 2015-05-10
2015-05-10 1541
1541Понятия корреляции и регрессии непосредственно связаны между собой. В корреляционном и регрессионном анализе много общих вычислительных приемов. Они используются для выявления причинно-следственных соотношений между явлениями и процессами. Однако если корреляционный анализ позволяет оценить силу и направление стохастической связи, то регрессионный анализ - еще и функцию зависимости. При этом следует отметить, что чем слабее взаимосвязь, тем больше диаграмма рассеяния похожа на облако (рис. 3) и тем труднее определить функцию зависимости.
Регрессия может быть:
а) в зависимости от числа явлений (переменных):
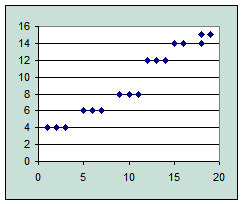
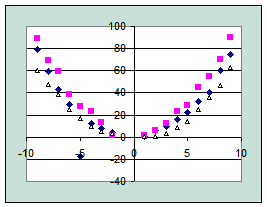
Рис. 4. Линейная зависимость Рис. 5. Нелинейная зависимость
- простой (регрессия между двумя переменными, рис. 4, 5);
- множественной (регрессия между зависимой переменной (y) и несколькими объясняющими ее переменными (х1, х2...хn);
б) в зависимости от формы (см. рис. 9, 10):
- линейной (отображается линейной функцией, а между изучаемыми переменными существуют линейные соотношения);
- нелинейной (отображается нелинейной функцией, между изучаемыми переменными связь носит нелинейный характер);
в) по характеру связи между включенными в рассмотрение переменными:
- положительной (увеличение значения объясняющей переменной приводит к увеличению значения зависимой переменной и наоборот);
- отрицательной (с увеличением значения объясняющей переменной значение объясняемой переменной уменьшается);
г) по типу:
- непосредственной (в этом случае причина оказывает прямое воздействие на следствие, т.е. зависимая и объясняющая переменные связаны непосредственно друг с другом);
- косвенной (объясняющая переменная оказывает опосредованное действие через третью или ряд других переменных на зависимую переменную);
- ложной (нонсенс-регрессия) - может возникнуть при поверхностном и формальном подходе к исследуемым процессам и явлениям. Например, регрессия, устанавливающая связь между уменьшением количества потребляемого алкоголя в нашей стране и уменьшением продажи стирального порошка.
При проведении регрессионного анализа решаются следующие основные задачи:
1. Определение формы зависимости.
2. Определение функции регрессии. Для этого используют математическое уравнение того или иного типа, позволяющее, во-первых, установить общую тенденцию изменения зависимой переменной, а, во-вторых, вычислить влияние объясняющей переменной (или нескольких переменных) на зависимую переменную.
3. Оценка неизвестных значений зависимой переменной. Полученная математическая зависимость (уравнение регрессии) позволяет определять значение зависимой переменной как в пределах интервала заданных значений объясняющих переменных, так и за его пределами. В последнем случае регрессионный анализ выступает в качестве полезного инструмента при прогнозировании изменений социально-экономических процессов и явлений (при условии сохранения существующих тенденций и взаимосвязей). Обычно длина временного отрезка, на который осуществляется прогнозирование, выбирается не более половины интервала времени, на котором проведены наблюдения исходных показателей. Можно осуществить как пассивный прогноз, решая задачу экстраполяции, так и активный, ведя рассуждения по известной схеме «если..., то» и подставляя различные значения в одну или несколько объясняющих переменных регрессии.
Технология построения регрессии
Для построения регрессии используется метод, получивший название метода наименьших квадратов. Суть его заключается в нахождении по фактическим данным динамического ряда теоретической кривой (тренд), точки которой равноудалены от кривой 1 (см. рис. 6).
При выборе модели регрессии одним из существенных требований к ней является возможность обеспечения наибольшей простоты, позволяющей получить решение с достаточной точностью. Поэтому для установления статистических связей вначале, как правило, рассматривают модель из класса линейных функций, затем другие.
Существует хорошо развитая система подбора аппроксимирующих функций - методика группового учета аргументов (МГУА), достаточно удачно реализованная в программе Excel.
О правильности подобранной модели можно судить по результатам исследования остатков 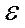 i, являющихся разностями между наблюдаемыми величинами
i, являющихся разностями между наблюдаемыми величинами  yi и соответствующими прогнозируемыми с помощью регрессионного уравнения величинами yi . В этом случае для проверки адекватности модели рассчитывается средняя ошибка аппроксимации:
yi и соответствующими прогнозируемыми с помощью регрессионного уравнения величинами yi . В этом случае для проверки адекватности модели рассчитывается средняя ошибка аппроксимации:
 1 yi - yi
1 yi - yi

 = n
= n 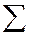 yi
yi
Модель считается адекватной, если , находится в пределах не более 15%.

