 2015-05-13
2015-05-13 4032
4032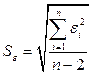 .
.
Анализ статистической значимости параметров модели парной регрессии 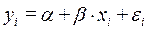
Значения 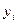 , соответствующие данным
, соответствующие данным 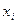 при теоретических значениях
при теоретических значениях 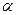 и
и 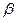 являются случайными. Случайными являются и рассчитанные по ним значения коэффициентов и .
являются случайными. Случайными являются и рассчитанные по ним значения коэффициентов и .
Надежность получаемых оценок и зависит от дисперсии случайных отклонений (ошибок). По данным выборки эти отклонения и, соответственно, их дисперсия не оцениваются – в расчетах используются отклонения зависимой переменной 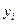 от ее расчетных значений
от ее расчетных значений 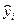 :
: 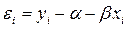 . Так как ошибки (остатки)
. Так как ошибки (остатки) 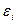 нормально распределены, то среднеквадратическое отклонение ошибок используется для измерения этой вариации. Среднеквадратические отклонения коэффициентов известны как стандартные ошибки (отклонения):
нормально распределены, то среднеквадратическое отклонение ошибок используется для измерения этой вариации. Среднеквадратические отклонения коэффициентов известны как стандартные ошибки (отклонения):
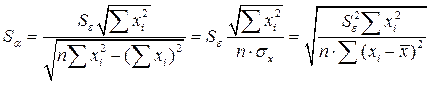
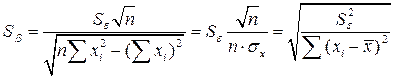 ,
,
где 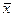 - среднее значение независимой переменной х;
- среднее значение независимой переменной х; 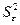 стандартная ошибка, вычисляемая по формуле
стандартная ошибка, вычисляемая по формуле 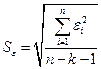 ;
; 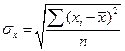 .
.
Проверка значимости отдельных коэффициентов регрессии связана с определением расчетных значений t-критерия (t–статистики) для соответствующих коэффициентов регрессии:
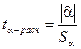 ;
; 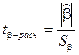 .
.
Затем расчетные значения 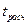 сравниваются с табличными tтабл. Табличное значение критерия определяется при (n- 2) степенях свободы (n - число наблюдений) и соответствующем уровне значимости a (0,1; 0,05)
сравниваются с табличными tтабл. Табличное значение критерия определяется при (n- 2) степенях свободы (n - число наблюдений) и соответствующем уровне значимости a (0,1; 0,05)
Если расчетное значение t-критерия с 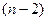 степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели (при этом ее качество не ухудшится).
Интервальная оценка параметров модели
Для значимого уравнения регрессии представляет интерес построение интервальных оценок для параметра 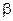 :
:
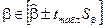 ,
,
свободного члена 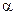 :
:
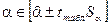 ,
,
где t табл определяется по таблице распределения Стьюдента для уровня значимости a и числа степеней свободы k = n - 2; 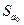 ,
, 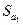 – стандартные отклонения, соответственно, свободного члена и коэффициента модели; n – число наблюдений.
– стандартные отклонения, соответственно, свободного члена и коэффициента модели; n – число наблюдений.
Прогнозирование с применением уравнения регрессии. Регрессионные модели могут быть использованы для прогнозирования возможных ожидаемых значений зависимой переменной.
Прогнозируемое значение переменной 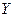 получается при подстановке в уравнение регрессии ожидаемой величины фактора
получается при подстановке в уравнение регрессии ожидаемой величины фактора 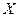 :
:
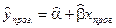 .
.
Данный прогноз называется точечным. Значение независимой переменной 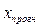 не должно значительно отличаться от входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
не должно значительно отличаться от входящих в исследуемую выборку, по которой вычислено уравнение регрессии.
Вероятность реализации точечного прогноза теоретически равна нулю. Поэтому рассчитывается средняя ошибка прогноза или доверительный интервал прогноза с достаточно большой надежностью.
доверительные интервалы зависят от следующих параметров:
· от стандартной ошибки;
· удаления от своего среднего значения ;
· количества наблюдений n;
· уровня значимости прогноза α.
В частности, для прогноза будущие значения 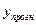 с вероятностью (1 - α) попадут в интервал
с вероятностью (1 - α) попадут в интервал
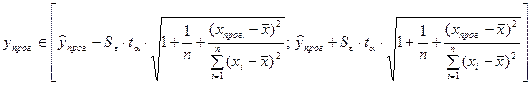 .
.
Расположение границ доверительного интервала показывает, что прогноз значений зависимой переменной по уравнению регрессии хорош только в том случае, если значение фактора не выходит за пределы выборки. Иными словами, экстраполяция по уравнению регрессии может привести к значительным погрешностям.
Пример.
Используя данные предыдущего примера, оценить накопления семьи, имеющей доход 42 тыс. $ и отобразить на графике исходные данные, результаты моделирования и прогнозирования.
Решение.
В предыдущем примере была построена модель зависимости накопления от дохода:
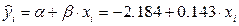 .
.
Для того, чтобы определить накопления семьи при доходе 42 тыс.$ необходимо подставить значение хпрогн в полученную модель.
yпрогноз = - 2.184+0.143*42= 3.827
Величину отклонения от линии регрессии вычисляют по формуле 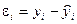 , используя данные таблицы 20. Величину
, используя данные таблицы 20. Величину 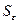 находят по формуле
находят по формуле
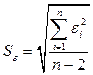 =
= 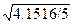 = 0.9112
= 0.9112
Таблица 21
Таблица остатков
| Наблюдение | Накопления | Предсказанное Y | Остатки | e2 |
| Y | 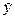 | e | ||
| 3.541 | -0.5406 | 0.2923 | ||
| 5.688 | 0.3125 | 0.0977 | ||
| 4.256 | 0.7438 | 0.5532 | ||
| 3.5 | 2.109 | 1.3906 | 1.9338 | |
| 1.5 | 2.109 | -0.6094 | 0.3713 | |
| 4.5 | 4.972 | -0.4719 | 0.2227 | |
| 2.825 | -0.8250 | 0.6806 | ||
| Сумма | 25.5 | 25.500 | 0.0000 | 4.1516 |
Коэффициент Стьюдента 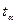
 для m=5 степеней свободы (m=n-2) и уровня значимости 0.1 равен 2.015. Тогда
для m=5 степеней свободы (m=n-2) и уровня значимости 0.1 равен 2.015. Тогда
U(x=42,n=7,a=0.1) = 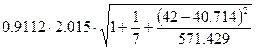 =
=
= 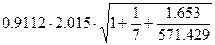 =
= 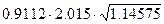 =1.965
=1.965
Таким образом, прогнозное значение 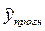 =3,827 будет находиться между верхней границей, равной 3.827+1,965=5,792 и нижней границей, равной 3,827-1,965=1,862.
=3,827 будет находиться между верхней границей, равной 3.827+1,965=5,792 и нижней границей, равной 3,827-1,965=1,862.
График исходных данных и результаты моделирования приведены на рисунке 5
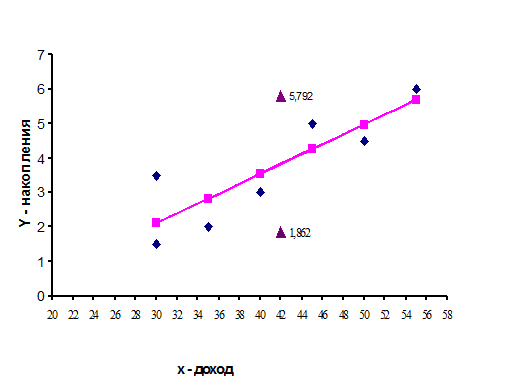
Рис.5. График модели парной регрессии зависимости накопления от дохода.
Линейная модель множественной регрессии имеет вид:
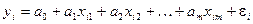
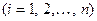
коэффициент регрессии 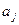 показывает, на какую величину в среднем изменится результативный признак , если переменную
показывает, на какую величину в среднем изменится результативный признак , если переменную 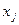 увеличить на единицу измерения, т. е. является нормативным коэффициентом. Обычно предполагается, что случайная величина
увеличить на единицу измерения, т. е. является нормативным коэффициентом. Обычно предполагается, что случайная величина 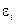 имеет нормальный закон распределения с математическим ожиданием равным нулю и с дисперсией
имеет нормальный закон распределения с математическим ожиданием равным нулю и с дисперсией 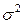 .
.
Анализ данного уравнения и методика определения параметров становятся более наглядными, а расчетные процедуры существенно упрощаются, если воспользоваться матричной формой записи уравнения:
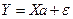 ,
,
где – это вектор зависимой переменной размерности п ´ 1, представляющий собой п наблюдений значений 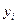 ; - матрица п наблюдений независимых переменных
; - матрица п наблюдений независимых переменных 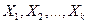 , размерность матрицы равна п ´ (k+1). Дополнительный фактор
, размерность матрицы равна п ´ (k+1). Дополнительный фактор 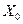 , состоящий из единиц, вводится для вычисления свободного члена. В качестве исходных данных могут быть временные ряды или пространственная выборка;
, состоящий из единиц, вводится для вычисления свободного члена. В качестве исходных данных могут быть временные ряды или пространственная выборка; 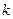 - количество факторов, включенных в модель; a — подлежащий оцениванию вектор неизвестных параметров размерности (k+1) ´ 1; параметр
- количество факторов, включенных в модель; a — подлежащий оцениванию вектор неизвестных параметров размерности (k+1) ´ 1; параметр 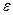 — вектор случайных отклонений (возмущений) размерности п ´ 1. отражает тот факт, что изменение будет неточно описываться изменением объясняющих переменных , так как существуют и другие факторы, неучтенные в данной модели.
— вектор случайных отклонений (возмущений) размерности п ´ 1. отражает тот факт, что изменение будет неточно описываться изменением объясняющих переменных , так как существуют и другие факторы, неучтенные в данной модели.
Таким образом,
Y = 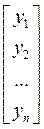 , X =
, X = 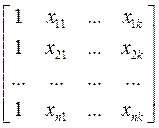 ,
, 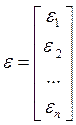 ,
, 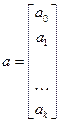
Данное уравнение содержит значения неизвестных параметров 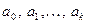 . Эти величины оцениваются на основе выборочных наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки. Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид
. Эти величины оцениваются на основе выборочных наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки. Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид
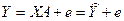 ,
,
где 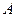 – вектор оценок параметров;
– вектор оценок параметров; 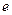 – вектор «оцененных» отклонений регрессии, остатки регрессии
– вектор «оцененных» отклонений регрессии, остатки регрессии 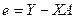 ;
; 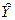 – оценка значений , равная
– оценка значений , равная 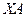 .
.
Согласно методу наименьших квадратов, вектор- столбец оценок коэффициентов регрессии вычисляется по формуле
Формулу для вычисления параметров регрессионного уравнения приведем без вывода
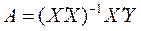 ,
,
где 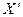 – транспонированная матрица;
– транспонированная матрица; 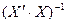 – обратная матрица.
– обратная матрица.
Одним из условий регрессионной модели является предположение о линейной независимости объясняющих переменных, т. е., решение задачи возможно лишь тогда, когда столбцы и строки матрицы исходных данных линейно независимы. Для экономических показателей это условие выполняется не всегда. Линейная или близкая к ней связь между факторами называется мультиколлинеарностью и приводит к линейной зависимости уравнений, что делает вычисление параметров либо невозможным, либо затрудняет содержательную интерпретацию параметров модели. Мультиколлинеарность может возникать в силу разных причин. Например, несколько независимых переменных могут иметь общий временной тренд, относительно которого они совершают малые колебания. В частности, так может случиться, когда значения одной независимой переменной являются лагированными значениями другой. Считают явление мультиколлинеарности в исходных данных установленным, если коэффициент парной корреляции между двумя переменными больше 0.8. Чтобы избавиться от мультиколлинеарности, в модель включают лишь один из линейно связанных между собой факторов, причем тот, который в большей степени связан с зависимой переменной.
Качество модели регрессии связывают с адекватностью модели наблюдаемым (эмпирическим) данным. Проверка адекватности (или соответствия) модели регрессии наблюдаемым данным проводится на основе анализа остатков - 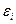 .
.
Анализ остатков позволяет получить представление, насколько хорошо подобрана сама модель и насколько правильно выбран метод оценки коэффициентов. Согласно общим предположениям регрессионного анализа, остатки должны вести себя как независимые (в действительности, почти независимые) одинаково распределенные случайные величины.
Для оценки качества модели множественной регрессии вычисляют коэффициент множественной корреляции (индекс корреляции) 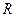 и коэффициент детерминации
и коэффициент детерминации 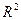 . Чем ближе к 1 значение этих характеристик, тем выше качество модели.
. Чем ближе к 1 значение этих характеристик, тем выше качество модели.
В многофакторной регрессии добавление дополнительных объясняющих переменных увеличивает коэффициент детерминации. Следовательно, коэффициент детерминации должен быть скорректирован с учетом числа независимых переменных. Скорректированный R2, или 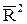 , рассчитывается так:
, рассчитывается так:
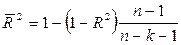 ,
,
где n — число наблюдений; k — число независимых переменных.
Для проверки значимости модели регрессии используется F-критерий Фишера, вычисляемый по формуле:
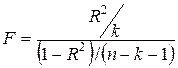
Если расчетное значение с n1= к и n2 = (n - k - 1) степенями свободы, где k – количество факторов, включенных в модель, больше табличного при заданном уровне значимости, то модель считается значимой.
Анализ статистической значимости параметров модели
значимость отдельных коэффициентов регрессии проверяется по t-статистике путем проверки гипотезы о равенстве нулю j-го параметра уравнения (кроме свободного члена):
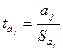 ,
,
где 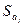 – это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии .Величина представляет собой квадратный корень из произведения несмещенной оценки дисперсии
– это стандартное (среднеквадратическое) отклонение коэффициента уравнения регрессии .Величина представляет собой квадратный корень из произведения несмещенной оценки дисперсии 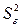 и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
и j -го диагонального элемента матрицы, обратной матрице системы нормальных уравнений.
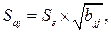
где 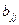 - диагональный элемент матрицы
- диагональный элемент матрицы 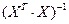 .
.
Если расчетное значение t-критерия с (n - k - 1) степенями свободы превосходит его табличное значение при заданном уровне значимости, коэффициент регрессии считается значимым. В противном случае фактор, соответствующий этому коэффициенту, следует исключить из модели, при этом оставшиеся в модели параметры должны быть пересчитаны.
Оценка влияния отдельных факторов на зависимую переменную на основе модели (коэффициенты эластичности, b - коэффициенты ).
Важную роль при оценке влияния факторов играют коэффициенты регрессионной модели. Однако непосредственно с их помощью нельзя сопоставить факторы по степени их влияния на зависимую переменную из-за различия единиц измерения и разной степени колеблемости. Для устранения таких различий при интерпретации применяются средние частные коэффициенты эластичности 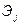 и бета-коэффициенты
и бета-коэффициенты 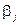 , которые рассчитываются соответственно по формулам:
, которые рассчитываются соответственно по формулам:
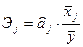 ,
, 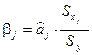
где 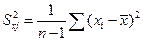 – среднеквадратическое отклонение фактора
– среднеквадратическое отклонение фактора 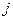 ,
,
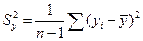 .
.
.
Коэффициент эластичности показывает, на сколько процентов изменяется зависимая переменная при изменении фактора на один процент. Однако он не учитывает степень колеблемости факторов.
Бета-коэффициент показывает, на какую часть величины среднего квадратического отклонения Sy изменится зависимая переменная Y с изменением соответствующей независимой переменной 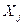 на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
на величину своего среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных.
Указанные коэффициенты позволяют упорядочить факторы по степени влияния факторов на зависимую переменную.
Долю влияния фактора в суммарном влиянии всех факторов можно оценить по величине дельта - коэффициентов 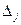 :
:
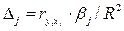
где 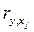 — коэффициент парной корреляции между фактором
— коэффициент парной корреляции между фактором 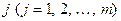 и зависимой переменной.
и зависимой переменной.
Использование многофакторных моделей для анализа и прогнозирования развития экономических систем.
Одна из важнейших целей моделирования заключается в прогнозировании поведения исследуемого объекта. Обычно термин «прогнозирование» используется в тех ситуациях, когда требуется предсказать состояние системы в будущем. Для регрессионных моделей он имеет, однако, более широкое значение. Как уже отмечалось, данные могут не иметь временной структуры, но и в этих случаях вполне может возникнуть задача оценки значения зависимой переменной для некоторого набора независимых, объясняющих переменных, которых нет в исходных наблюдениях. Именно в этом смысле — как построение оценки зависимой переменной — и следует понимать прогнозирование в эконометрике.
При использовании построенной модели для прогнозирования делается предположение о сохранении в период прогнозирования существовавших ранее взаимосвязей переменных.

