 2015-04-01
2015-04-01 2083
2083Человеческая жизнь, деятельность больших и малых групп и организаций, функционирование многообразных социальных институтов постоянно фиксируется в
тысячах различных документов. С их помощью информация передается, распространяется, многократно используется, хранится и достигает адресата, сколь бы ни был он отдален в пространстве или во времени.
Для социолога документы, отражающие все сферы
жизнедеятельности общества, являются незаменимым
источником информации и могут плодотворно использо
ваться на всех этапах исследования: для изучения про
блемной ситуации, всестороннего анализа объекта, мак
симально полной и глубокой интерпретации полученных
результатов. )
Под документом в социологии понимают знаковую или образную информацию, зафиксированную людьми на каком-либо материальном носителе. Примеры документов: рукописный, машинописный или печатный текст, стенограмма доклада, магнитофонная запись выступления, фотографии, рисунки, кинофильмы, видеозаписи. Все чаще для фиксирования, передачи и хранения информации используются такие новые носители, как микрофильмы, микрофиши, компьютерные дискеты, лазерные диски.
Документы можно классифицировать по разным основаниям. Так, по способу фиксации информации выделяются:
1. Письменные документы (которые в свою очередь делятся на вербальные и статистические). Примером письменных вербальных документов могут служить книги, письма, пресса; примером статистических документов -данные переписи населения, данные социологических опросов, сборникц статистических материалов, содержащие показатели экономического и социального развития страны или региона и т.д.
2. Фонетические, т.е. рассчитанные на слуховое восприятие документы (грампластинки и лазерные диски, магнитофонные записи и радиопередачи).
3. Иконографические документы, воспринимаемые визуально (картины, фотографии, видеозаписи).
По статусу источника документы подразделяются на: 1. Неофициальные (личные письма, семейные альбомы, дневники, т.е. все то, что создается частными лицами по своей инициативе).
2. Официальные (документы различных организаций). Социолог, пришедший на предприятие, в учреждение, должен знать, что официальные документы включают текущую, входящую и исходящую документацию; документы периодической отчетности - месячные, квартальные, годовые справки, отчеты, ведомости; отчеты, обзоры, доклады, не являющиеся периодическими; архивные документы постоянного и временного хранения.
С точки зрения спонтанности появления документы делятся на самопроизвольные, созданные независимо от исследователя, и заданные, созданные специально по просьбе исследователя.
По степени опосредованности выделяют первичные и вторичные документы - одни созданы на основе непосредственного опыта автора, другие - на базе обобщения первичных документов.
По критерию авторства документы классифицируют на индивидуальные, созданные одним автором, и коллективные, созданные несколькими авторами, группой.
Для анализа документов могут использоваться как неформализованные (качественные), так и формализованные (качественно-количественные) методы. Качественный анализ сводится к чтению документа и интерпретации его содержания с использованием общих логических операций. Такой анализ неотделим от личности исследователя. Уровень знаний и способностей исследователя, его психологические особенности и идеологическая позиция в той или иной степени могут отражаться на характере интерпретации документа и выводах. Таким образом, качественный анализ несет в себе потенциальную возможность субъективных смещений. Именно с целью преодоления субъективизма стали разрабатываться приемы формализованного анализа документов, получившего название "контент-анализ". Важной предпосылкой его развития и распространения стала массовизация информационных процессов и связанная с этим необходимость анализа больших объемов информации. Наиболее наглядный эффект контент-анализ давал в сфере журналистики, имеющей дело с массовым производством и распространением сообщений. Естественно поэтому, что контент-анализ
первоначально использовался для исследования средств массовой информации (СМИ). Со временем метод контент-анализа стал распространяться и на изучение других областей социальной реальности, другого типа документов, в частности, невербальных, иконографических (портреты, фотографии и даже сновидения), а также "спровоцированных" (сочинения на заданную тему, психиатрические интервью, ответы на открытые вопросы социологической анкеты).
Однако надо помнить, что не все документы пригодны для контент-анализа, и не всегда его проведение имеет- смысл, а лишь в том случае, если: а) объект исследования представлен большим массивом однородных документов; б) интересующие исследователя элементы содержания встречаются в документах с достаточной частотой.
В процессе становления и развития метода качественно-количественного анализа содержания отработаны и сформулированы те принципиальные требования, которым он с необходимостью должен отвечать. Это объективность, систематичность, обобщенность.
Принцип объективности означает независимость идентификации элементов содержания и последующей их классификации от субъективного мнения аналитика. Объективность достигается при условии такого точного и однозначного определения категорий и единиц анализа, чтобы разные аналитики, приложив их к одинаковому содержанию, получили бы и одинаковый результат. Наибольшая объективность достигается при компьютерном контент-анализе (первые программы для анализа текстов на ЭВМ были разработаны в 60-е годы в Массачусетском технологическом институте под руководством Ф. Стоуна). В этом случае идентификация элементов содержания осуществляется по чисто формальным критериям. В ручном варианте иногда трудно избежать определенной субъективности в процессе выделения единиц анализа и их соотнесения с категориями. Поэтому существуют способы контроля надежности контент-аналитической методики, которые следует использовать в процессе работы над документами. Например, один и тот же документ анали-
зируется по единой инструкции разными кодировщиками. Если расхождение между данными кодировщиков не превышает 5 %, то можно считать, что методика позволяет получать устойчивые результаты, что категории и единицы анализа, а также алгоритм кодирования описаны достаточно точно и однозначно. При этом не обязательно нескольким кодировщикам анализировать все документы, достаточно взять для пробы какую-то часть выборки или повторять процедуру параллельного кодирования и сопоставления результатов в ходе анализа через определенный шаг. Однако изучаемое содержание не в одинаковой степени поддается формализации. Не всегда задачи исследования позволяют выработать такие строгие формальные предписания, руководствуясь которыми разные кодировщики выносили бы одинаковые решения (в случае, когда единицы анализа представляют собой сложные конструкции: жизненная ситуация, модель постановки и решения проблемы и т.п.). Тогда работа кодировщика из механической превращается в аналитическую. Объективность и надежность получаемых результатов в таких исследованиях обеспечивается особенно тщательным отбором и подготовкой кодировщиков, параллельным кодированием одних и тех же текстов. Кроме того, практикуется обсуждение каждого из проанализированных документов и вынесение согласованного решения в случае несовпадения мнений кодировщиков.
Второй принцип - систематичность - реализуется в том случае, если все без исключения документы, попавшие в выборку, все исследуемое содержание будет проанализировано по единой методике. Не допускается частичный анализ, произвольное исключение из поля зрения тех или иных текстов, а также их анализ лишь по некоторым выборочным категориям.
Обобщенность как принцип контент-аналитического исследования означает, что главный смысл изучения текста состоит в том, чтобы получить из него информацию о внетекстовой реальности. Есть три возможности сопоставления текста и внетекстовой реальности, три вектора движения от документа к отражаемым в нем объектам. Первый - к событиям, фактам, явлениям и условиям
реальной действительности (реконструкция событий на основе документа). Второй - к создателю, автору текста, т.е. коммуникатору (реконструкция стратегии коммуникатора, предлагаемых им ценностей, моделей поведения, коммуникативных намерений). Третий - к получателю информации, т.е. реципиенту, аудитории (реконструкция информационных потребностей, интересов и предпочтений аудитории). Корректное сопоставление текста и внетекстовой реальности требует оперирования сравнимыми данными. Поэтому в рамках конкретного исследования анализ содержания зачастую выступает в комплексе с другими социологическими методами, направленными на непосредственное изучение характеристик объективной реальности, воспроизводимой текстом.
Рассмотрим более подробно процедуру контент-анализа.
Контент-анализ - это метод качественно-количественного анализа массива документов с целью получения достоверной информации об объективной реальности. Процедура контент-анализа состоит в алгоритмизированном выделении в тексте определенных, интересующих исследователя элементов содержания, классификации выделенных элементов в соответствии с концептуальной схемой, последующем их подсчете и количественном представлении результатов. Концепция исследования сформулирована в его программе. На нее-то и ориентируется контент-аналитик, делая свой первый шаг - выстраивая систему категорий анализа - т.е. наиболее общих ключевых понятий, отражающих понятийную систему исследования в целом.
Покажем это на примере. В проекте "Влияние СМИ на различные группы молодежи" изучалась степень соответствия позиций молодежи оценочным суждениям, интерпретационным моделям, транслируемым различными СМИ РБ. В основу исследования был положен предложенный финскими социологами парадигматический подход. В рамках этого подхода под парадигмой понимают определенную интерпретационную схему явлений действительности. Парадигмы (т.е. интерпретационные схемы объективной реальности) выявлялись как в массовом
сознании, так и в массовой информации. В соответствии с теоретическими посылками, парадигму образуют такие элементы: представление ситуации как проблемной, т.е. содержащей противоречие, оценка напряженности, видение причин, путей решения, виновников проблемной ситуации. Все элементы парадигмы, которые в ней теоретически вычленяются, использованы в данном исследовании для контент-анализа в качестве категорий.
Следующий шаг после определения основных ключевых понятий или категорий анализа - их структурирование. Эта операция предполагает деление общего понятия на более частные понятия (подкатегории) в соответствии с выбранными классификационными признаками. Важно, чтобы при разработке системы подкатегорий контент-аналитик соблюдал правила деления объема понятий: а) одно и то же деление понятия должно осуществляться по одному и тому же основанию; б) объем членов деления, вместе взятых, должен равняться объему делимого понятия; в) члены деления должны взаимно исключать друг друга. Допустим, категория "главный герой" может подразделяться с точки зрения такого признака, как социально-профессиональная принадлежность на героя-рабочего, служащего, студента и т.д. Если же в характеристике героя важно зафиксировать его возраст, пол или политические убеждения, категориальная сетка будет иной, т.к. иными являются основания классификации. Важно только, чтобы совокупность подкатегорий исчерпывающе раскрывала категорию по выбранному основанию. Итак, категории анализа жестко заданы проблемой исследования, его концепцией, тогда как подкатегории, как правило, вариативны, гибко приспособлены к тому материалу, который предстоит анализировать, и к тем задачам, которые предстоит решить. Так, например, одна из традиционных категорий, используемых при анализе СМИ - "тема" - зачастую содержит самые различные подкатегории в разных исследованиях. Это обусловлено тем, что тематика разных изданий сильно варьируется, но в не меньшей степени и тем, что аналитик может стремиться к разной степени подробности в описании тематической структуры. Аналогично и категория "география
описываемых событий" классифицируется существенно по-разному, если объектом изучения является республиканская или местная печать. А такая категория, как "оценка", наоборот, всегда структурируется одинаково: положительная, отрицательная, сбалансированная, нейтральная оценка.
Далее необходимо полученную схему, состоящую из категорий и подкатегорий, "наложить" на конкретный текст, или, иными словами, найти для всех категорий и подкатегорий адекватное выражение на языке исследуемых документов. Таким их выражением являются единицы анализа. Если сопоставить категории (подкатегории) и единицы анализа, то можно сказать, что последние яЁР ляются результатом операционализации первых. Например, категория "география сообщений по РБ" операцио-нализирована так: "слова, обозначающие названия городов и других населенных пунктов РБ" и соотносимых с ними регионов, типа "Витебская область", "Борисовский район".
В практике сложился целый ряд устойчивых стандартных единиц контент-анализа. К их числу относятся следующие:
- отдельное слово. Известно исследование, проведенное американскими учеными Г. Лассуэллом, Н. Лей-тесом и др. в конце 40-х годов. Его целью было изучить политическую и идеологическую информацию в газетах различных стран мира. В качестве единицы анализа использовались слова-символы: имена политических деятелей и институтов, названия стран, слова, обозначающие политические акты и состояния (война, революция), названия идеологий (коммунизм, либерализм).
- суждение, законченная мысль, логическая цепь, в которой обнаруживается центральная идея. Примеры подобных смысловых единиц анализа: описание брака или любви между двумя конкретными людьми, истории их взаимоотношений и всех сопутствующих обстоятельств; экологическая проблемная ситуация - часть текста, содержащая информацию об определенном аспекте отношений человека со средой, оценке этих отношений и о связанных с ним объяснениях.
- персонаж ("герой") сообщения используется при изучении пропаганды профессий, интерпретации особенностей того или иного национального характера в СМИ, в других контент-аналитических исследованиях, когда необходимо определить, какие качества приписываются личности (группе) в интересующих аналитика документах.
Из приведенного описания очевидно, что фрагменты текста, соответствующие различным единицам анализа, могут колебаться от минимального размера (слово) до максимального (логическая цепь, жизненная ситуация), которые фиксируются в пределах целого сообщения или даже нескольких сообщений. Единицы анализа с наибольшей точностью идентифицируются на фоне более широких содержательных структур, которые иногда называют единицами контекста. Для слова и предложения контекстом будет абзац, для жизненной ситуации или проблемной ситуации - целое сообщение.
Обнаружение единиц анализа в тексте документа сопровождается процедурой их измерения с целью определить объем внимания или частоту обращения к тем или иным проблемам, символам, темам, героям. При выявлении объема внимания вычисляется количество строк, минут эфирного времени или размер газетной, журнальной площади, посвященной интересующей нас единице анализа. Прежде чем приступать к измерениям, необходимо решить, будет ли входить заголовок в объем сообщения, какой единый стандарт избрать для измерения материалов, набранных разными шрифтами и т.д. В случае, если необходимо определить частоту обращения, подсчитыва-ется количество упоминаний соответствующего символа, общее число упоминаний слов, предложений, суждений или количество абзацев, других фрагментов текста, содержащих данную единицу. Если единицей анализа выступает признак, характеризующий сообщение в целом, фиксируется просто его наличие в тексте и подсчитыва-ется количество материалов, содержащих этот признак. Таким признаком может быть, например, авторство материала: подытоживается количество сообщений, авторы которых профессиональные журналисты, политики, ученые, специалисты и т.д.
Приступая к контент-анализу, социолог должен иметь следующие документы: таблицу контент-анализа, инструкцию кодировщика, кодированную карточку. Таблица контент-анализа содержит список категорий и подкатегорий и присвоенные им коды. Инструкция кодировщика содержит описание единицы анализа и счета, в ней изложены правила кодирования, проиллюстрированные соответствующими примерами, оговариваются возможные затруднения и спорные моменты. Осваивая инструкцию, кодировщик (т.е. тот, кто выполняет работу по сбору эмпирической информации, фиксируя, классифицируя и подсчитывая единицы анализа) овладевает алгоритмом действий, что в конечном счете и обеспечивает реализацию принципа объективности, когда различные аналитики, приложив методику к одному и тому же содержанию, получают один и тот же результат. Регистрация единиц анализа производится в специальных таблицах, кодиро-вочньгх матрицах или карточках. Кодировочная карточка, например, включает все классификационные единицы-категории и подкатегории. Единицы анализа, обнаруженные в документе, по ходу работы фиксируются в соответствующих графах копировочной карточки (Рис. 8).
| Номер документа № | Категории и подкатегории анализа | |||||||||||||||
| тема (код) | знак информации (код) | география сообщений (код) | автор сообщения (код) | |||||||||||||
| ... | п | ... | п | ... | о | ... | п | |||||||||
| п | ||||||||||||||||
| Еn |
Рис. 8. Образец кодировочной карточки.
Для количественного описания результатов анализа содержания используются те же средства и приемы, что и в любых других социологических исследованиях: процентное распределение, индексы, парные корреляции, различные виды многомерного статистического анализа. Существуют и специальные коэффициенты для анализа документов. Таков коэффициент Яниса, который предна-
значен для вычисления баланса положительных и отрицательных оценочных суждений относительно избранного объекта высказывания. Если число положительных оценок превышает число отрицательных, коэффициент вычисляется по формуле:
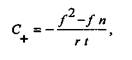
где f- число положительных оценок, п - число отрицательных оценок, r - объем содержания текста, имеющего прямое отношение к изучаемой проблеме, t - общий объем текста. Если число положительных оценок меньше, чем отрицательных, коэффициент находится по формуле:
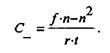
Полезна при анализе текста формула для измерения удельного веса категорий содержания, предложенная А.Н. Алексеевым:
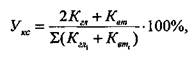
где Укс - удельный вес данной категории содержания; Кгп - количество случаев, когда данная категория (единица) оказалась главной; Квт - количество случаев, когда данная категория (единица) оказалась второстепенной; Е - сумма анализируемых документов.
Удельный вес категории содержания можно вычислить и более просто: Укс = отношению числа единиц анализа, фиксирующих данную категорию к общему числу единиц анализа.
В контент-анализе предполагается своя выборка Массив вербальных, фонетических или иконографических документов, объединенных общим признаком (источник,
автор, тема и т.п.), представляет генеральную совокупность, подлежащую изучению. Границы генеральной совокупности задаются достаточно произвольно: исходя из целей исследования и с учетом естественных временных циклов (год, квартал, месяц) и периодичности изданий (если речь идет об анализе содержания СМИ). Например, в исследовании динамики освещения в прессе РБ проблем, связанных с аварией на Чернобыльской АЭС, генеральной совокупностью документов были все газеты, изданные в республике с конца апреля 1986 года (т.е. с момента аварии). Если стоит задача провести контент-анализ кампании по выборам президента, то в границы генеральной совокупности будут включены все документы, опубликованные в связи с выборами с момента начала кампании до момента ее завершения.
При формировании выборочной совокупности документов из трех возможных стратегий: сплошного, случайного, направленного отбора - используются только две первые. Направленный тип отбора исключается, т.к. отсутствуют данные о распределении признаков в генеральной совокупности документов. Чаще всего в контент-анализе используется многоступенчатый отбор. На первой ступени отбираются источники. В том случае, если источников много, они предварительно группируются, и отбор.производится из каждой группы. На второй ступени отбираются собственно тексты документов - протоколы собраний, инструкции, листовки, письма, фильмы, передачи, материалы газет внутри каждого из выделенных на первой ступени источника. Отбор газет представляет собой разновидность гнездовой выборки (гнездо -номер газеты). Выделение гнезд - номеров газеты - методом систематического отбора нежелательно, т.к., учитывая периодичность выхода газет, можно получить смещенную выборку, в которую попадут только, например, номера за понедельник, или за вторник, или за пятницу, в то время как номера за другие дни недели вообще выпадут из поля зрения. У практиков контент-анализа существует метод "конструирования недели", позволяющий избежать такого смещения. Он предполагает предварительное районирование генеральной совокупности. В го-
довой подшивке выделяют выпуски за понедельник, втор-,ник и т.д. А затем из каждой группы чисто случайно отбирается нужное количество номеров.
Но как определить объем выборки в контент-аналитическом исследовании? Целесообразно осуществлять формирование выборочной совокупности по принципу наполнения. В соответствии с этим принципом выбор единиц наблюдения прекращается тогда, когда ошибка выборки удовлетворяет исследователя. Для этого необходимо процесс отбора контролировать, периодически замеряя ошибку. Ссылаясь на опыт, Н.Н. Чурилов, описавший этот метод, отмечает, что предельная теоретическая ошибка выборки стремительно уменьшается при анализе первых 10-15 газет. Если же и дальше продолжать увеличивать число единиц наблюдения, то ошибка уменьшается незначительно. Порогом насыщения является совокупность в 30-35 газет. На практике для анализа большого массива документов чаще всего используется выборка в 200-600 отдельных текстов для одного источника (это соответствует количеству материалов в 30-35 газетах).

