 2020-06-12
2020-06-12 79
79Исходным материалом для последующих расчетов также служат индивидуальные задания на выполнение этого этапа работы и дидактический материал для их выполнения (Приложение 7.1. – файл «Корреляция» электронных таблиц Microsoft Excel). Дидактический материал представлен таблицами исходных данных (первичная лесоводственная информация) и блоком алгоритмов для их соответствующей обработки и получения статистических результатов (производная лесоводственная информация).
Расчет коэффициента ранговой корреляции Спирмена включает в себя ряд этапов.
1. На первом этапе осуществляют ранжирование значений каждого из двух вариационных рядов, содержащих оценки двух признаков (параметров или непараметрических характеристик в оценках порядковой шкалы). Для этого используют возможности встроенных функций электронных таблиц Microsoft Excel. Перед выполнением процедуры ранжирования создают копии значений исходных вариационных рядов. В начале следует выбрать и выделить ранжируемый диапазон значений (в нашем случае копия ранжируемого вариационного ряда по первому признаку). Например, был выделен диапазон В4:В56. Далее в меню главной строки («ГЛАВНАЯ») следует выбрать иконку «Сортировка и фильтр», в списке команд которой указать («кликнуть») «Настраиваемая сортировка». В представленном экране управления функцией сортировки нужно выбрать её требуемый режим и запустить процедуру, нажав на кнопку «ОК». В результате этих действий выделенный диапазон значений будет отсортирован в заданном порядке (в порядке убывания значений ил наоборот). В ячейках напротив каждого цифрового значений ранжированного ряда записывают порядковые номера – ранги каждого из значений. После этого установленные ранги присваивают значениям исходного вариационного рядя, записывая их в соответствующих ячейках напротив значений. Пусть полученный в таком порядке ряд рангов будет иметь адреса ячеек: А4:А56. Процедуру в полном объеме повторяют для второго вариационного ряда. Адреса полученных значений соответственно будут С4:С56 и D4:D56 Полученные в итоге два ряда ранговых оценок с адресам А4:А56 и С4:С56, используются в дальнейших расчета.
2. На втором этапе реализуют вычисление промежуточных значений показателей, необходимых для нахождения коэффициента ранговой корреляции Спирмена, согласно означенному ранее алгоритму и используя указанные выше формулы. Вначале находят разности ранговых оценок. Алгоритмизированная запись в командной строке электронных таблиц Microsoft Excel указанного этапа вычислений при последовательном линейном копировании каждого действия примет вид:
Е4 = А4 – С4.
Далее находят суммы квадратов полученных разностей рангов. Алгоритмизированная запись в командной строке электронных таблиц Microsoft Excel указанного этапа вычислений при последовательном линейном копировании каждого действия примет вид:
= СУММКВ(Е4:Е56).
3. На заключительном этапе вычисляю величину коэффициента корреляции рангов для случая, когда отсутствуют совпадающие значения рангов. Алгоритмизированная запись в командной строке электронных таблиц Microsoft Excel указанного этапа вычислений примет вид:
= 1 – 6 / (СЧЕТ(Е4:Е56) * (СЧЕТ(Е4:Е56)^2 – 1))*(СУММКВ(Е4:Е56)
или:
= 1 – 6*(СУММКВ(Е4:Е56) / (СЧЕТ(Е4:Е56)^3 – СЧЕТ(Е4:Е56)).
Для подтверждения статистической значимости полученного коэффициента корреляции рангов вычисляют величину его стандартной статистической ошибки по следующей общепринятой формуле:
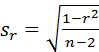 ,
,
где:
- sr – стандартная ошибка коэффициента корреляции;
- r – коэффициент корреляции;
- n – численность выборки или число парных учетов, по которым вычислен выборочный коэффициент корреляции.
Статистическая значимость коэффициента корреляции определяется при помощи t-критерия Стьюдента, исходя из результатов сопоставления величины его стандартной статистической ошибки с величиной самого коэффициента. Если расчетное значение t-критерия меньше табличного при заданном числе степеней свободы и на установленном уровне значимости, статистическая значимость исследуемой взаимосвязи отсутствует. Если больше или равно, то корреляционная связь считается статистически значимой. Величину критерия существенности коэффициента корреляции рассчитывают, используя полученную величину стандартной ошибки, по следующей формуле:
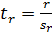 ,
,
где:
- t r – критерий существенности коэффициента корреляции;
- sr – стандартная ошибка коэффициента корреляции;
- r – коэффициент корреляции.
Поскольку расчетное значение коэффициента корреляции есть случайное значение его сопоставляют с табличным значением на заданном уровне значимости. Если расчетное значение t-критерия меньше табличного при заданном числе степеней свободы и на установленном уровне значимости, статистическая значимость наблюдаемой взаимосвязи - отсутствует. Если больше или равно, то корреляционная связь считается статистически значимой.
Нередко характеристика связи на основе коэффициента корреляции дается в форме качественных оценок. Для этого используется шкала Чеддока.
Шкала Чеддока
| Количественная мера тесноты связи | Качественная характеристика силы связи |
| 0,1 - 0,3 | Слабая |
| 0,3 - 0,5 | Умеренная |
| 0,5 - 0,7 | Заметная |
| 0,7 - 0,9 | Высокая |
| 0,9 - 0,99 | Весьма высокая |
Хотя считается, что эта шкала довольно условна, и в разных изданиях можно обнаружить её варианты для четырех или для пяти градаций. Однако благодаря ей становится возможным выразить численное (количественное) значение какого-либо из коэффициентов корреляции в качественных характеристиках.
Обучающиеся выполняют лабораторную работу в индивидуальных файлах электронных таблиц Microsoft Excel (файл «Корреляция») на листе с пометкой «Рабочий». Полученные результаты и их анализ фиксируют там же.








