 2015-05-10
2015-05-10 1759
1759Главными целями факторного анализа являются сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификация переменных. Поэтому факторный анализ используется или как метод сокращения данных, или как метод классификации переменных.
Сокращение достигается путем выделения скрытых общих факторов, объясняющих связи между наблюдаемыми факторами (переменными) объекта, т.е. вместо исходного набора переменных появится возможность анализировать данные по выделенным факторам, число которых значительно меньше исходного числа взаимосвязанных переменных.
Факторный анализ производится при помощи модуля «Statistics/Multivariate Exploratory/ Factor Analysis».
В диалоговом окне этого модуля (рис.5.14) при помощи кнопки «Variables» указываются переменные для анализа (ID_BIRTH, ID_EDUCATION, ID_POVERTY, ID_UNEMPLAYMENT, ID_VVP, ID_DEVELOPMENT). Теперь можно начать анализ по выявлению главных факторов, влияющих на качество жизни населения.
В поле «Input file» указывается тип файла с данными:
1. Raw Date - данные в виде строчной таблицы.
2. Correlation Matrix - данные в виде корреляционной матрицы.
Рисунок 5.14. Диалоговое окно «Factor Analysis»
В поле «MD deletion» указывается способ исключения из обработки недостающих данных:
1. Casewise - игнорируется вся строка, в которой есть хотя бы одной пропущенное значение/
2. Mean substitution - взамен пропущенных данных подставляются средние значения переменных.
3. Pairwise - попарное исключение данных с пропусками из тех переменных, корреляция которых вычисляется.
ППП Statistica обработает пропущенные значения тем способом, какой указан, вычислит корреляционную матрицу и предложит на выбор несколько методов факторного анализа.
Вычисление корреляционной матрицы (если она не задается сразу) – первый этап факторного анализа.
После щелчка по кнопе «OK» можно перейти к следующему диалоговому окну – «Define Method of Factor Extraction» (Определить метод выделения факторов) (рис.5.15).
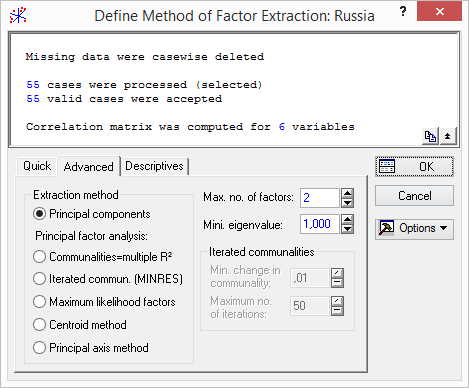
Рисунок 5.15. Диалоговое окно «Define Method of Factor Extraction»
Данное окно имеет структуру, описанную ниже.
Верхняя часть окна является информационной: здесь сообщается, что пропущенные значения обработаны методом «Casewise». Обработано 55 случаев и 55 случаев приняты для дальнейших вычислений. Корреляционная матрица вычислена для 6 переменных.
Группа опций, объединенных под заголовком «Extraction method» (Методы выделения факторов) – позволяет выбрать метод обработки:
1. «Principal components» (метод главных компонент) – позволяет выделить компоненты, работая с первоначальной матрицей корреляций.
2. «Communalities=multiple 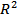 » (общности как множественный ) – на диагонали матрицы корреляций будут находиться оценки квадрата коэффициента множественной корреляции- (соответствующей переменной со всеми другими переменными).
» (общности как множественный ) – на диагонали матрицы корреляций будут находиться оценки квадрата коэффициента множественной корреляции- (соответствующей переменной со всеми другими переменными).
3. «Iterated communalities (MINRES)» (метод минимальных остатков) – выполняется в два этапа. Сначала оценки квадрата коэффициента множественной корреляции- используются для определения общностей, как в предыдущем методе. После первоначального выделения факторов метод корректирует их нагрузки с помощью метода наименьших квадратов с целью минимизировать остаточные суммы квадратов.
4. «Maximum likelihood factors» (метод максимального правдоподобия) – в этом методе считается заранее известным число факторов (оно устанавливается в поле ввода максимального числа факторов). ППП Statistica оценит нагрузки и общности, которые максимизируют вероятность наблюдаемой в таком случае матрицы корреляций. В диалоговом окне результатов анализа доступен 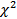 тест для проверки справедливости принятой гипотезы о числе общих факторов.
тест для проверки справедливости принятой гипотезы о числе общих факторов.
5. «Centroid method2 (центроидный метод) – основан на геометрическом подходе.
6. «Principal axis method» (метод главных осей) – основан на итеративной процедуре вычисления общностей по текущим собственным значениям и собственным векторам. Итерации продолжаются до тех пор, пока не превышено максимальное число итераций или минимальное изменение в общностях больше, чем это определено в соответствующем поле (см. ниже).
«Max. no. of factors» (Максимальное число факторов). Заданное в этом поле число определяет, сколько факторов может быть выделено при работе рассмотренных выше методов. Это поле работает вместе с полем «Min. Eigenvalue» (Минимальное собственное значение). Часто при заполнении этого поля руководствуются критерием Кайзера, который рекомендует использовать лишь те факторы, для которых собственные значения не меньше 1 или Критерий каменистой осыпи (Scree-test). Процедура выбора числа факторов описана в п.5.4.1.
Остальные поля доступны только при выбранном методе «Centroid method» (Центроидный метод) или «Principal axis method» (Метод главных осей), и определяют необходимые для успешного выполнения последовательных итераций параметры минимального изменения в общностях и максимального числа итераций.
В окне «Define Method of Factor Extraction» (Определить метод выделения факторов) по кнопке «Review correlations, means, standart deviations» (Просмотреть корреляции /средние/стандартные отклонения) на вкладке «Descriptives» можно посмотреть средние, стандартные отклонения, корреляции, ковариации, построить различные графики.
Рисунок 5.16. Диалоговое окно «Review Descriptive Statistics»
По кнопке «Correlations» (Корреляции) (рис.5.16). отображается на экране корреляционная матрица выбранных ранее переменных.
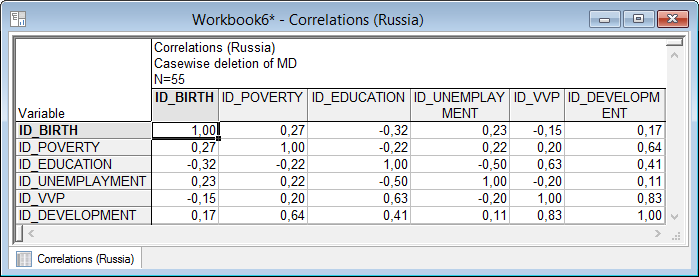
Рисунок 5.17. Корреляционная матрица
В окне «Define Method of Factor Extraction» (Определить метод выделения факторов) на вкладке «Advanced» по кнопке «OK» можно просмотреть результаты факторного анализа выбранного метода
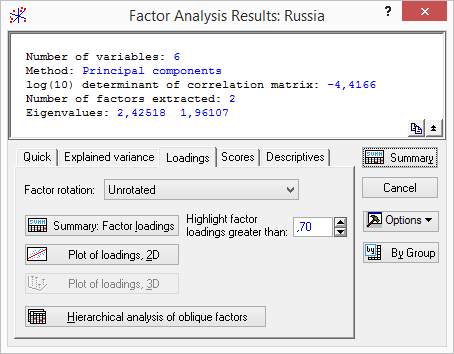
Рисунок 5.18. Диалоговое окно «Factor Analysis Results»
В верхней части окна «Factor Analysis Results» дается информационное сообщение:
1. «Number of variables» – Число анализируемых переменных 6;
2. «Method» – Метод анализа: Основные (главные) компоненты;
3. «log(10) determination of correlation matrix» – Десятичный логарифм детерминанта корреляционной матрицы: -4,4166;
4. «Number of factor extraction» – Число выделенных факторов: 2;
5. «Eigenvalues» – Собственные значения: 2,42518 и 1,96107.
В нижней части окна находятся подразделы, позволяющие всесторонне просмотреть результаты анализа численно и графически.
Опция «Factor rotation» – помогает выбрать различные повороты осей, т.е. вращать факторы. Если пространство общих факторов найдено, то с помощью поворота системы координат в принципе можно получить бесчисленное множество решений. Но такое количество решений неразумно, поэтому важно найти интерпретируемое решение.
Возможны следующие методы поворотов:
1. Варимакс – Varimax.
2. Биквартимакс – Biquartimax.
3. Квартимакс – Quartimax.
4. Эквимакс – Equamax.
Дополнительный термин в названии: нормализованные («normalized») – указывает на то, что факторные нагрузки в процедуре нормализуются, т.е. делятся на корень квадратный из соответствующей общности; и необработанные (« raw» ) – исходные тип данных, который показывает, что вращаемые нагрузки не нормализованы.
Например, если оставить факторные нагрузки неизменные, т.е. не поворачивать, выбрав опцию «Factor rotation» - «Unrotated» и нажав на кнопку «Plot of Loadings 2D» (Двумерный график нагрузок), и можно посмотреть результаты факторного анализа на графике.
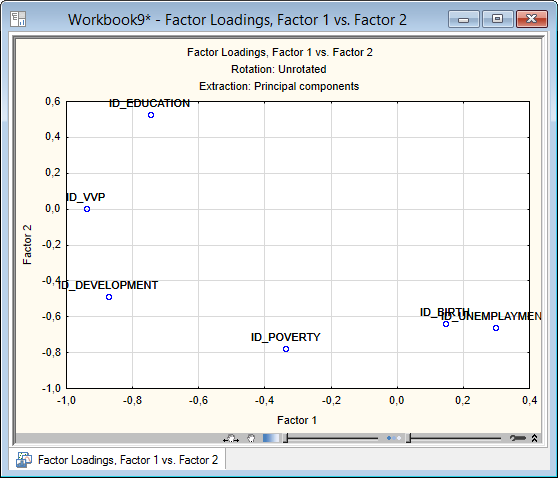
Рисунок 5.19. Факторное решение без поворота
Щелкнув на кнопку «Summary»можно просмотреть нагрузки численно.
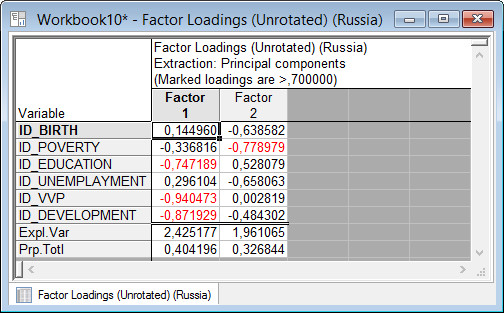
Рисунок 5.20. Таблица факторных нагрузок
Рассматривая графическое решение, трудно сделать интерпретацию, не понятно, какой смысл придать двум выделенным факторам и как в этих терминах описывать показатели качества жизни.
В так случаях следует использовать поворот осей, надеясь получить решение, которое можно интерпретировать в предметной области.
Если поле «Factor rotation» выбрать «Varimax normalized », система произведет вращение факторов методом нормализованного варимакса. По кнопкк «Plot of Loadings 2D » – Двумерный график нагрузок ), на экране появится двумерный график нагрузок:
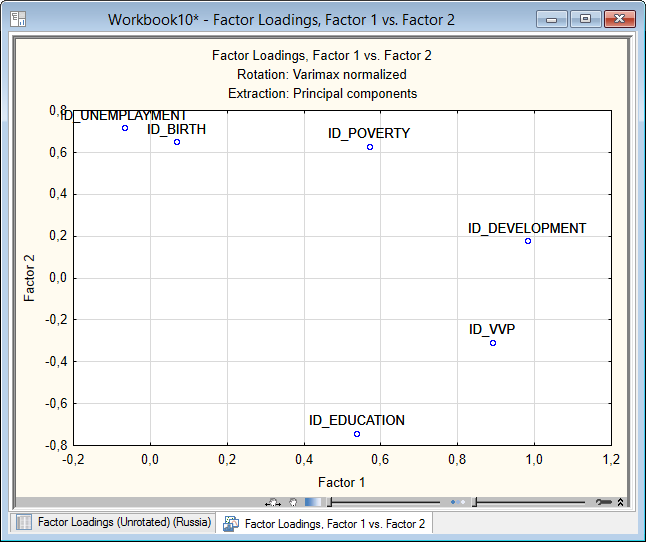
Рисунок 5.21. Факторное решение после поворота осей
По кнопке «Summary» можно посмотреть нагрузки численно.
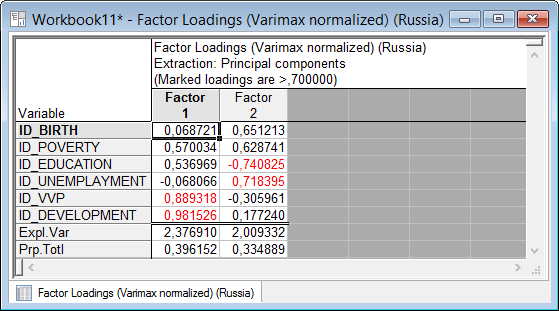
Рисунок 5.22. Таблица факторных нагрузок после поворота осей
Теперь полученное решение можно интерпретировать. Система выделила два общих фактора «Factor 1» и «Factor 2». «Factor 1» отвечает за уровень образования (ID_EDUCATION – индекс уровня образования), а «Factor 2» – за уровень жизни со следующими показателями: ID_UNEMPLAYMENT – индекс уровня безработицы и ID_BIRTH – индекс ожидаемой продолжительности при рождении.
Глядя на полученные результаты, можно сделать вывод, что уровень качества жизни населения определяется двумя факторами: уровнем образования в стране и социальными показателями такими, как безработица и продолжительность жизни населения.
Для того что бы посмотреть полученный результат, используя другие характеристики факторного анализа, необходимо:
1. В диалоговом окне «Factor Analysis Results» на вкладке «Explained variance» (Объяснимая дисперсия) по кнопке «Eigenvalues» (Собственные значения) отобразиться таблица, представленная на рис.5.23.
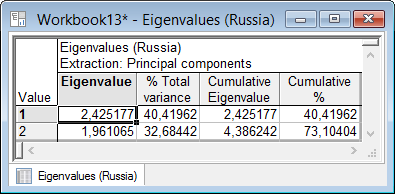
Рисунок 5.23. Таблица собственных значений
В первом столбце таблицы даны собственные значения, во втором – процент общей дисперсии, соответствующий этим собственным значениям, далее кумулятивные или накопленные собственные значения (собственные значения суммируются – накапливаются) и кумулятивный процент дисперсии.
2. В диалоговом окне «Factor Analysis Results» на вкладке «Explained variance» (Объяснимая дисперсия) по кнопке «Communalities» (Общности) отобразиться таблица, представленная на рис.5.24.
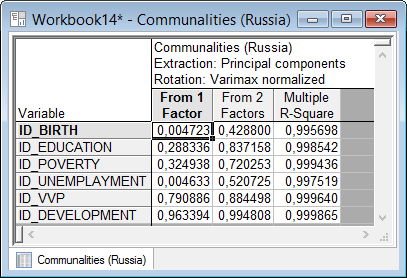
Рисунок 5.24. Таблица общностей
Данная таблица представляет стандартный вывод факторного анализа. В первом столбце таблицы представлены общности для решения, состоящего из одного главного фактора (однофакторное решение), во втором – решение, состоящее из двух факторов (двухфакторное решение).
3. В диалоговом окне «Factor Analysis Results» на вкладке «Explained variance» (Объяснимая дисперсия) по кнопке «Reproduced/residual corrs» (Воспроизведенные/остаточные корреляции) отобразиться таблицы, представленная на рис.. В первой таблице можно увидеть воспроизведенную корреляционную матрицу, а затем остаточную корреляционную матрицу, получаемую поэлементным вычитанием воспроизведенной матрицы из исходной корреляционной матрицы.
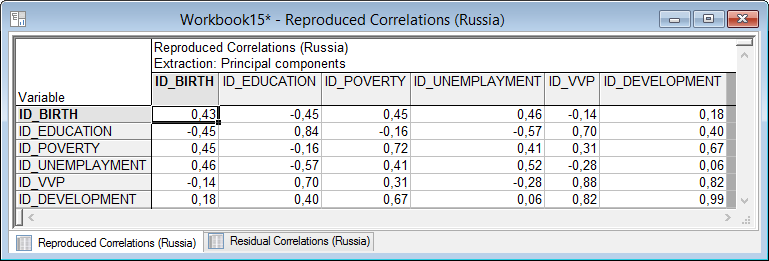
Рисунок 5.25. Воспроизведенная корреляционная матрица
 Примечание Примечание |
| Часто на главной диагонали корреляционной матрицы вместо единиц ставятся квадраты коэффициентов множественной корреляции или другие оценки общностей. |
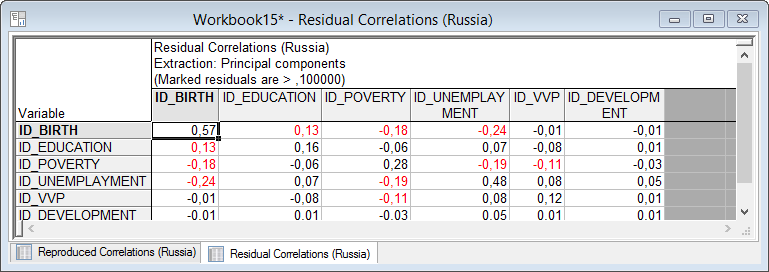
Рисунок 5.26. Остаточная корреляционная матрица
Метод факторного анализа – неэлементарный метод обработки статистических данных. При его применении следует рассмотреть различные варианты решений, а математический ППП Statistica позволяет эффективно это сделать.

