 2014-02-12
2014-02-12 425
425Задание
Разработать программу для решения следующей задачи:
имеется три действительных числа, представляющих собой длины трех
отрезков.
Определить, можно ли построить из них треугольник и будет ли он
прямоугольным.
Составим СПЕЦИФИКАЦИЮ программы:
1. Название задачи
Треугольник.
Название программы - Tr.
Система программирования - Турбо Паскаль.
Компьютер - IBM PC AT/486 и выше.
2. Описание задачи
Даны три действительных положительных числа a, b и c. Определить:
1. Можно ли построить треугольник из отрезков, длина которых соответственно равна a, b и c
2. Является ли этот треугольник прямоугольным?
3. Математическая модель задачи.
Известно, что условием существования треугольника является выполнение всех неравенств:
b + c > a
c + a > b (1)
a + b > c.
Если все неравенства (1) выполняются, то треугольник будет прямоугольным при выполнении хотя бы одного из равенств
a * a = b * b + c * c
b * b = c * c + a * a (2)
c * c = a * a + b * b.
Так как в (2) имеется нелинейность (возведение в квадрат вещественных чисел), то необходимо ввести следующее допущение: вычисление будем выполнять с некоторой погрешностью. Поэтому (2) преобразуем в следующие неравенства
|a * a - (b * b + c * c)|/(a * a) < e
|b * b - (c * c + a * a)|/(b * b) < e (3)
|c * c - (a * a + b * b)|/(c * c) < e
Здесь e - малая величина, определяющая относительную погрешность вычислений. Гипотенузе прямоугольного треугольника будет соответствовать переменная, стоящая первой в левой части того неравенства, которое выполняется (переменная a, b или c).
4. Управление режимами работы
В общем случае для управления режимами работы программы нужно использовать меню, в котором выбор режима осуществляется вводом номера выбранного режима. Работа с программой завершается через меню (мы опустим).
5. Входные данные
Положительные числа a, b, с и относительная погрешность e. Они должны иметь вещественный тип.
6. Выходные данные
а) На дисплей должна выдаваться справочная информация о назначении программы
б) После обработки входных данных, введенных пользователем, на дисплее должно выводиться одно из следующих сообщений
- "Это не треугольник"
- "Это прямоугольный треугольник с гипотенузой (далее указывается численное значение гипотенузы"
- "Это не прямоугольный треугольник"
7. Ошибки
При вводе чисел a, b, c и относительной погрешности e надо предусмотреть контроль:
- соответствия их типу real
- знака вводимых чисел a, b и c
- диапазона изменения значения относительной погрешности e
(0 < e < 1).
При диагностировании этих ошибок программа должна выдавать соответствующие сообщения, которые могут сопровождаться звуковым сигналом, и предлагать повторить ввод. (Это мы опустим)
Проектируем алгоритм.
НИСХОДЯЩАЯ РАЗРАБОТКА
Подумаем, какие должны быть основные уровни:
- ввод ошибки (Epsilon)
- ввод чисел (Input)
- определение типа треугольника
- вывод результатов (Result)
Структурная диаграмма программного комплекса, соответствующая сокращенному варианту программы, приведена на рис.
рис.
Как следует из структурной диаграммы, управляющий программный модуль (Треугольник) вызывает четыре подчиненных программных модуля.
Теперь подумаем о последовательности выполнения.
(2) Последовательность обработки входных данных этими программными модулями представлена в виде схемы потоков данных
рис.
Описание алгоритма в виде блок-схем.
Блок-схема управляющего программного модуля показана на следующем
Рисунке (3)
рис
Блок-схема управляющего программного модуля соответствует сложному алгоритму, в который входят унифицированные структуры СЛЕДОВАНИЕ, ВЕТВЛЕНИЕ ПОЛНОЕ и ЦИКЛ ДО.
Блок-схемы программных модулей первого уровня показаны на следующих рисунках.
(4) Программный модуль Epsilon соответствует линейному алгоритму и
состоит из унифицированных структур СЛЕДОВАНИЕ
рис
Программный модуль Input соответствует разветвляющемуся алгоритму.
В него входят унифицированные структуры СЛЕДОВАНИЕ и ВЕТВЛЕНИЕ НЕПОЛНОЕ.
рис
Программный модуль Process соответствует разветвляющемуся алгоритму.
В него входят унифицированные структуры СЛЕДОВАНИЕ и ВЕТВЛЕНИЕ НЕПОЛНОЕ
рис.
Программный модуль Result соответсвует разветвляющемуся алгоритму.
Он состоит из унифицированных структур СЛЕДОВАНИЕ и ВЕТВЛЕНИЕ ПОЛНОЕ.
рис.
Теперь можно программировать. Структурное кодирование.
программа
PROGRAM Tr;
USES Crt;
VAR
a, b, c: REAL; {значения отрезков}
Flag: REAL; {вспом. переменная}
Hyp: REAL; {гипотенуза}
e: REAL; {погрешность}
{------------------------
Ввод относительной ошибки
-------------------------}
PROCEDURE Epsilon;
BEGIN
CLRSCR;
WRITE('Введите погрешность...');
READLN (e);
END;
{-------------------------
Ввод отрезков и их проверка
--------------------------}
PROCEDURE Input;
BEGIN
WRITELN;
WRITELN('Введите значения сторон');
WRITELN;
WRITE ('a = ');
READLN (a);
WRITE ('b = ');
READLN (b);
WRITE ('c = ');
READLN (c);
Flag:=1; {это треугольник}
IF NOT ((b+c)>a) then Flag:=0;{это не треугольник}
IF NOT ((c+a)>b) then Flag:=0;{это не треугольник}
IF NOT ((b+a)>c) then Flag:=0;{это не треугольник}
END;
{-----------------------------
Процедура проверки является ли
треугольник прямоугольным
------------------------------}
PROCEDURE Process;
BEGIN
Hyp:=0; {Если Hyp=0, то это не
прямоугольный треугольник.
Иначе - прямоугольный}
IF (ABS(a * a - (b * b + c * c))) / (a * a) < e
THEN Hyp:=a;
IF (ABS(b * b - (a * a + c * c))) / (b * b) < e
THEN Hyp:=b;
IF (ABS(c * c - (b * b + a * a))) / (c * c) < e
THEN Hyp:=c;
END;
{---------------------
Вывод сообщений
----------------------}
PROCEDURE Result;
BEGIN
WRITELN;
IF Hyp <> 0
THEN WRITE('Это прямоугольный треугольник с '+
'гипотенузой ', Hyp:5:2)
ELSE WRITE ('Это не прямоугольный треугольник');
END;
{-----------------------
Управляющая программа
------------------------}
BEGIN
Epsilon;
Input;
IF Flag = 1 THEN
BEGIN
Process;
Result;
END
ELSE WRITE('Это не треугольник');
GOTOXY(1, 20);
WRITE('Для завершения - пробел');
REPEAT UNTIL KeyPressed;}
END.
16.1.3. Стратегия программирования "снизу-вверх"
«Снизу – вверх» означает, что вначале разрабатываются процедуры низшего уровня, затем они постепенно собираются в единое целое. За основу берутся уже готовые программные модули, из которых строятся другие, более сложные или недостающие в исходном наборе.
Преимущества - стандартизируются работы по программированию, упрощается накопление библиотек программ, облегчается обмен между исполнителями в процессе разработки программ и т.д.
Недостатки - сложность объединения отдельных модулей в единую систему, сложность исправления ошибок.
При разработке системы “снизу-вверх”, от отдельных задач ко всей системе, целостность теряется, возникают проблемы информационной стыковки отдельных компонентов.
В практике программирования обычно используются оба эти метода. причем при разработке новых программ предпочтение отдается методу "сверху - вниз", а при модернизации уже готовых программ – методу "снизу - вверх".
Стратегия "изнутри - наружу".
Заключается в разработке сначала наиболее сложных блоков, затем более простых.
Основные требования - время и память.
Идея: при разбиении программы на модули в первую очередь выявляются однородные части программы, которые затем оформляются определенным образом.
Примеры: 1) в трансляторах значительную долю общего объема составляют однородные модули, реализующие отдельные конструкции входного языка.
2) в текстовых редакторах - процедуры, выполняемые при нажатии функциональных клавиш
3) при моделировании некоторой установки или явления - модули, учитывающие различные физические эффекта.
После выявления однородных модулей, переходят непосредственно к программированию. Оно разбивается на этапы.
стр. 185 Горбунов
Объектно-ориентированное проектирование
Объектно-ориентированный подход состоит из объектно-ориентированного анализа (OOA), объектно-ориентированного проектирования (OOP)и объектно-ориентированного программирования(OOP).
Объектно-ориентированный анализ состоит в объектной декомпозиции предметной области, т.е. ИС представляется не набором функций, а совокупностью объектов, взаимодействующих друг с другом. Объекты обладают поведением, состоянием, свойствами, которые реализуются в виде подпрограмм (функций). Т.о., ООП включает в себя возможности структурного подхода, но объектно-ориентированное проектирование в большей степени реализует модель реального мира и соответствует естественной логике человеческого мышления. Объектно-ориентированное программирование состоит в записи уже созданной объектно-ориентированной модели на алгоритмическом языке.
Моделирование объекта в программе осуществляется с помощь объектных типов (классов). Конкретный объект (переменная) является экземпляром класса. Описание класса включает данные и функции (члены класса), характеризующие свойства, состояние и поведение объектов, и обеспечивает инкапсуляцию (скрытие) информации.
Основные принципы ООП:
- наследование
- полиморфизм
- инкапсуляция
Наследование состоит в процессе создания новых классов (классов-потомков) на основе уже имеющихся классов (предков) с передачей их свойств и методов по наследству. Этот принцип был введен для избежания ненужной работы по написанию одинакового кода.
Полиморфизм заключается в возможности вызова для данного объекта при необходимости одноименных методов классов-предков.
(См. ниже в описании синтаксиса оператор указания диапазона).
Инкапсуляция является важным приемом ООП, организующим защиту информации от ненужных и случайных модификаций, что обеспечивает целостность данных и упрощает отладку программного кода после изменений.
Вручную обычно приходится писать лишь небольшие фрагменты кода, в основном для ускорения и упрощения разработки используются визуальные методы. Однако знание синтаксиса ООП необходимо для правильного обращения к объектам и понимания логики их взаимодействия.
CASE - технологии
Под CASE- технологией понимается совокупность средств автоматизации
разработки информационной системы, включающей в себя методолгию
анализа предметной области, программирования и эксплуатации ИС.
Инструментальные средства CASE- технологий применяются на всех
этапах жизненного цикла системы (от анализа и проектирования до
внедрения и сопроволдения), значительно упрощая решение возникающих
задач.
CАSE- технология позволяет отделить проектирование информацион-
ной системы от собственно программирования и отладки:разработчик
системы занимается проектированием на более высоком уровне, не
отвлекаясь на детали. Это позволяет не допустить ошибок уже на
стадии проектирования и получить более совершенные программные
продукты. Эта технология изменяет все стадии разработки ИС, более
всего отражаясь на этапах анализа и проектирования.
Нередко применение CASE- технологии выходит за рамки проектирования
и разработки ИС. Технология дает возможность оптимизировать модели
организационных и управленческих структур компаний и позволяет
им лучше решать такие задачи, как планирование, финансирование,
обучение. Таким образом, CASE- технология позволяет произвести ради-
кальное преобразование деятельности компании, направленное на оптима-
льную реализацию того или иного проекта или повышение общей эффектив-
ности бизнеса.
Коллективная работа над проектом предполагает обмен информацией,
контроль выполнения задач, отслеживание изменений и версий, плани-
рование, взаимодействие и управление. Фундаментом реализации подоб-
ных функций чаще всего служит общая база данных проекта, которую
обычно называют репозитарием. По существу, репозитарий - это
информационный архив, где хранятся сведения о процессах, данных
и связях объектов в разрабатываемом приложении.
В различных CASE-технологиях репозитарий реализуется по-разному и
может содержать описания и модели данных, а также правила их обра-
ьотки. Репозитарий является важнейшим компонентом набора инструмен-
тальных средств CASE и служит источником информации, необходимой
для автоматизации построения проектируемых систем и генераций при-
ложений. Кроме того, CASE-продукты на базе репозитария позволяют
разработчикам использовать в работе над проектом и другие инстру-
ментальные средства, например, пакеты быстрой разработки программ.
В настоящее время CASE-технологии - одна из наиболее динамично
развивающихся отраслей информатики, объединяющая сотни компаний.
Из имеющихся на рынке CASE-технологий можно выделить:Application
Development Workbench (ADW) фирмы Knowledge Ware, BPwin и ERwin,
CDEZ Tods (Oracle), Clear Case (Alria Software), Composer (Texas
Instrument), Discover Development Information System (Software
Emancipation Technology).
Современные CASE-технологии успешно применяются для создания
автоматизированных ИС различного класса:банки, финансовые корпо-
рации, крупные фирмы. Они обычно имеют достаточно высокую стои-
мость и требуют длительного обучения и кардинальной реорганизации
всего процесса создания АИС. Тем не менее экономический эффект
применения CASE-технологий весьма значителен, и большинство сов-
ременных серьезных программных проектов осуществляется именно с
их помощью.
СПОСОБЫ ЗАПИСИ АЛГОРИТМОВ
В процессе разработки алгоритма могут использоваться различные
способы его описания. Они различаются наглядностью, компактностью,
степенью формализации, ориентацией на машинную реализацию и исполь-
зование другими пользователями.
В практике программирования наибольшее применение получили
следующие формы записи алгоритмов:
- словесная и формульно - словесная;
- блок - схемы, структурограммы и Р-схемы;
- псевдокоды и решающие таблицы;
- язык операторных схем;
- языки программирования.
Все формы кроме последней являются вспомогательными.
Любая из форм представления алгоритмов должна содержать следую-
щие элементы:
- начало и конец вычислительной схемы;
- объекты(данные), над которыми выполняются действия, и резуль-
таты выполнения алгоритма;
- этапы(шаги) преобразования данных с формализованной записью
их содержания;
- указания о последовательности выполнения этапов и отдельных
шагов алгоритмического процесса.
СЛОВЕСНАЯ ФОРМА используется для алгоритмов, ориентированных на
исполнителя - человека. Здесь содержание последовательных этапов вы-
числений задается в произвольной форме на естественном языке. Команды
алгоритма нумеруют, чтобы иметь возможность на них ссылаться. Испол-
нение алгоритма происходит в порядке возрастания номеров шагов, начиная
с первого.
ФОРМУЛЬНО-СЛОВЕСНЫЙ способ использует помимо словесного описания
еще математические символы и выражения.
Предполагается, что отдельные шаги выполняются в последовательности
их записи, если нет указаний обхода определенных шагов.
Пример классического алгоритма Евклида для нахождения наибольшего
ОД двух положительных (не равных нулю) чисел А и В.
ПРИМЕР. ШАГ 1. Начало вычислительного процесса.
ШАГ 2. Ввод значений А и В.
ШАГ 3. Если А = В, то перейти к ш. 5, иначе к ш. 4.
ШАГ 4. Если А > В, то А = А-В, иначе В=В-А. Перейти к ш.3.
ШАГ 5. Вывод результата: "НОД значений А, В "равно" А.
ШАГ 6. Конец вычислительного процесса.
Недостатком словесного способа записи алгоритма является отсутст-
вие более или менее строгой формализации и наглядности вычислитель-
ного процесса.
ПРЕИМУЩЕСТВО - можно описывать алгоритм с произвольной степенью
детализации.
Формульно-словесный также обеспечивает любую степень детализации,
но он более компактен и нагляден.
БЛОК - СХЕМЫ и СТРУКТУРОГРАММЫ
Блок-схемы представляют алгоритм в наглядной графической форме.
Команды алгоритма помещаются внутрь стандартных блоков, соеди-
ненных стрелками, показывающими очередность выполнения команд алгоритма.
Блок - схемы вы отчасти знаете, мы на них останавливаться
не будем. Только запишем ГОСТ 19.707-90 На экзамене будет вопрос.
Рис
Ссылка на методичку 1936. Стр. 17 - 24 изучить самостоятельно.
Р - схемы описываются в ГОСТе 19.005-85
Структурограммы
Для изображения алгоритмов используются как и в блок-схемах
специальные блоки. Каждый блок имеет форму прямоугольника и может
быть вписан в любой внутренний прямоугольник любого другог блока.
Блоки дополняются элементами словесной записи с помощью предложений
на естественном языке или с использованием математических обозна-
чений. Очень важно то, что исключается операция безусловного пере-
хода goto
1. Блок обработки(вычислений). Каждый символ структурограммы
является блоком обработки и обозначается прямоугольником. Каждый
прямоугольник внутри любого символа представляет собой также блок
обработки.
2. Блок следования. Этот символ объединяет ряд следующих друг за
другом процессов обработки.
3. Блок решения. Применяется для обозначения структуры типа раз-
ветвления. Условие располагается в верхнем треугольнике, варианты
решения - по сторонам треугольника, а процессы обработки обозна-
чаются прямоугольниками слева и справа.
Если в блоке решения отсутствует одна из ветвей, то применяется
сокращенный блок решения.
4. Блок варианта. Этот символ представляет расширение блока решения.
Те варианты выхода из этого блока, которые можно сформулировать точно,
размещаются слева. Остальные объединяются в один, называемый выходом
по несоблюдению условий и расположенный справа. Если нужно перечислить
все возможные случаи, правую часть можно оставить незаполненной или
совсем опустить.
5.Блок цикла с предусловием. Этот символ обозначает циклическую
конструкцию с проверкой условия в начале цикла. Условие окончания
цикла размещается в верхней полосе, сливающейся с левой полосой,
указывающей границу цикла. Данная структура может быть использована
также для обозначения цикла с параметром. При этом вверху указывают
закон изменения параметра цикла.
6. Блок цикла с постусловием. Этот символ аналогичен блоку цикла с
предусловием, но условие располагается внизу.
Сравнить блок-схему и структурограмму алгоритма Евклида
Р- схемы описываются ГОСТом 19.005-85.
ПСЕВДОКОД это частично формализованная запись для наглядного
представления схем алгоритмлв и программ, разрабатываемых в соот-
ветствии с общими принципами структурного программированияю. стр. 18
методички 1936.
Он ориентирован на человека и занимает промежуточное место между
естественным и формальным языками. В псевдокоде не приняты строгие
синтаксические правила для записи команд. Вместе с тем имеются некоторые
конструкци, присущие формальным языкам. Для этого вводятся служебные слова.
Рис.
Решающие таблицы в основном используются для разработки прорграмм
логического типа, в которых требуется проверка многочисленных логи-
ческих условий.
ОПЕРАТОРНАЯ СХЕМА - это аналитическая форма представления алгоритма
с помощью операторов, описывающих содержание некоторых автономных
этапов или детальных шагов вычислительного процесса.
Предполагается, что каждый такой этап реализуется посредством
арифмитического оператора А, выполняющего вычисления, и логического
оператора Р(условие), проверяющего соблюдение определенных условий.
Дополняют еще специальными операторами V - ввод, W - вывод, С - конец
и т.д. В П О
Такая схема является логической схемой программы.
Минимальные правила формализации:
- каждый оператор имеет порядковый номер в виде индекса;
- операторы выполняются в естественном порядке - слева напрво;
- если нет передачи управления оператору справа, то между
ними указывается;
- при выполнении логического оператора очередным становится
оператор, записанный справа от него, иначе подлежащий выполнению
оператор указывается стрелкой.
Рис.
где V1 - ввод значений А и В. Р3 - проверка условия; А5 и А6 - вычисление
значений А-В и В-А. W - вывод результатов.
Программа на Паскале.
БАЗОВЫЕ (СТАНДАРТНЫЕ) ТИПЫ ДАННЫХ
Данные различаются между собой
1) способом кодирования;
2) набором допустимых компьютерных операций над ними.
Например, над закодированными целыми числами можно выполнять ариф-
метические операции, а с символами это лишено смысла.
При программировании основой для классификации данных служит
набор допустимых операций над данными, а не способ их представ-
ления в памяти.
Все данные, для которых допустим определенный набор компь-
ютерных операций, объединим в один класс и дадим этому классу имя
(название). Такой поименованный класс назовем базовым типом дан-
ных.
Для описания базового типа нужно
1) составить функциональное описание базового типа.Охарактери-
зовать каждую допустимую операцию, т.е. сформулировать правило опре-
деления значения результатат для всех возможных значений участвующих
в ней данных.
2) каждый базовый тип имеет определенную физическую реализа-
цию в компьютере, т.е. способы кодирования и доступы к значениям
данных.
Перечень всех возможных значений данных и характеристики
допустимых для них операций представляют собой функциональное
описание базового типа.
Кроме того каждый базовый тип имеет определенную физическую
реализацию в компьютере, т.е. способы кодирования и доступы к зна-
чениям данных.
Обычно пользователь имеет возможность оперировать с несколькими
базовымим типами данных. С какими именно, определяется не столько
моделью компьютера, сколько применяемыми средствами программиро-
вания.
Какие же типы данных обычно бывают базовыми? Базовыми данными
являются как правило, переменные, перечисление, интенрвал. А базо-
выми типами: целый,вещественный, булевый, символьный.
Абстрактные типы данных (структуры)
На практике исходные данные, промежуточные и окончательные ре-
зультаты удобнее представлять не в виде базовых типов данных, а с
помощью более сложных структурных единиц.
Под абстрактным типом данных (структурой) понимается поименованная
совокупность данных, которые имеют один и тот же набор допустимых
операций.
Перечень и характеристики всех операций представляют собой функ-
циональное описание структуры.
Описание отдельных составляющих элементов исходной структуры,
представляющих более простые структуры и даже базовые типы, а также
операций с данными исходной структуры через операции над составляющими
простыми элементами называется логическим описанием исходной структу-
ры.
Последний уровень описания структуры данных - физическое представ-
ление, которое дает способы хранения структур в памяти, доступа к ним,
а также выполнения операций.
К абстрактным структурам данных относятся массивы, строки, запись,
файл, структура, смесь(объединение). стр.62
Массивы представляют собой переменные с индексами и служат для
описания структур, состоящих из множества элементов, упорядоченных
в соответствии со значениями индексов. Причем массивы в зависимости
от числа индексов различают одномерные (один индекс), двумерные и т.д.
Массив можно представить как папку с пронумероваванными докумен-
тами (информацией), каждый из которых может быть прочитан или заменен
на другой.
С функциональной точки зрения простейший массив Т - это совокупность
N элементов одинаковой структуры, каждому из которых поставлен в соот-
ветствие порядковый номер 1, 2,...., N, называемый индексом. Для мас-
сива Т определены следующие операции:
- создание массива Т, имеющего N элементов, значения которых иногда
бывают еще не определены;
- чтение элемента с заданным индексом i = 1, 2,..., N,
результатом котрых является элемент Т(i), имеющий этот индекс, а также
исходный массив Т;
- замена элемента массива с данным индесом i на данный элемент G, в
результате которой получается новый массив, отличающийся от исходного
наличием элемента G на i-м месте (T(i)=G).
Логическое описание массива представлено на рис. 1, а физическое
представление - на рис.2.
Рис. 3.13 и 3.14 стр.67 в Ларионове.
Строка - это последовательность символов. Операции со строками вы-
ражаются через операции с символамит: операция присоединения двух
строк, сравнения, вырезания слева, справа и из строки подстроки и т.д.
Динамические структуры данных
К динамическим структурам данных относятся стек, дек, очередь,
список.
Испытания. Контрольные примеры. Сквозной контроль.
(из файла treugol.doc)
Пример 2. Требуется написать программу, которая по времени начала отсчета и числу прошедших секунд выдаст время остановки секундомера согласно 24-часовому исчислению времени. Например, если секундомер был пущен в 1 час дня (13 часов) и число прошедших секунд равно 3662, то результат будет 14 часов 1 мин. и 2 сек.
Вначале надо понять задачу.
Задача понятна!!! Приступаем.
Разбиваем задачу на крупные шаги:
1. Прочитать время пуска секундомера и число прошедших секунд.
2. Вычислить время остановки секундомера.
3. Изобразить это время на экране.
Теперь надо эти три шага рассмотреть вместе и убедиться, что
они выполняют требуемую обработку. Затем надо рассмотреть каждый шаг по
очереди и по мере необходимости детализировать его.
Первый шаг элементарен и заключается в реализации операций вывода
на экране приглашения и ввода времени пуска и числа прошедших секунд.
Значит этот шаг детализировать не нужно.
А вот, чтобы перевести 2-й шаг на язык программирования нужны дополнительные рассуждения. Этот шаг можно рассматривать отдельно и дополнить деталями его выполнения.
Если поделить нацело число прошедших секунд на 60, то в результате получится число прошедших минут. В остатке окажется число секунд, которое надо добавить ко времени пуска секундомера. Если при сложении число секунд превысит 59, то надо уменьшить его на 60, а число прошедших минут увеличить на единицу. В результате деления нацело числа прошедших минут на 60 получится число прошедших часов. Полученный при этом делении остаток даст число минут, которое надо добавить ко времени
пуска. Если при сложении число минут превысит 59, то надо уменьшить его на 60 и увеличить число прошедших часов на единицу. Наконец, число прошедших часов надо добавить ко времени пуска и скорректировать результат в том случае, если произойдет переход на следующие сутки.
Деление нацело можно проделать с помощью операции DIV, а отыскание остатка - с помощью операции MOD. Обсудив способ реализации указанный на шаге 2 обработки можно написать следующий план этого шага:
1) Вычислить число прошедших минут и секунд. Добавить число прошедших секунд ко времени пуска, корректируя в случае необходимости число прошедших минут и счетчик минут времени остановки секундомера.
2) Вычислить число прошедших часов и минут. Добавить число прошедших минут ко времени пуска, корректируя в случае необходимости число прошедших часов и счетчик минут времени остановки секундомера.
(Отметить в программе)
3) Добавить число прошедших часов ко времени пуска с тем, чтобы получить час остановки секундомера, корректируя его в случае перехода на следующие сутки.
Теперь надо просмотреть эти шаги и убедиться, что если они будут один за другим выполнены, то получится как раз то, что указано на шаге 2.
Требуемые для реализации этих шагов приемы рассмотрены нами настолько подробно, что можно писать программу, не детализируя более процесс разработки. Для составления программы теперь достаточно написать операторы, реализующие шаг 1, за ними - операторы, реализующие шаг 23, за ними - операторы, реализующие шаг 3.
sekunda;
(* Эта программа читает время пуска секундомера и число прошедших
секунд и изображает на экране время остановки секундомера *)
var
Максимальный диапазон секундомера от 0 до 32767
p_t:0..maxint; прошедшее время в секундах
sek,s,min,m:0..118; (59*2)
has,h:0..48;
begin
writeln('Введите время пуска секундомера');
write('Часы = ');
readln(has);
write('Минуты = ');
readln(min);
write('Секунды = ');
program readln(sek);
writeln('Введите прошедшее время в секундах');
readln(p_t);
s:=p_t mod 60; число прошедших минут
m:=p_t div 60;
sek:=sek+s;
m:=m+sek div 60; сложение минут с новым значением
sek:=sek mod 60; получение оставшихся секунд
p_t:=m;
m:=p_t mod 60;
h:=p_t div 60;
min:=min+m;
has:=has+min div 60;
min:=min mod 60;
has:=(has+h) mod 24;
writeln('Время остановки = ','часы',has:3,' мин',min:3,' сек',sek:3)
end.
Мы рассмотрели пример решения вычислительной задачи.
Пример решения задачи не вычислительного характера Карасев В.
ТЕХНОЛОГИЯ ПРОГРАМИРОВАНИЯ.. 1
I. ЧТО ПЛАНИРУЕТСЯ. 1
II. ЛИТЕРАТУРА.. 1
1. СТРУКТУРА И СОСТАВ ПО ИС.. 14
2. КРИТЕРИИ КАЧЕСТВА ПРОГРАММ... 26
3. ТЕХНОЛОГИЯ ПРОГРАММИРОВАНИЯ ВВОДА-ВЫВОДА ИНФОРМАЦИИ ПРИ РАБОТЕ С ФАЙЛАМИ ДАННЫХ 37
4.1 Файлы и записи. 37
4.2. Обработка файлов данных в Паскале. 39
Однако для типизированных файлов и файлов без типа с по- 39
VAR.. 39
VAR.. 39
TYPE.. 39
VAR.. 40
VAR.. 40
VAR.. 40
Text_Inf: TEXT; 40
VAR.. 40
Например. 40
VAR.. 40
VAR.. 41
- для обновления. 41
Для записи информации в файл из программы служит процедура. 41
5.Чтение. 42
Процедура Read читает последовательность символов из файла. 42
VAR.. Ошибка! Закладка не определена.
При окончании работы всей программы происходит автоматичес- 43
Для явного завершения действий с файлом используется проце- 43
При этом ликвидируются внутренние буферы, образованные при. 43
VAR.. 44
IORESULT. 45
Данная функция возвращает целое число, соответствующее коду. 45
Коды ошибок, возвращаемые функцией IOresult, приведены в. 45
Удаление. 46
Добавление. 46
Изменение. 46
Просмотр. 46
Выход. 46
(3) Отображение введенных значений для подтвержения записи в файл или считанных из файла для просмотра. 46
Алгоритм.. 46
Какие еще возможны алгоритмы?. 47
- ввод нового значения числа жителей; 47
- читаем последовательно очередную запись в цикле пока не конец. 47
3) вывод данных. 57
Процедуры.. 57
Структуры данных. 57
Основной файл. 57
PROGRAM T_2F; 58
USES CRT; 58
TYPE.. 58
END; 58
VAR.. 58
Fname – ВХОДНОЙ ПАРАМЕТР – ИМЯ ОСНОВНОГО ФАЙЛА.. 58
END; 59
END; 59
ПРОЦЕДУРА ВВОДА ФАЙЛА СПРАВОЧНИКА.. 59
Fname – ВХОДНОЙАРАМЕТР ИМЯ ФАЙЛА.. 59
BEGIN.. 59
BEGIN.. 59
END; 59
END; 59
ПРОЦЕДУРА ВЫВОДА РЕЗУЛЬТИРУЮЩЕЙ ТАБЛИЦЫ... 59
BEGIN.. 60
END; 60
END; 60
BEGIN.. 60
CLRSCR; 60
READLN; 61
END. 61
4. МЕСТО И РОЛЬ ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ.. Ошибка! Закладка не определена.
В ПРОГРАММИРОВАНИИ.. Ошибка! Закладка не определена.
5. Жизненный цикл и этапы разработки ПО.. 61
Рисунок. 61
Рисунок. 62
Процессы.. 62
Стадии. 63
Анализ Проектирование Реализация ТестированиеВнедрениеэксплуатация. 63
Трудозатраты при классической разработке ПО, %... 69
6. Процессы классической технологии программирования. 69
6.1. ВОЗНИКНОВЕНИЕ И ИССЛЕДОВАНИЕ ИДЕИ.. 70
6.3 Постановка задачи(УСТАНОВЛЕНИЕ и анализ ТРЕБОВАНИЙ) И ПРОЕКТИРОВАНИЕ.. 71
B = B – A.. 87
Конец если. 87
Пример с вычислением площади крышки стола. 88
6.4. ПРОГРАММИРОВАНИЕ (РЕАЛИЗАЦИЯ, КОДИРОВАНИЕ) 88
Порядок разработки программного модуля. 88
Самостоятельно. 89
Классификация языков программирования. 89
На выбор языка программирования влияют следующие основные факторы.. 89
Самостоятельно. 91
Провила оформления программ на Паскале, на Delphi 91
6.5. Тестирование и отладка. 92
6.6. УПРАВЛЕНИЕ и разработка документации. 92
6.7. Испытания, ввод в эксплуатацию.. 92
6.8.ЭКСПЛУАТАЦИЯ и СОПРОВОЖДЕНИЕ. 93
6)программирование заново. 94
Пример решения вычислительной задачи. 95
Тогда 0.2*x1 + 0.3*x2 - это количество произведенных из этих заготовок продукта 1. Также. 96
Сложим 1-е и 2-е неравенства получим неравенство. 97
7. ТЕХНОЛОГИЯ ПРОГРАММИРОВАНИЯ СОРТИРОВКИ ИНФОРМАЦИИ.. 98
7.1. Постановка задачи сортировки. 98
F(XLi) < F(XLj), если K(XLi)=K(XLj) при i < j. 99
7.2. Классификация алгоритмов сортировки. 99
В настоящее время известно несколько десятков различных. 99
1) Все методы сортировки в зависимости от структуры информации. 99
2) В сравнительных методах элементы сортируются по относительной. 99
4) В зависимости от используемого метода сортировки упорядоченная. 99
5) Кроме того, исходная последовательность может быть задана вся. 100
Процесс сортировки записей состоит из просмотров и сравнений. 100
7.3. Сортировка обменом.. 100
7.3.1. Метод стандартного обмена. 100
Этот метод основан на попарном сравнении ключей соседних. 100
Так как на каждом из просмотров очередные наибольшие элементы.. 101
Алгоритм А. 101
I=2; 4 1 5 2 3. 101
I=3; 4 1 2 5 3. 101
J=2, I=1; 1 4 2 3 5. 101
I=2; 1 2 4 3 5. 101
I=3; 1 2 3 4 5. 101
J=3, I=1; 1 2 3 4 5. 101
I=2; 1 2 3 4 5. 101
I=3; 1 2 3 4 5. 101
J=4, I=1; 1 2 3 4 5. 101
I=2; 1 2 3 4 5. 101
I=3; 1 2 3 4 5. 101
Пример сортировки файла в программе о городах. 101
Второй просмотр идентичен первому лишь с той разницей, что он. 101
Алгоритм Б. 102
I=2; 4 1 5 2 3. 102
I=3; 4 1 2 5 3. 102
J=2, I=1; 1 4 2 3 5. 102
I=2; 1 2 4 3 5. 102
I=3; 1 2 3 4 5. 102
J=3, I=1; 1 2 3 4 5. 102
I=2; 1 2 3 4 5. 102
J=4, I=1; 1 2 3 4 5. 102
Пример программы с городами и файлами. 102
Алгоритм В. 102
Структурограмма алгоритма сортировки методом стандартного. 102
I=2; 4 1 5 2 3. 103
I=3; 4 1 2 5 3. 103
FLAG=1. 103
J=2, FLAG=0; I=1; 1 4 2 3 5. 103
I=2; 1 2 4 3 5. 103
I=3; 1 2 3 4 5. 103
FLAG=1. 103
J=3, FLAG=0; I=1; 1 2 3 4 5. 103
I=2; 1 2 3 4 5. 103
FLAG=0. 103
Т.е. сократили число просмотров. 103
Процедура реализации. 103
J:=1; 103
K [I]:= K [I + 1]; 103
Качественные: 103
7.3.2. Метод Шелла. 104
Пример. Исходная последовательность. 105
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 105
K(1) K(5) K(9) 105
K(3) K(7) 105
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 105
Затем шаг J сокращается вдвое и становится равным 2. Образуются. 105
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 105
Затем снова J сокращается вдвое и становится равным 1. При. 105
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 105
7.3.3. Челночная сортировка. 106
I=1; 106
I=2; 106
I=1; 106
I=3; 106
I=2; 106
I=1; 107
1. Число сравнений постоянно. 107
N*(N-1) /2. 107
2. Число обменов: 107
3. Дополнительный объем памяти требуется для запоминания одной записи при реализации операции обмена. 107
FLAG=0; 107
FLAG=1; I=0; 107
FLAG=0; 108
FLAG=1; I=1; 108
FLAG=1; I=0; 108
FLAG=0; 108
FLAG=1; I=2; 108
FLAG=1; I=1; 108
FLAG=0; 108
FLAG=0; 108
FLAG=1; I=3; 108
FLAG=1; I=2; 108
FLAG=0; 108
7.3.4. Шейкер-сортировка. 108
Особенность шейкер-сортировки заключается в том, что в отличие. 108
На 1-м просмотре производится сравнение ключей соседних запи- 108
При программировании: одна процедура - просто шаг разный. 109
I=1; 4 5 1 2 3. 109
I=2; 4 1 5 2 3. 109
M=4, FLAG=1; 110
L=4, FLAG=0; 110
I=4; 4 1 2 3 5. 110
I=3; 4 1 2 3 5. 110
M=2, FLAG=1; 110
R=2, FLAG=0; 110
I=2; 1 2 4 3 5. 110
I=3; 1 2 3 4 5. 110
L=3, FLAG=0; 110
I=3; 1 2 3 4 5; 110
R=3. 110
7.4. Сортировка выбором.. 110
7.4.1 простой линейный выбор (монеты, структурограмма, пример) 110
I=3; 111
I=4; 111
I=5; 111
J=2, I=3; 111
I=4; 111
I=5; 111
J=3, I=4; 111
I=5; 111
7.4.2 Линейный выбор с обменом.. 111
I=5; 112
J=2, L=2, 112
I=4; L=4, 112
J=3, L=3, 112
J=4, L=4, 113
7.5. Сортировка вставками. 114
При сортировке вставками записи просматриваются по одной и. 114
Известны следующие методы сортировки вставками: простая. 114
Все записи условно разделяются на две части - упорядоченную.. 114
7.5.1 Простая вставка. 114
Алгоритм сортировки простыми вставками производится в цикле. 114
Структурограмма алгоритма сортировки методом вставки представлена. 114
I=0. 114
I=1. 115
I=0. 115
I=2. 115
I=1. 115
I=3. 115
I=2. 115
7.5. 2. Метод Шелла (сортировка с убывающим шагом) 116
Структурограмма метода Шелла с сортировкой вставкой отдельных. 116
При Н = 1 – обычная вставка. 116
Пример. Исходная последовательность. 116
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 116
K(1) K(5) K(9), K(2) K(6), K(3) K(7) и K(4) K(8) 116
После упорядочения элементов внутри каждой последовательности. 116
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 116
Затем шаг H сокращается вдвое и становится равным 2. Образуются. 116
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 117
Затем снова H сокращается вдвое и становится равным 1. При. 117
К(1) К(2) К(3) К(4) К(5) К(6) К(7) К(8) K(9) 117
7.6. Сортировка слиянием.. 117
Сортировка слиянием является процессом объединения двух или. 117
В результате образуются примерно N/2 частей размером в два эле- 118
Ниже показано, как выполняется этот процесс на последова- 118
Исходный файл: [25] [57] [48] [37] [12] [92] [86] [33] 118
7.7. Сортировка таблицы адресов (индексная сортировка) 118
Объем данных, помещенных в каждую из записей файла, может. 118
Пример программы работы с файлом данных. 119
Пусть каждая запись файла данных содержит два поля: табельный номер. 119
Type. 119
Var 120
Var 120
Var 120
Var 121
{ Сортируем X }. 121
If X[wJ+1].Tn < X[wJ].Tn Then Begin. 121
{ Теперь записываем получившийся массив в Index.Dat }. 122
Begin. 122
Begin. 123
Index.dat 125
Внешняя сортировка. 125
НБ3. 125
Этот набор данных разбивается на два НБ1 и НБ2, например нечетные. 125
После 1-го цикла. 125
2L.. 125
После 2-го цикла. 125
НБ1. 126
7.8. Алфавитная сортировка. 126
- символы используемого алфавита имеют упорядоченные коды ASCI. 126
FLAG:0..1; 126
J:=1; 127
X[I]:=X[I+1]; 127
X[I+1]:=T; 127
FLAG:=1; 127
J:=J+1. 127
J:=1; 128
X[I]:=X[I+1]; 129
X[I+1]:=T; 129
FLAG:=1; 129
N.. 129
Примеры.. 130
8. МОДЕЛИ ЖИЗНЕННОГО ЦИКЛА ПО.. 130
Подходы на основе формальных преобразований: 131
Технологические подходы быстрой разработки: 131
8.1.КЛАССИЧЕСКИЕ КАСКАДНЫЕ ТЕХНОЛОГИЧЕСКИЕ МОДЕЛИ.. 131
8.1.1 Каскадная модель. 132
Процессы.. 132
.................................................................................................................................. Стадии. 132
8.1.2 Каскадно-вовратная модель. 134
Процессы.. 135
Стадии. 135
8.1.3 Каскадно-итерационная модель. 136
Процессы.. 136
Стадии. 137
8.1.4 Каскадная модель с подпроцессами. 138
Процессы.. 138
Стадии.. 139
Здесь требуется дополнительная фаза тестирования подсистем до. 140
8.1.5 Спиральная модель. 140
Процессы.. 140
Стадии. 141
10. ТЕХНОЛОГИЯ ПРОГРАММИРОВАНИЯ ПОИСКА ИНФОРМАЦИИ.. 143
10.1 Постановка задачи. 143
При реализации алгоритма поиска существуют две возможности его. 144
1) внешние и внутренние, статические и динамические, где статический. 144
Мы будем изучать внутренние, статические методы поиска, основанные. 144
10.2 Последовательный поиск. 144
10.3. Методы поиска в упорядоченных наборах данных. 146
Известны следующие методы поиска: бинарный, однородный бинар- 146
10.2.1 Бинарный поиск. 147
**] - означает верхнюю границу интервала поиска, соответствующую.. 148
10.2.2 Метод золотого сечения. 148
Для уменьшения временных затрат при реализации вычисления золото- 148
Алгоритм поиска методом золотого сечения аналогичен алгоритму би- 148
I=|_(P-Q)/1,619031 _|+Q. 149
10.2.3. Интерполяционный поиск. 149
Лине́йная интерполя́ция — интерполяция алгебраическим двучленом P1(x) = ax + b функции f, заданной в двух точках x0 и x1 отрезка [a, b]. 149
Отличие интерполяционного поиска от предыдущих методов. 149
Алгоритм интерполяционного поиска также аналогичен алгоритму би- 149
I = |_ (P-Q)(A-KQ)/(KP-KQ) _| + Q. 149
Пример. Осуществить интерполяционный поиск аргумента 51 в массиве. 149
Q,P,I,FLAG,A,KP,KQ:integer; 150
FLAG:=0; 150
P:=N; 150
Q:=1; 150
FLAG:=1; 150
Writeln('Объект не найден'); 150
FLAG:=1; 150
Writeln('Объект успешно найден ' + I) 150
Q:=I+1. 150
P:=I-1; 150
Всего положительных элементов N, date[0]=0. 150
10.2.4 Однородный бинарный поиск. 150
При однородном бинарном поиске аргумент поиска А сравнивается с. 150
I=I+-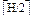 ; H=
; H=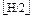 .......... 151
.......... 151
Структурограмма алгоритма однородного бинарного поиска приведена. 151
Примечания.. 151
10.2.5 Фибоначчиев поиск (самостоятельно) 151
При реализации этого метода для нахождения интервала поиска. 151
Структурограмма алгоритма поиска приведена на рис. 152
Пример 1. 152
А = 8, N = 6. 152
Пример 2. 153
А = 12, N = 6. 153
I=6; P=1; m = 1; 153
Пример 3. 153
А = 11, N = 6. 153
10.2.6 Блочный поиск. 153
Пример. 154
Характеристики методов поиска (количество сравнений). 154
Пример общей программы организации телефонного справочника с. 154
11. ДОКУМЕНТИРОВАНИЕ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ, ЕСПД.. 155
11.1. Виды программной документации. 155
11.2. ТРЕБОВАНИЯ К СОДЕРЖАНИЮ И ОФОРМЛЕНИЮ И ПРОГРАММНЫХ ДОКУМЕНТОВ.. 159
4)порядок проведения и. 161
Приводятся описания применяемых методов испытаний с указанием.. 161
В приложении к документу об испытаниях программы могут быть. 161
11. ТЕСТИРОВАНИЕ ПРОГРАММНЫХ ПРОДУКТОВ.. 163
2) Из-за хакера могли погибнуть астронавты.. 164
11.1 Ручной контроль программного обеспечения. 164
11.2 Структурное тестирование. 164
2) Для тестирования программы с помощью критерия покрытия условий можно использовать следующий набор тестов: 164
11.3 Функциональное тестирование. 164
11.4. Тестирования модулей и комплексное тестирование. 164
11.5. Оценочное тестирование. 164
11.6 Автоматизированное тестирование (АТ). 164
Segue SilTest 164
Ration Robot 164
13. ОТЛАДКА ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ.. 164
13. ОПТИМИЗАЦИЯ ПРИКЛАДНОГО ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ.. 164
13.1. Постановка задачи. 164
13.2. Оптимизация циклов. 164
DO 1 I = M, N, L.. 164
Тело цикла. 164
Правило 1. 164
A[I]:=0; 164
A[1]:=0; A[2]:=0; 164
Правило 2. 164
Правило 3. 164
1 CONTINUE.. 164
Как видно из приведенных выше примеров, путем развертки или. 164
Правило 4. 164
S = (L - 1) 164
В данном случае удается сэкономить N-1 вычитание. 164
13.3 Оптимизация вычислительных операций. 164
Правило 5. 164
Правило 6. 164
Правило 7. 164
Экономии времени на операциях присваивания можно. 164
Правило 8. 164
Правило 9. 164
Правило 10. 164
Правило 11. 164
Правило 12. 164
Например. 164
Таким образон можно выделить следующие процедуры oптимизации. 164
Правило 13. 164
13.4 Особенности оптимизации программ на языке Turbo Pascal 164
Правило 14. 164
Правило 15. 164
Правило 16. 164
Т.Е. 164
IF(J<>0) AND ((2/J)>X) THEN.... 164
WHILE (I<=LENGTH(S)) AND (S[I]<>'') DO... 164
Правило 17. 164
Правило 18. 164
Правило 19. 164
Правило 20. 164
Еще пример. 164
Правило 21. 164
Type. 164
Правило 22. 164
If ((ch>='0')and(ch<='9')) or 164
'A'..'Z', 164
Правило 23. 164
Правило 24. 164
Правило 25. 164
14. АРХИТЕКТУРА ПРОГРАММНОГО СРЕДСТВА.. 164
14.2. Основные классы архитектур программных средств. 164
Рис. 6.2. Конвейер параллельно действующих программ. 164
14.3. Архитектурные функции. 164
14.4. Контроль архитектуры программных средств. 164
15. РАЗРАБОТКА СТРУКТУРЫ ПРОГРАММЫ И.. 164
МОДУЛЬНОЕ ПРОГРАММИРОВАНИЕ.. 164
15.1. Цель модульного программирования. 164
15.2. Основные характеристики программного модуля. 164
15.3. Понятие модуля в Паскале (Delphi) 164
15.4. Методы разработки структуры программы. 164
Рис. Классификация методов разработки структуры программ. 164
15.5. Контроль структуры программы.. 164
16. ТЕХНОЛОГИИ И СТРАТЕГИИ ПРОГРАММИРОВАНИЯ.. 164
16.1. ТЕХНОЛОГИЯ СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ (метод пошаговой детализации) 164
16.1.1 Цели и принципы структурного программирования. 164
Пример абстракции и уточнения.. 164
16.1.2. СТРАТЕГИЯ НИСХОДЯЩЕГО СТРУКТУРНОГО ПРОГРАММИРОВАНИЯ (сверху-вниз) 164
Проектируем алгоритм. 164
НИСХОДЯЩАЯ РАЗРАБОТКА.. 164
VAR.. 164
Ввод относительной ошибки. 164
BEGIN.. 164
CLRSCR; 164
END; 164
Ввод отрезков и их проверка. 164
BEGIN.. 164
WRITELN; 164
WRITELN; 164
END; 164
Процедура проверки является ли. 164
BEGIN.. 164
Hyp:=0; {Если Hyp=0, то это не. 164
END; 164
Вывод сообщений. 164
BEGIN.. 164
WRITELN; 164
IF Hyp <> 0. 164
END; 164
Управляющая программа. 164
BEGIN.. 164
END.. 164
GOTOXY(1, 20); 164
END. 164
16.1.3. Стратегия программирования "снизу-вверх". 164
Объектно-ориентированное проектирование. 164
CASE - технологии. 164
Под CASE- технологией понимается совокупность средств автоматизации. 164
СПОСОБЫ ЗАПИСИ АЛГОРИТМОВ.. 164
В процессе разработки алгоритма могут использоваться различные. 164
Пример классического алгоритма Евклида для нахождения наибольшего. 164
БЛОК - СХЕМЫ и СТРУКТУРОГРАММЫ... 164
Структурограммы.. 164
Для изображения алгоритмов используются как и в блок-схемах. 164
Р- схемы описываются ГОСТом 19.005-85. 164
ПСЕВДОКОД это частично формализованная запись для наглядного. 164
БАЗОВЫЕ (СТАНДАРТНЫЕ) ТИПЫ ДАННЫХ.. 164
Данные различаются между собой. 164
Абстрактные типы данных (структуры) 164
Рис. 3.13 и 3.14 стр.67 в Ларионове. 164
Динамические структуры данных. 164
Тема: Рабочее время.








