволяет определить список таблиц, участвующих в запросе. Здесь также можно использовать псевдонимы с помощью ключевого слова AS.
WHERE – позволяет наложить условие по которому будет произведена выборка необходимых данных. Условие представляет собой предикат имеющий значение true. В данное выражение может входить любое число различных условий для этого необходимо использовать ключевые слова AND, OR, NOT и другие.
GROUP BY – ключевое слово после которого следует выражение на основе которого будет производиться группировка результатов выполнения запроса. Используется вместе с агрегатными функциями.
HAVING – позволяет наложить условия на результат выполнения агрегатных функций.
ORDER BY – осуществляет упорядочивание результатов выборки на основе последующего списка столбцов.
Приведем ряд простых запросов к учебной базе данных.
Получить все записи таблицы students:
SELECT * FROM students
Получить все записи таблицы groups:
SELECT * FROM groups
Получить список всех фамилий студентов:
SELECT lastname FROM students
Получить список всех студентов отсортированный по фамилии:
SELECT lastname, firstname, secondname FROM students
ORDER BY lastname ASC
Здесь ключевое слово ASC обозначает сортировку по возрастанию, если необходим обратный порядок сортировки, используйте DESC.
Получить список преподавателей с именем Александр
SELECT * FROM prepods WHERE firstname='Александр'
Результатом данной выборки будет таблица, в которую попадут только те преподаватели кафедры имя которых Александр.
Получить список студентов фамилия которых начинается на букву «А»:
SELECT * FROM students WHERE lastname LIKE 'А%'
Здесь ключевое слово LIKE позволяет осуществить выборку по подстроке. Знак процента % показывает что здесь могут быть любые другие данные.
Для обеспечения связи двух таблиц в результирующей выборке можно воспользоваться условием в разделе WHERE:
SELECT students.lastname, students.firstname,
groups.number FROM students, groups WHERE
students.group_id = groups.id
Результатом выполнения данного запроса будет выборка состоящая из фамилии, имени и номера группы студента.
Продемонстрируем пример с использованием псевдонимов:
SELECT s.lastname AS 'Фамилия', s.firstname AS 'Имя' FROM
students s WHERE s.firstname LIKE 'О%'
Результатом данной выборки будет таблица с двумя столбцами: «Фамилия» и «Имя», строками таблицы будут студенты имя которых начинается с буквы «О».