 2014-02-01
2014-02-01 792
792Статистической гипотезой называется определенное предположение о свойствах распределения вероятностей, которым описываются наблюдаемые случайные величины.
Пусть, например, мы имеем выборку { x1, x2, …, xn } значений случайной величины X, удовлетворяющей нормальному распределению с математическим ожиданием EX= m и дисперсией DX= s 2. Рассматривая выборочные значения xi, мы можем предположить, например, что m=0. Назовем это предположение основной или нулевой гипотезой Н0. Наряду с основной обычно рассматривают альтернативную гипотезу Н1, которая может состоять в отрицании основной (m ≠ 0), но может иметь и другой вид. Если, например, есть веские основания полагать, что m=1, это значение принимаем в качестве гипотезы Н1.
Располагая выборочными данными, мы можем сделать правильный выбор между конкурирующими гипотезами Н0 и Н1 только с большей или меньшей вероятностью. Если мы отвергаем основную гипотезу Н0, а она на самом деле верна, то мы совершаем ошибку, которую принято называть ошибкой первого рода. Если же мы принимаем гипотезу Н0, а она не верна, то мы совершаем ошибку второго рода.
Вероятность α отвергнуть основную гипотезу в случае, когда она верна, т.е. совершить ошибку 1-го рода, называется уровнем значимости нулевой гипотезы. Обычно уровень значимости полагают равным 0,05 или 0,01. Если нулевая гипотеза не верна, но мы ее принимаем, то совершается ошибка 2-го рода, вероятность которой обозначается β. Число (1 – β) называется мощностью критерия и указывает на вероятность правильного выбора альтернативной гипотезы Н1.
Перечисленные варианты выбора основной гипотезы приведены на рис.7.

Рис. 7. Схема вариантов выбора основной гипотезы.
В приведенном примере выбор между гипотезами Н0: m=0 и Н1: m=1 сделаем, используя случайную величину
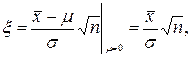
распределенную по нормальному закону x ÎN (0,1), если величина s известна, или случайную величину
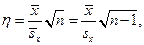
имеющей распределение Стьюдента с n-1 степенями свободы, если величина стандартного отклонения s нам неизвестна и оценивается по выборке. В обоих случаях определяем число k, такое что
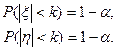 (14.1)
(14.1)
Если найденное по выборке значение x или h удовлетворяет условию |x|< k или |η|< k, то основная гипотеза Н0: m=0 принимается с уровнем значимости α. Промежуток [ -k,k ] определяет область принятия основной гипотезы. Если выполняются неравенства
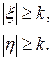 (14.2)
(14.2)
то гипотеза Н0 отвергается, при этом вероятность ошибки первого рода равна α.
Геометрическая интерпретация наших выводов заключается в том, что площадь под графиком плотности нормального распределения или распределения Стьюдента, ограниченного промежутком [ -k,k ], равна 1-α (рис.8). Вероятность того, что значения x или h удовлетворяют неравенствам (14.2) при условии, что основная гипотеза Н0 верна, равна a.
Аналогичные рассуждения проводятся в случае парной линейной регрессии
yi=a+bxi+ei, i= 1,2 ,…,n.
Если, например, коэффициент b равен нулю, то зависимость между величинами x и y отсутствует. Примем в качестве основной гипотезы утверждение Н0: b= 0. Известно, что величина tb=b̃/Sb имеет распределение Стьюдента с n- 2 степенями свободы. Найдем границу области принятия основной гипотезы k=t(n- 2, α ) из условия P(|tb|<k)= 1 - α.
Если неравенство |tb| < k выполняется, то принимаем гипотезу b= 0 с уровнем значимости α. Если же |tb| ≥ k, то полагаем, что коэффициент b значимо отличен от нуля. Аналогичные рассуждения можно провести для коэффициента a, рассматривая отношение ta=ã/Sa.
Компьютерные статистические программы, например, Statistica, выводят величину уровня значимости p, т.е. вероятности совершить ошибку первого рода, в точности отвечающего имеющимся данным. В примере с коэффициентом b это означает, что P (| t| ≥ |tb|) = p.
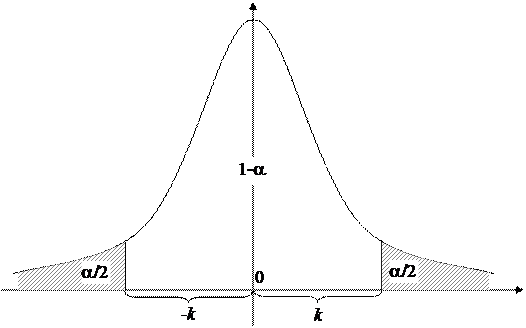
Рис.8. Область принятия основной гипотезы.
Значимость регрессионной модели определяется также с помощью
F -критерия Фишера. Для этого в случае множественной регрессии вычисляется отношение (см.7.1):
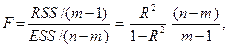
где
n — число наблюдений;
m — число оцениваемых параметров;
R2 — коэффициент детерминации;
RSS — сумма квадратов отклонений yi от среднего `y, объясненная регрессией;
ESS — остаточная сумма квадратов отклонений yi от расчетных значений (см. §7).
Для парной регрессии m=2, эта формула принимает вид(см.7.2):
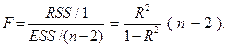
Можно сказать, что F -критерий определяет отношение факторной и остаточной дисперсии, рассчитанных на одну степень свободы. В качестве основной гипотезы принимаем, что между переменными xi и y нет функциональной зависимости. Если эта гипотеза справедлива, то факторная и остаточная дисперсии мало отличаются друг от друга. Для опровержения основной гипотезы необходимо, чтобы факторная дисперсия превышала остаточную в несколько раз.
Величина F имеет распределение Фишера с ν 1=m и ν 2=n-m- 1 степенями свободы [4]. Задавая уровень значимости α (в частности, принимая α = 0,05) и находя из таблиц или с помощью пакетов MS Excel, Statistica и др. величину Fтабл (ν 1, ν 2, α), сравниваем вычисленное значение F и Fтабл. Если F > Fтабл, то уровень регрессии признается статистически значимым и основная гипотеза отвергается. Если же F < Fтабл, то основная гипотеза принимается, т.е. зависимость между x и y считается несущественной.








