 2018-03-08
2018-03-08 168
168Статистика
(решение примеров с применением Excel)
Владимир, 2009
Рецензент
Рекомендовано к изданию учебно-методическим советом и
кафедрой информационных технологий Владимирского филиала РАГС.
Практикум предназначен для выполнения заданий по дисциплине «Статистика» с использованием статистических функций и иных инструментов электронной таблицы Excel. Пояснительный текст сопровождается примерами исполнения и заданиями для самостоятельной работы. Выполнение заданий требует знаний студентами основ работы с Excel. Практикум позволит студентам приобрести навыки выполнения статистических расчетов на компьютере. В приложении приведены статистические функции программы Excel.
Предназначен для студентов управленческих и экономических специальностей. Может быть полезен специалистам, выполняющим обработку и анализ статистической информации.
ОГЛАВЛЕНИЕ
| Введение | |
| 1 Общие сведения о статистике | |
| 1.1 Статистический ряд распределения | |
| 1.2 Выборка | |
| 1.3 Описательная статистика | |
| 1.3.1 Средняя арифметическая | |
| 1.3.2 Медиана | |
| 1.3.3 Мода | |
| 1.3.4 Дисперсия | |
| 1.3.5 Стандартное отклонение | |
| 2 Функции распределения | |
| 2.1 Нормальное распределение | |
| 2.2 Обратная функция нормального распределения | |
| 2.3 Доверительная вероятность | |
| 2.4 Иные функции распределения | |
| 2.4.1 Гамма-распределение | |
| 2.4.2 Бета-распределение | |
| 2.4.3 Логарифмическое нормальное распределение | |
| 2.4.4 Экспоненциальное распределение | |
| 2.4.5 Распределение Пирсона | |
| 2.4.6 Распределение Стьюдента (t – распределение) | |
| 2.4.7 Распределение Фишера (F – распределение) | |
| 2.4.8 Статистические функции дискретных распределений | |
| 3 Режим "Описательная статистика" | |
| 4 Статистические методы изучения взаимосвязей явлений и процессов | |
| 4.1 Ковариация и корреляция | |
| 4.2 Линейная регрессия | |
| 4.3 Нелинейная регрессия | |
| 5 Статистические методы изучения динамики процессов | |
| 5.1 Скользящие средние и экспоненциальное сглаживание | |
| 5.2 Трендовые модели | |
| 6 Задания для самостоятельной работы | |
| Использованные источники | |
| Приложение | |
Введение
Статистика – это наука, изучающая количественную сторону массовых явлений и процессов в неразрывной связи с их качественной стороной, количественное выражение закономерностей общественного развития в конкретных условиях места и времени. Для получения статистической информации органы государственной и ведомственной статистики, а так же коммерческие структуры проводят различного рода статистические исследования. Процесс статистического исследования включает три основные стадии: сбор данных, их сводка и группировка, анализ и расчет обобщающих показателей. Именно статистические исследования позволяют определить объемы валового внутреннего и регионального продукта, выявить основные тенденции развития отраслей экономики и их взаимосвязи, оценить уровень инфляции проанализировать состояние финансовых и товарных рынков, исследовать уровень жизни населения и другие социально-экономические явления и процессы.
На всех стадиях исследования могут быть использованы технологии, как общего, так и специального характера, представленные в электронных таблицах. Так электронная таблица Excel позволяет выполнять необходимые процедуры не только по сводке и группировке данных, построению необходимых диаграмм и графиков, но и выполнению специальных расчетов применением функций из категории «Статистические» и инструментов из «Пакета анализа».
1 Общие сведения о статистике
1.1 Статистический ряд распределения
Результаты сводки и группировки материалов статистического наблюдения оформляются в виде таблиц и статистических рядов распределения.
Статистический ряд распределения – упорядоченное распределение единиц изучаемой совокупности по определенному варьирующему признаку. Он характеризует состояние (структуру) исследуемого явления:
§ однородность совокупности;
§ границы ее изменения;
§ закономерности развития наблюдаемого объекта.
В зависимости от признака, положенного в основу образования ряда распределения, различают ряды распределения:
§ атрибутивные;
§ вариационные.
В зависимости от характера вариации вариационные ряды распределения делятся на:
§ дискретные;
§ непрерывные (интервальные).
Ряды распределения удобнее анализировать с помощью их графического изображения (видна форма распределения или характер изменения частот вариационного ряда). Различают два вида графического изображения рядов распределения:
§ полигон;
§ гистограмма.
Полигон используется для изображения дискретных вариационных рядов. По оси абсцисс откладывается ранжированные значения варьирующего признака, а по оси ординат наносится шкала частот (число случаев, в которых встречалось то или иное значение признака). Кроме частот иногда наносятся частость вариационного ряда, выраженная в процентах (долях) к итогу. Вместо частости используется термин «статистическая вероятность».
Пример 1.1 В таблице 1.1 приведено распределение жилого фонда городского района по типу квартир. Построен полигон (рис.1.1) для данного распределения.
Таблица 1.1
| № п/п | группы квартир по числу комнат | число квартир, тыс. ед. |
| 1 | 1 | 10 |
| 2 | 2 | 35 |
| 3 | 3 | 30 |
| 4 | 4 | 15 |
| 5 | 5 | 5 |
| всего | 95 | |

Рис.1.1
Гистограммы применяются для изображения интервальных вариационных рядов распределения. По оси абсцисс откладывается значения интервалов, а частоты изображаются прямоугольниками, построенными на соответствующих интервалах.
Пример 1.2 В таблице 1.2 приведено распределение семей по размеру жилой площади, приходящейся на одного человека. Построена гистограмма (рис.1.2) по таблице 1.2.
Таблица 1.2
| № п/п | размер жилой площади, приходящейся на одного человека, м2 | число семей с данным размером жилой площади | число семей нарастающим итогом |
| 1 | 3-5 | 10 | 10 |
| 2 | 5-7 | 20 | 30 |
| 3 | 7-9 | 40 | 70 |
| 4 | 9-11 | 30 | 100 |
| 5 | 11-13 | 15 | 115 |
| всего | 115 |
| |

Рис.1.2
Гистограмму можно преобразовать в полигон, соединив верхние стороны прямоугольников прямыми линиями.
В примере 1.2 интервалы имеют одинаковую величину, поэтому высота столбиков гистограммы пропорциональна частотам ряда распределения. Если интервалы различны, то это не даст правильно оценить характер распределения по данному признаку. В подобных случаях для обеспечения необходимой сравнимости исчисляется плотность статистического распределения, которая определяет, сколько единиц в каждой группе приходится на единицу величины интервала.
Пример 1.3 В таблице 1.3 приведено распределение магазинов по размеру товарооборота. При оценке плотности распределения делением значений частот (числа магазинов) на величину интервала, оказалось, что чаще встречаются магазины с товарооборотом 50-120 тыс. руб., а по абсолютному значению (через сравнение частот) результат был 250-450 тыс. руб. При построении гистограмм (рис.1.3) вариационного ряда с неравными интервалами используются не частоты, а плотности распределения значений изучаемого признака в соответствующих интервалах.
Таблица 1.3
| № п/п | размер товаро- оборота, тыс. руб. | число магазинов | величина интервала, тыс. руб. | плотность распределе- ния (3/4) |
| 1 | 2 | 3 | 4 | 5 |
| 1 | до 50 | 25 | 50 | 0,50 |
| 2 | 50-120 | 45 | 70 | 0,64 |
| 3 | 120-250 | 65 | 130 | 0,50 |
| 4 | 250-450 | 80 | 200 | 0,40 |
| 5 | 450-980 | 20 | 530 | 0,04 |
| итого | 235 |
|
| |

Рис.1.3
Пример 1.4 В таблице 1.4 приведено распределение по годам семейной жизни относительная численность разводов. Используя прием из примера 1.3, получена плотность распределения. Как видно из примера, наибольшее количество разводов приходится на интервалы семейной жизни 5-9 лет и 10-19 лет (половина от общего количества разводов, т.е. в сумме 50%). Однако наибольшая плотность распределения количества разводов (количество разводов за год) приходится на интервалы семейной жизни 3-4 года и 1-2 года, т.е. на сроки существования семьи от 1 до 4 лет.
Таблица 1.4
| № п/п | интервалы лет семейной жизни | количество разводов к общей численности, % | величина интервала, года | плотность распределения разводов |
| 1 | 0-1 | 3,6 | 1 | 3,60 |
| 2 | 1-2 | 16,0 | 1 | 16,00 |
| 3 | 3-4 | 18,0 | 1 | 18,00 |
| 4 | 5-9 | 28,0 | 4 | 7,00 |
| 5 | 10-19 | 22,0 | 9 | 2,44 |
| 6 | 20-30 | 12,4 | 10 | 1,24 |

Рис.1.4
В практике экономической работы возникает потребность в преобразовании рядов распределения в кумулятивные ряды, которые строятся по накопленным частотам. С их помощью можно определять структурные средние и наблюдать за процессом концентрации изучаемого явления (кривые Лоренца). По примеру 1.2 построена кумулята для интервального ряда распределения. Если полигон рассматривается в качестве статистического аналога плотности распределения, то кумулята статистического аналога функции распределения.

Рис.1.5
Выборка
В зависимости от полноты охвата изучаемого явления или объекта, когда исследуются массовые статистические явления, различают наблюдение:
§ сплошное;
§ несплошное.
Разновидность несплошного наблюдения – выборочное.
Выборочное наблюдение – метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора. Обследованию подвергается сравнительно небольшая часть всей изучаемой совокупности, получившая название выборочная совокупность или выборка.
Выборка должна быть представительной (репрезентативной), чтобы по ней можно было судить о генеральной совокупности. При отборе объектов могут сыграть роль личные мотивы или психологические факторы, о которых исследователь, проводящий выборку, может и не подозревать. В этом случае выборка не будет репрезентативной. Для предупреждения систематических (тенденциозных) ошибок выборочного обследования применяются различные научно обоснованные способы формирования выборочной совокупности, в зависимости от которых выборка может быть:
§ собственно-случайной;
§ механической;
§ типической;
§ серийной;
§ комбинированной.
Собственно-случайная выборка состоит в том, что выборочная совокупность образуется в результате случайного (непреднамеренного) отбора отдельных единиц из генеральной совокупности. Различают две схемы собственно-случайной выборки:
§ повторный отбор;
§ бесповторный отбор.
Повторный отбор предполагает возможность включения в выборку одного и того же элемента генеральной совокупности два раза и более.
На практике для организации собственно-случайной выборки используют таблицу случайных чисел или генератор случайных чисел.
Важной проблемой выборочного метода является определение объема выборки, достаточной для получения истинных характеристик генеральной совокупности. Необходимая численность собственно-случайной повторной выборки определяется выражением
 (1.1)
(1.1)
где  - предельная ошибка выборки;
- предельная ошибка выборки;
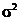 - дисперсия генеральной совокупности;
- дисперсия генеральной совокупности;
t - коэффициент доверия.
Трудность использования формулы на практике – расчет генеральной дисперсии . Для ее оценки используются материалы предыдущих исследований, или производственно-технические нормативы, или проводится пробное обследование.
Пример 1.5 Фирма решила для посетителей своего сайта еженедельно разыгрывать лотерею. Для этого на сайте организован счетчик посетителей с заполнением адреса. За неделю сайт посетили 35 пользователей. Номера посещений и адреса приведены в таблице 1.5. Фирма решила разыграть 5 призов, для чего использовался режим «Выборка» для Excel. Приведен результат выборки с пятью номерами посетителей. Причем под номером 365 адрес не указан, значит, выигрыш посылать некому.
| номер посещения | информация о регистрации адреса |
| 361 | г.Москва, Воздвиженка, 17, 56. |
| 362 | г.Владимир, Зеленая, 45, 33 |
| 363 | г.Москва, Курская, 90, 32 |
| 364 | г.Ярославль, Северная, 7, 9 |
| 365 | Адрес не указан |
| 366 | г.Владимир, Мира, 89, 78 |
| 367 | г.Владимир, Московская, 11, 45 |
| 368 | г.Москва, Сретинка, 13, 56 |
| 369 | г.Москва, Третьяковская, 11, 90 |
| 370 | г.С.Петербург, Победы, 78, 435 |
| 371 | г.Суздаль, Огуречная, 12 |
| 372 | г.Ковров, Дегтярева, 18, 34 |
| 373 | г.Муром, Фестивальная, 20, 3 |
| 374 | г.Мурманск, Озерная, 16, 89 |
| 375 | г.Астрахань, Лесная, 78 |
| 376 | г.Иваново, Текстильная, 90, 3 |
| 377 | г.Владимир, Горького, 36 |
| 378 | г.Владимир, Октябрьский, 21 |
| 379 | г.Владимир, Музейная, 36, 5 |
| 380 | г.Тверь, Волжская, 23, 45 |
| 381 | г.Тамбов, Крутая, 8, 45 |
| 382 | г.Мценск, Песочная, 28, 20 |
| 383 | Адрес не указан |
| 384 | г.Саратов, Южная, 89 |
| 385 | г.Смоленск, Беговая, 14, 90 |
| 386 | г.Кутуково, Шерстяная, 44, 78 |
| 387 | г.Чита, Амурская, 34, 1 |
| 388 | г.Серов, Уральская, 34, 70 |
| 389 | г.Чернигов, Невская, 90. 100 |
| 390 | г.Волгоград, Верная, 70, 23 |
| 391 | г.Королев, Гагарина, 69, 39 |
| 392 | г.Череповец, Правды, 12, 90 |
| 393 | г.Н-Новгород, Соборная, 39, 8 |
| 394 | г.Москва, Станиса, 33, 78 |
| 395 | г.Москва, Беговая, 19, 123 |
Таблица 1.5
Результат выборки
| 374 |
| 365 |
| 367 |
| 395 |
| 393 |
Режим работы «Выборка» программы Excel вызывается действием:
Сервис\Анализ данных…\Выборка
Если в меню Сервис отсутствует действие Анализ данных, то его необходимо установить выбором:
Сервис\Надстройки…\Пакет анализа
Пример 1.6. Предприятием «Импульс» за месяц было выпущено 1500 приборов, которым были присвоены номера с 10001 по 11500 включительно. Все приборы выпускаются на основании технической документации, в соответствии с которой дисперсия чувствительности приборов =25 мкВ2/м2. необходимо на основе повторного собственно-случайного отбора сформировать контрольную выборку. Уровень надежности выборки должен быть не менее 95%, а предельная ошибка не превышала величины =3 мкВ/м.
В отличие от примера 1.5 здесь необходимо определить объем выборки n по формуле (1.1). Для расчета надо найти коэффициент доверия t,который вычисляется в Excel через функцию СТЪЮДРАСПОБР (находится в категории «Статистические» Мастера Функций). Вид функции после заполнения:
=СТЪЮДРАСПОБР(0,05;1499)
где 0,05=1-0,95 – требуемый уровень значимости;
1499=1500-1 – число степеней свободы.
При использовании этой функции получено t =1,96.
Подставляя исходные данные в формулу (1.1), получим объема выборки:
 (приборов).
(приборов).
Последующая технология решения аналогична примеру 1.4 для быстрого ввода исходных данных (1500 цифр) в Excel можно воспользоваться арифметической прогрессией через следующее действие:
Правка/Заполнить/Прогрессия…
После в открывшемся окне занести необходимую информацию.
В результате решения задачи появилась выборка из 11 приборов с заводскими номерами:
| 10345 |
| 10813 |
| 11010 |
| 11036 |
| 10083 |
| 10263 |
| 10209 |
| 11211 |
| 11305 |
| 11498 |
| 10802 |
Пример 1.7 Формирование выборки на основе схемы повторного собственно-случайного отбора можно осуществлять в режиме «Выборка» в программе Excel для периодических данных. В таблице 1.6 приведена сравнительная динамика платных услуг населению в сопоставимых ценах в 2007 и 2008 годах. Необходимо построить динамику по кварталам. Для реализации этого необходимо в окне «Выборка» выбрать метод выборки «Периодический» и указать величину периода 4 (для каждого года проводить отдельно). Если есть какие-либо данные по месяцам за несколько лет, то величина периода будет 12 для выборки информации по годам.
Таблица 1.6
|
| 2007 | 2008 |
| январь | 173,0 | 146,9 |
| февраль | 175,3 | 155,2 |
| март | 186,2 | 166,7 |
| 1 квартал | 534,5 | 468,8 |
| апрель | 186,1 | 162,3 |
| май | 184,9 | 157,5 |
| июнь | 207,7 | 178 |
| 2 квартал | 578,7 | 497,8 |
| июль | 239,2 | 209,3 |
| август | 225,3 | 199,3 |
| сентябрь | 218,5 | 195 |
| 3 квартал | 683,0 | 603,6 |
| октябрь | 213,4 | 193,6 |
| ноябрь | 232,0 | 216,8 |
| декабрь | 216,8 | 204,2 |
| 4 квартал | 662,2 | 614,6 |
В результате выполнения функции «Выборка» получена таблица 1.7.
Таблица 1.7
|
| 2007 | 2008 |
| 1 квартал | 534,5 | 468,8 |
| 2 квартал | 578,7 | 497,8 |
| 3 квартал | 683,0 | 603,6 |
| 4 квартал | 662,2 | 614,6 |
По этой таблице можно строить график динамики поквартально. Вариант такого построения приведен на рис.1.6.

Рис.1.6
1.3 Описательная статистика
Статистическая информация представляется совокупностью данных, для характеристики которых используются разнообразные показатели, называемые показателями описательной статистики. Примеры описательной статистики: уровень образования, прожиточный минимум, дифференциация доходов населения, среднее число детей в семье, средний курс доллара и мера его колебания за определенный интервал времени, продолжительность жизни и т.д.
Показатели описательной статистики можно разбить на несколько групп:
1. Показатели положения. Описывают положение данных на числовой оси (максимальный и минимальный элемент выборки, сведения о середине совокупности – средняя арифметическая, средняя гармоническая, медиана и т.д.).
2. Показатели разброса. Описывают степень разброса данных относительно своего центра. К ним относятся дисперсия, стандартное отклонение, размах выборки (разность между максимальным и минимальным элементами), эксцесс т.д.
3. Показатели асимметрии. Характеризуют симметрию распределения данных около своего центра. К ним относятся коэффициент асимметрии, положение медианы относительно среднего и т.д.
4. Показатели, описывающие закон распределения. Дают представление о законе распределения данных. Сюда относятся таблицы частостей, полигоны, кумуляторы, гистограммы.
На практике чаще всего используются следующие показатели:
§ средняя арифметическая;
§ медиана;
§ дисперсия;
§ стандартное отклонение;
§ гистограммы.








