2014-02-02
2014-02-02 1195
1195Мы рассмотрели методы, позволяющие формировать обобщенные описания ситуаций в соответствии с теми решениями, которые были приписаны ситуациям, входившим в обучающую выборку. В процессе функционирования системы работа по формированию классов ситуаций и уточнению ранее сформированных классов происходит постоянно, так как обучающая выборка может не исчерпывать всего богатства возможных ситуаций, складывающихся на объекте управления.
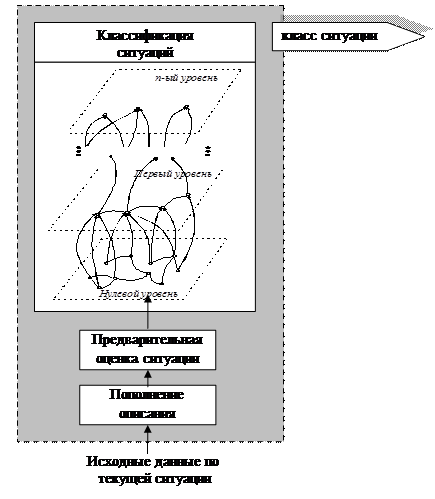

Рис. 4.1
Обобщение может происходить на многих этапах, и поэтому исходные описания ситуаций и обобщенные их описания образуют иерархическую структуру, в каждом слое которой находятся описания, полученные из исходных с помощью тех или иных процедур обобщения. Если исходные описания принять за нулевой уровень, то на первом уровне будут находиться описания, полученные непосредственно из описаний ситуаций, лежащих на нулевом уровне. На второй уровень попадут описания, которые возникнут за счет применения процедур обобщения к описаниям первого уровня и т. д. Так возникает «слоеный пирог», показанный на рис. 5. Ситуации на всех уровнях обобщения соответствуют некоторым решениям по управлению. В идеальном случае на самом верхнем уровне системы классификации возникают описания, каждому из которых соответствует определенное решение по управлению. В более частых случаях при недостаточной обучающей выборке окончательное разделение классов может и не произойти. Оно никогда не наступает при недетерминированном процессе формирования обобщенных ситуаций.
Если решения по управлению сами обладают некоторой структурой, то при формировании «слоеного пирога» требуется соотнести уровни управления в структуре принимаемого управленческого решения с уровнями классификатора.
Если имеется управление (решение) U, которое состоит из п последовательных управлений, то в «слоеном пироге» возникает п уровней классификации. Иерархичность управления позволяет формировать обобщенные описания за существенно меньшее число шагов, чем в общем случае.
Таким образом, блок обобщения и классификации ситуаций представляет собой многослойную сеть. При его построении выполняется следующая последовательность процедур. Сначала исходное описание текущей ситуации пополняется всеми дополнительными сведениями за счет работы процедур пополнения описаний. Затем к полученным описаниям применяются процедуры обобщения. Полученные результаты, относящиеся к первому уровню «слоеного пирога», рассматриваются снова, как исходное описание. К ним вновь применяются методы пополнения и происходит очередной шаг обобщения. Так продолжается до тех пор, пока на очередном уровне к полученным фрагментам нельзя будет применить ни процедур пополнения, ни процедур обобщения, не приводящих к противоречивым управленческим решениям.
Некоторые математические методы процедур обобщения и классификации
Алгоритм «кора» (М.М. Бонгард)
М.М. Бонгард анализируя недостатки алгоритма работы персептрона Розенбалата, предложил некоторые существенные усовершенствования этого алгоритма для задач распознавания образов (в частности, геометрических образов, а также «узнавания» законов формирования арифметических таблиц). В качестве ключевого недостатка персептрона он указывал тот факт, что связи А‑элементов с рецепторами не зависят от того, какую задачу должен решать перцептрон — эти связи устанавливаются с помощью жребия еще до того, как перцептрону показывают материал обучения.
Алгоритм, предложенный Бонгардом, состоит из 4 блоков, которые он, назвал: 1) биполярные клетки; 2) ганглиозные клетки; 3) подкорка и 4) кора.
Проецируя структуру данной схемы Бонгарда на нашу задачу, можно установить следующее соответствие: 1) биполярные клетки — сбор исходных данных о ситуации (мониторинг); 2) ганглиозные клетки — проверка данных, выполнение простейших аналитических операций над данными; 3) подкорка — предварительный анализ ситуации, преобразование вектора признаков всех объектов, 4) кора — обобщение описания ситуаций и отнесение ситуации к одному из известных классов, либо в случае невозможности такого отнесения — образование нового класса событий.
Важной особенностью является «многоэтажность» данного алгоритма. При этом результат обучения разных этажей может обладать разной степенью всеобщности (биполяры не обучаются, ганглиозные учатся для совокупности задач, подкорка и кора— для данной задачи). При таком подходе встретившись с новой задачей, система начинает переучивать верхние, наименее стабильные этажи. И только если такое переучивание не дает результата («резко изменился мир»), начинается переучивание нижних этажей.
Очевидно, в рамках решаемых нами задач наибольший практический интерес представляет работа последнего из перечисленных блоков — коры, являющейся, по сути, блоком поиска разделяющего правила среди логических функций.
В качестве составных частей разделяющего правила имеет смысл рассматривать не все возможные на данном языке фразы, а только те, которые дают на выходе коротко закодированную информацию. Если выполняется это требование, то каждый аргумент разделяющего правила будет или категорическим высказыванием типа «да — нет» (если на выходе фразы один двоичный разряд), или будет состоять из очень небольшого числа таких высказываний. Поэтому целесообразно рассматривать разделяющее правило как некоторую логическую функцию высказываний.
На концептуальном уровне алгоритм работы блока «кора» можно представить следующим образом.
1 этап. Этот этап не входит непосредственно в блок «кора», а является как бы подготовительным (по сути это выход блока «подкорка»). На этом этапе происходит выделении бинарных признаков (переход от произвольных признаков к двоичным теоретически всегда возможен — для этого достаточно считать, что каждое допустимое значение признака выступает как самостоятельный признак или что на множестве его значений введены какие-то предикаты, превращающие их значения в двоичные переменные).
2 этап. Генерируются случайным образом функции от получившихся двоичных аргументов, принимающие также двоичные значения. Каждая такая функция рассматривается как потенциальное элементарное разделяющее правило.
3 этап. Выбор эффективных разделяющих правил таких, что для всех отрицательных примеров функция обращается в 0, а для положительных — хотя бы один раз 1 (но чем больше, тем разделяющее правило лучше).
4 этап. Логическое объединение (дизъюнкция) всех эффективных разделяющих правил в одно глобальное правило.
5 этап. Проверка (верификация) глобального правила на обучающей выборке — проверка правильности построения и исключение избыточности.
6 этап. Проверка глобального правила на экзаменационной выборке. Если на экзаменационной выборке разделяющее правило работает неверно, то эта выборка рассматривается как дополнительная часть обучающей выборки и процедура поиска разделяющего правила повторяется заново (переход ко второму этапу).
Работа алгоритма «кора» базируется на следующих принципах.
1) Система, способная обучаться на разном числе примеров, обязательно должна обладать достаточно высокой начальной организацией. И эта организация не может быть достигнута в ходе предварительного обучения. Она должна быть привнесена извне конструктором системы.
2) «Кора» относится ко входному материалу предельно формально. Она ищет логические функции от каждой из пар признаков, совершенно «не задумываясь» над смыслом этих функций. Единственный критерий поиска—сечение, производимое функцией на пространстве признаков.
С одной стороны, в этом — слабость коры. Она проверяет все логические функции от всех бинарных признаков, в то время как, «понимая» их смысл, кора могла бы иногда сократить перебор. С другой стороны, в таком бездумно формальном подходе — источник универсальности коры. Алгоритм работы коры не зависит от того, каково содержательное значение того или иного набора признаков.
3) В кору попадают только коротко кодируемые параметры. Естественно наложить то же ограничение и на кору. В применении к коре рассматриваемого типа краткость означает, что описание содержит малое число конъюнкций. Другими словами, описание классов должно состоять из небольшого числа высказываний, соединенных связкой «или». Это обусловливает необходимость ввода определенных критериев отбора при обучении:
— запоминаемая в качестве признака конъюнкция должна быть истинна на достаточно большом числе объектов обучения некоторого класса (требование, чтобы каждая конъюнкция характеризовала много объектов, по существу, совпадает с требованием создания обобщенного описания класса, а не запоминания объектов из материала обучения);
— необходимо проверять степень независимости разных признаков —во всех вариантах сечение, производимое «кандидатом в признаки» на множестве объектов, должно тем или иным способом сравниваться с сечениями, произведенными уже отобранными признаками;
— конъюнкция, характеризующая объекты одного класса, не должна характеризовать ни одного объекта другого класса.
4) Всюду, где разумно считать объекты состоящими в каком-то смысле из «частей», может оказаться целесообразным строить высказывания, опирающиеся одновременно как на свойства частей, так и на свойства объектов в целом. В этих случаях целесообразно рассматривать многоэтажную кору.
Старшая кора имеет дело с описаниями объектов, и критерием для нее является разделение классов. Материал в нее может поступить непосредственно от операторов, преобразующих весь объект, или от младшей коры.
В младшую кору попадают короткие описания объекта. Ее задача — отделить одни объекты от других, и если это удается, то результат попадает в старшую кору в качестве нового исходного материала. Заметим, что, поскольку критерием для младшей коры является не отделение класса от класса, а лишь разделение объектов на два подмножества, в нее можно даже не вводить информацию о принадлежности объектов тому или другому классу.
Очевидно, в случае необходимости можно построить кору третьего ранга, четвертого ранга и т. д. При этом материалом для коры i- горанга будет служить или результат непосредственной обработки описания частей i -гo ранга оператором развал на кучи, или выход коры (i+1)-гo ранга