 2014-02-12
2014-02-12 2686
2686Выводной анализ
Он включает в себя:
1. Оценку параметров генеральной совокупности
2. Проверку гипотез
Статистические наблюдения или сбор статистических данных на сплошной или не сплошной основе являются первым этапом статистического исследования.
Сплошные опросы всех респондентов, то есть опрос 100%, могут проводиться только в тех случаях, когда количество опрашиваемых не превышает 300-500 человек. Большее количество опросить под силу только государству (перепись населения).
В случае, если опрашиваемая совокупность более 500 человек, то достаточно опросить только выборку и результат опроса выборочной совокупности распределить на генеральную совокупность. Но это возможно только, если выборка репрезентативна, то есть достоверна и отражает структуру генеральной совокупности.
Выборочным называется такое не сплошное наблюдение, при котором признаки регистрируются у отдельных единиц изучаемой статистической совокупности, отобранных с помощью специальных методов, а полученные в процессе исследования результаты с определенным уровнем вероятности распределяются на всю исходную (генеральную) совокупность.
Для обеспечения репрезентативности применяют 2 метода:
- Сбор (отбор) в выборку происходит методом случайных чисел (случайная выборка). Выделяют:
а) случайно-повторную выборку
б) случайно-бесповторную
в) механическую пошаговую выборку
При случайно-повторной выборке попавшая в выборку единицы подвергается обследованию, регистрируются значения ее признаков, а потом она обратно возвращается в генеральную совокупность и наряду с другими вновь может попасть в выборку и быть обследованной.
При бесповторном отборе попавшая в выборку единица подвергается обследованию, но в дальнейшей процедуре отбора уже не участвует.
Если отбор бесповторный, то численность выборки определяется по формуле:
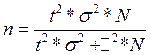
где N – число единиц в изучаемой генеральной совокупности
t – коэффициент доверия, зависящий от вероятности, с которой можно гарантировать, что предельная ошибка выборки не превысит t-кратную среднюю ошибку.
Например, при вероятности 0,990 t = 3
0,999 t = 3,28
Чаще всего в маркетинговых исследованиях опираются на вероятность 0,954, при которой t = 2.
Математик Ляпунов вывел формулу для расчета t, исходя из которой сформирована следующая таблица:
| t (ошибка) | 0,5 | 1,5 | 2,5 | 2,6 | 3,28 | |||
| F – доверительная вероятность | 0,3829 | 0,6827 | 0,8664 | 0,9545 | 0,9876 | 0,9907 | 0,990 | 0,999 |
Проблема в том, что показатели дисперсии и ошибки рассчитываются по результатам опроса, а размер выборки необходимо рассчитать до проведения опроса. Поэтому значение дисперсии σ 2 и Δ определяют на основании эксперимента, пробного обследования или по результатам аналогичных исследований, которые проводились ранее.
σ обычно берут равным 50%, следовательно дисперсия σ 2 будет равна 0,25
Δ – предельная заданная ошибка выборки берется равной 0,05, следовательно ее квадрат будет равен 0,0025.
Для переноса результатов выборочного исследования на генеральную совокупность рассчитывают ошибку выборки по следующей формуле:
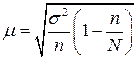
где n – величина выборки
N – величина генеральной совокупности
σ 2 – дисперсия
Пусть Р – генеральная доля, w – выборочная доля, 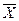 - генеральная средняя,
- генеральная средняя, 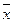 - выборочная средняя, тогда результат будет записан следующим образом:
- выборочная средняя, тогда результат будет записан следующим образом:
для генеральной доли: 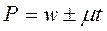
для генеральной средней: 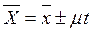
Эти два вида выборок используются, когда необходимо оценить материальный объект (упаковка и тому подобное). А в социальных исследованиях не применяются, так как трудно обеспечить случайность. Поэтому в социальных исследованиях элемент случайности может быть обеспечен с помощью механической выборки.
Механическая выборка заключается в отборе единиц из генеральной совокупности через равные промежутки из определенного расположения их в генеральной совокупности (по алфавиту, по географическому признаку, во времени).
Здесь возникает 2 задачи:
1. определение шага отсчета – расстояния между единицами
2. выбор единицы, с которой надо начинать отсчет
1) Шаг отсчета определяется путем деления численности генеральной совокупности на численность выборочной совокупности. Такой метод применяется, когда N мала.
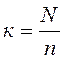
2) Выбор начала отсчета рекомендуется производить путем отбора из единиц первого интервала.
При маркетинговых исследованиях чаще всего применяют неслучайные виды выборок, то есть вводятся элементы неслучайности. Сначала узнают характеристики генеральной совокупности, а потом на основании этих параметров строят выборки. Выборки бывают стихийные (произвольные), квотные (типические), концентрированные, серийные (образованные методом клумб).
Стихийная (произвольная) выборка – элементы выборки отбираются без плана. Такая выборка имеет самую низкую репрезентативность.
Квотная выборка – выборка, в которой сохраняется структура генеральной совокупности по небольшому числу признаков. Эту выборку называют также районированной.
Пример: необходимо опросить 10 тысяч учащихся, выборка составляет 100 человек. Из них в Октябрьском районе – 20%, в Индустриальном – 10%, Первомайском -10%, Устиновском – 10%, Ленинском – 20%. В том числе в Октябрьском районе гимназий 10%, лицеев 20%, общеобразовательных школ – 70%. Следовательно, нужно опросить 2 человека из гимназий Октябрьского района, 4 человека – из лицеев Октябрьского района, 14 человек – из общеобразовательных школ Октябрьского района и так далее.
Серийная выборка – применяется в случаях, когда единицы изучаемой совокупности объединены в небольшие группы или серии (семьи, классы, группы и т.п.) Серии отбираются с помощью механической или случайной выборки, а внутри отобранных серий могут исследоваться как все без исключения единицы, так и выборочно. Эта выборка называется также выборкой методом клумб.
Концентрированная выборка – образуется в том случае, если исследуется важные, наиболее существенные свойства генеральной совокупности, а несущественные отбрасываются. Например, когда необходимо исследовать сбалансированность кадров на предприятиях, берутся только крупные предприятия, а мелкие отбрасываются.
Выборки могут быть сформированы многоступенчатым и многофазным способами.
Многоступенчатый способ предполагает извлечение из генеральной совокупности сначала укрупненных групп единиц, затем групп, меньших по объему, и так до тех пор, пока не будут отобраны те группы или единицы, которые будут подвергнуты наблюдению. То есть выборка производится несколько раз. Причем может быть так, что единица выборки предыдущей стадии будет являться генеральной совокупностью для последующей выборки. Например, производится отбор людей по всему миру: сначала выбирается страна, затем город, потом предприятие и, наконец, группа людей или конкретный человек, которые будут подвергнуты исследованию.
Многофакторная выборка – это такая выборка, когда выборочные совокупности обрабатываются так, что одни сведения собираются для всех единиц отбора, а другие (более глубокие) только для некоторых единиц. Например, опрос потребителей для выявления образа идеального автомобиля: сначала задается вопрос, имеет ли опрашиваемый автомобиль, затем из всех выбирают только тех, кто имеет, и они опрашиваются по более углубленной программе.
Выборочное наблюдение при строгом соблюдении условий случайности и достоверно большой численности отобранных единиц репрезентативно. По результатам изучения определенной части единиц с достаточной для практики степенью точности можно судить о всей совокупности.
Первичную информации можно получить и в результате опроса экспертов. Зачастую оценки экспертов не обладают достаточной устойчивостью, то есть эксперт может одни и те же события оценить по-разному при нескольких повторных экспертизах. Чем устойчивее оценки эксперта, тем больше он заслуживает доверия.
Повторные экспертизы, как правило, очень дороги, следовательно, достоверность оценок можно повысить следующим образом: необходимо проанализировать данные о расхождении экспертных оценок и их действительных значений, найденных в процессе реализации событий, и сделать соответствующие переоценки компетентности экспертов. Для этого применяется:
1. Коэффициент ранговой корреляции (коэффициент конкордации):
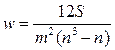
где m – количество факторов (экспертов)
n – число ранжируемых объектов
S – отклонение суммы квадратов рангов от средней квадратов рангов
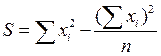
где хi – сумма рангов по i – показателю (объекту)
Значимость коэффициента конкордации проверяется на основании коэффициента Пирсона для степеней свободы 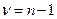 :
:
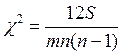
В случае наличия связных рангов применяется следующие формулы для расчета коэффициентов конкордации и Пирсона:
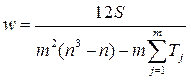
где Т – поправка в связи с наличием связных рангов, рассчитываемая по формуле:
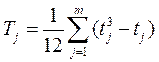
где t – объем каждой группы одинаковых рангов по отдельным показателям (у отдельных экспертов)
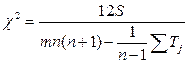
Коэффициент конкордации лежит в интервале (может принимать значения) от -1 до +1

