2014-02-17
2014-02-17 1153
1153| Год | S | 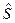 | еi | еi2 | еi - еi-1 | (еi - еi-1)2 |
| 22,48852 | -2,48852 | 6,19273 | - | - | ||
| 23,73041 | 1,269594 | 1,61187 | 3,75811 | 14,12339 | ||
| 31,00991 | -1,00991 | 1,01992 | -2,27950 | 5,19612 | ||
| 28,69796 | 1,30204 | 1,69523 | 2,31194 | 5,34507 | ||
| 33,49369 | 1,50631 | 2,26896 | 0,20427 | 0,04173 | ||
| 37,04753 | 0,95247 | 0,90719 | -0,55384 | 0,30674 | ||
| 39,53131 | 0,46869 | 0,21967 | -0,48378 | 0,23404 | ||
| 38,46125 | -0,46125 | 0,21275 | -0,92994 | 0,86479 | ||
| 45,74076 | -1,74076 | 3,03024 | -1,27951 | 1,63714 | ||
| 51,77838 | -1,77838 | 3,16263 | -0,03762 | 0,00141 | ||
| 53,02027 | 1,97973 | 3,91933 | 3,75811 | 14,12332 | ||
| Сумма | ≈0 | 24,24058 | - | 41,87375 | ||
| Среднее | 36,81818 | 36,81818 | - | - | - | - |
Проанализируем статистическую значимость параметров регрессии, предварительно рассчитав их стандартные ошибки.
Стандартная ошибка регрессии 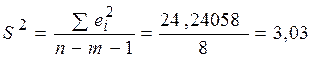
Следовательно, дисперсии и стандартные ошибки коэффициентов таковы:
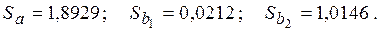
Рассчитаем соответствующие t-статистики:
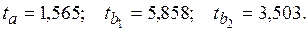
Два пареметра имеют t-статистики, превышающие тройку, что является признаком их высокой статистической значимости.
Определяем 95%-е доверительные интервалы для коэффициентов:
2,9619423 – 2,306 ´ 1,8929 < а < 2,969423 + 2306 ´ 1,8929;
-1,4031 < a < 7,3270;
0,124189 – 2,306 ´ 0,0212 < b1 < 0,124189 + 2306 ´ 0,0212;
0,0753 < b1 < 0,1731;
3,553841 – 2,306 ´ 1,0146 < b2 < 3,553841 + 2306 ´ 1,0146;
1,2141 < b2 < 5,8935.
Коэффициент детерминации R2 рассчитывается по формуле:
R2 = 1 – 24,2408 / 1087,636 = 0,9777.
Анализ статистической значимости коэффициента детерминации R2 осуществляется на основе F-статистики:
F = 0,9777 / (1 – 0,9777) ´ 8 / 2 = 175,3732.
Для определения статистической значимости F-статистики сравним ее с соответствующей критической точкой распределения Фишера:
Fкр = F(α; m; n – m – 1) = F(0,05; 2; 8) = 4,46.
Так как Fрасч = 175,3732 > Fкр = 4,46, то F - статистика, а следовательно, и коэффициент детерминации R2 статистически значимы. Это означает, что совокупное влияние переменных Y и X на переменную S существенно. Этот же вывод можно было бы сделать без особых проверок только по уровню коэффициента детерминации. Он весьма близок к единице.
Статистику DW Дарбина-Уотсона вычислим по формуле:
DW = 41,87375 / 24,24058 =1,72742.
Для проверки статистической значимости DW воспользуемся таблицей критических точек Дарбина-Уотсона. При уровне значимости α = 0,05 и числе наблюдений n = 11 имеем:
d1 = 0,658; du = 1,604.
Так как 1,604 < DW < 2,396 (du < DW < 4 – du), то гипотеза об отсутствии автокорреляции не отклоняется, т.е. считаем, что автокорреляция остатков отсутствует. Это является одним из подтверждений высокого качества модели.
В силу того, что коэффициент b2 является статистически значимым, можно утверждать, что с ростом процентной ставки увеличивается объем сбережений (коэффициент b2 имеет положительный знак). Ответ будет статистически обоснованным.
Модели временных рядов
Одномерный временной ряд
Можно построить эконометрическую модель, используя два типа исходных данных:
§ данные, характеризующие совокупность различных объектов
в определенный момент (период) времени;
§ данные, характеризующие один объект за ряд последова
тельных моментов (периодов) времени.
Модели, построенные по данным первого типа, называются пространственными моделями. Модели, построенные на основе второго типа данных, называются моделями временных рядов.
Пусть исследуется показатель Y. Его значение в текущий момент времени t обозначают yt; значения Y в последующие моменты обозначают yt+1, yt+2,…, yt+k, …; значения Y в предыдущие моменты обозначают yt-1, yt-2,…, yt - k, … При изучении зависимостей между такими показателями либо при анализе их развития во времени в качестве объясняющих переменных используются не только текущие значения переменных, но и некоторые предыдущие по времени значения, а также само время. Модели такого типа называют динамическими.
Временной ряд — это совокупность значений какого-либо показателя за несколько последовательных моментов или периодов времени. Каждый уровень временного ряда формируется под воздействием большого числа факторов, которые условно можно подразделить на три группы:
1. факторы, формирующие тенденцию ряда;
2. факторы, формирующие циклические колебания ряда;
3. случайные факторы.
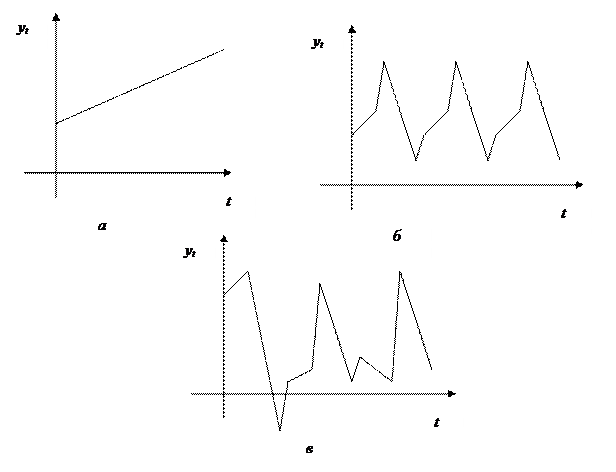
При различных сочетаниях в изучаемом явлении или процессе этих факторов зависимость уровней ряда от времени может принимать различные формы. Во-первых, большинство временных рядов экономических показателей имеют тенденцию, характеризующую совокупное долговременное воздействие множества факторов на динамику изучаемого показателя. Очевидно, что факторы, взятые в отдельности, могут оказывать разнонаправленное воздействие на исследуемый показатель. Однако в совокупности они формируют его возрастающую или убывающую тенденцию. На рис. 8.1.1 а) показан гипотетический временной ряд, содержащий возрастающую тенденцию.
Во-вторых, изучаемый показатель может быть подвержен циклическим колебаниям. Эти колебания могут носить сезонный характер, поскольку экономическая деятельность ряда отраслей экономики зависит от времени года (например, спрос на прохладительные напитки в летний период выше, чем в зимний; уровень безработицы в курортных городах в зимний период выше по сравнению с летним). При наличии больших массивов данных за длительные промежутки времени можно выявить циклические колебания, связанные с общей динамикой конъюнктуры рынка. На рис. 8.1.1 б) представлен гипотетический временной ряд, содержащий только сезонную компоненту.
Некоторые временные ряды не содержат тенденции и циклической компоненты, а каждый следующий их уровень образуется как сумма среднего уровня ряда и некоторой (положительной и отрицательной) случайной компоненты. Пример ряда, содержащего только случайную компоненту, приведен на рис. 8.1.1 в).