2014-02-13
2014-02-13 743
743Пусть наблюдения за выходным результатом y производятся при m различных значениях (уровнях) единичного фактора X. Например, деталь может изготавливаться на m различных однотипных станках, т.е. фактор – станок; либо квалификация рабочего и т.п.).
На каждом i-м (i = 1..m) уровне фактора x проведено ni наблюдений (изготовлено ni деталей) и получены результаты наблюдений (размеры деталей) 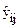 (i = 1..m, j = 1..ni).
(i = 1..m, j = 1..ni).
Общее число наблюдений N = 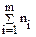 .
.
Результаты наблюдений можно представить в виде таблицы
(матрица наблюдений)
| Уровни фактора (станки) | Номера наблюдений | |||||
| … | j | … | ni | |||
| y11 | y12 | y1j | y1n1 | |||
| … | ||||||
| i | yij | |||||
| … | ||||||
| m | ym1 | ym2 | ymj | ymnm |
Результаты наблюдений, расположенные в одной строке называются группой, все множество результатов – совокупностью.
Модель однофакторного ДА (дисперсионного анализа) основывается на предположениях:
1. В пределах каждой группы значения наблюдений можно представить в виде
=  +
+ 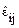 (i = 1..m), где
(i = 1..m), где
- случайные ошибки факторов за счет неучтенных факторов (ошибки наблюдений);
- математическое ожидание выходной переменной y при i-м уровне фактора x (групповое среднее).
2. В генеральной совокупности групповое математическое ожидание может быть представлено в виде
= 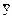 + ai (i = 1..m), где
+ ai (i = 1..m), где
- математическое ожидание переменной y в генеральной совокупности;
ai - эффект i-й группы (i-уровня).
Отсюда ai = - , а суммарный эффект от действия всех уровней (групп) должен быть равен нулю
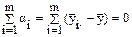 .
.
На основании этого результат наблюдения можно представить в виде
= (+ ai) + , (i = 1..m; j = 1..ni).
3. Ошибкираспределены по нормальному закону с нулевым математическим ожиданием me = 0 и одинаковой дисперсией De = s2 и некоррелированы (независимы, т.к. нормальный закон) между собой, т.е.
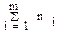 для всех j ¹ k.
для всех j ¹ k.
Обозначим по результатам наблюдений
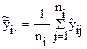 - групповое (внутригрупповое) среднее;
- групповое (внутригрупповое) среднее;
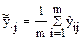 - межгрупповое среднее;
- межгрупповое среднее;
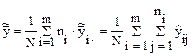 - общее среднее.
- общее среднее.
Запишем очевидное тождество
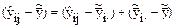
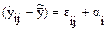 .
.
Возведем обе части в квадрат и просуммируем по всем уровням i и наблюдениям j
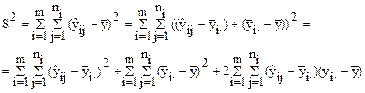
Т.к. 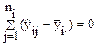 при " i = 1..m, то последнее слагаемое (как сумма отклонения от среднего положения) всегда будет равно 0, следовательно
при " i = 1..m, то последнее слагаемое (как сумма отклонения от среднего положения) всегда будет равно 0, следовательно
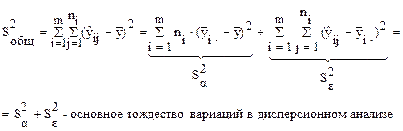
Sобщ = Sфакт + Sост, здесь
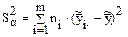 - факторная вариация отклонения;
- факторная вариация отклонения;
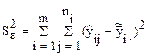 - остаточная вариация отклонения (сумма квадратов отклонения)
- остаточная вариация отклонения (сумма квадратов отклонения)
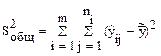 - общая (полная) вариация.
- общая (полная) вариация.
Величина 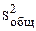 характеризует отклонения наблюдаемых значений y относительно общего среднего (общее отклонение).
характеризует отклонения наблюдаемых значений y относительно общего среднего (общее отклонение).
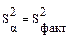 - характеризует отклонение средних по уровням относительно общего среднего, вызываемое действием фактора.
- характеризует отклонение средних по уровням относительно общего среднего, вызываемое действием фактора.
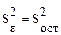 - характеризует отклонение относительно средних по уровням, возникающие за счет ошибки наблюдений.
- характеризует отклонение относительно средних по уровням, возникающие за счет ошибки наблюдений.
Из вариаций , 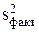 ,
, 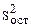 могут быть получены несмещенные оценки соответствующих дисперсий путем осреднения с использованием соответствующего числа степеней свободы.
могут быть получены несмещенные оценки соответствующих дисперсий путем осреднения с использованием соответствующего числа степеней свободы.
Под числом степеней свободы некоторой величины А в статистике понимается разность между числом наблюдений и числом констант, найденных по этим же опытам независимо друг от друга и используемых для нахождения этой величины. Т.е. число независимых слагаемых.
В нашем случае число степеней свободы будет равно
Для : r0 = N - 1 (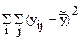 )
)
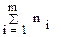 - всего наблюдений;
- всего наблюдений;
1 – число используемых констант (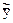 ).
).
Для 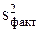 : rфакт = m – 1 (
: rфакт = m – 1 (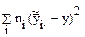 )
)
m - число слагаемых (уровней);
1 – число используемых констант ().
Для : rост = N – m (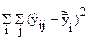 )
)
m - число используемых констант (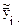 ).
).
При этом выполняется условие:
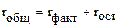 .
.
Оценки дисперсии при неизвестных математических ожиданиях , равны:
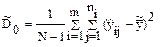 - общая
- общая
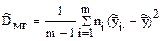 - межгрупповая (факторная)
- межгрупповая (факторная)
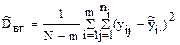 - остаточная (внутригрупповая)
- остаточная (внутригрупповая)
Величина 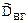 отлична от влияния факторов и характеризует оценку дисперсии ошибки наблюдений (
отлична от влияния факторов и характеризует оценку дисперсии ошибки наблюдений (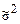 ).
).
Кроме этих оценок дисперсии в ДА используется еще групповая дисперсия, характеризующая рассеивание результатов наблюдений в i-й группе относительно группового среднего (математического ожидания)
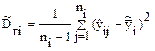 .
.
Знание величины дисперсий позволяет провести анализ существенности влияния фактора х на результаты наблюдений.
Анализ влияния фактора на результаты наблюдений.
При анализе влияния фактора х на результаты наблюдений решаются две задачи.
1. Определяется существенность влияния фактора на результаты (на значения выходной переменной у).
2. Если влияние существенно, то выявляется уровень фактора, влияющий на результаты наблюдений наиболее существенно.
Дисперсионный анализ базируется на следующей теореме разложения для c2 распределения.
Пусть сумма Q состояния из N квадратов независимых нормально распределенных случайных величин xi с mxi = 0; sxi = 1 разбита на m сумм квадратов нормально распределенных случайных величин Q1, Q2,… Qm соответственно с r1, r2,… rm степенями свободы.
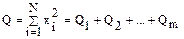 .
.
Тогда, если выполняется условие N = r1 + r2 +…+ rm, то случайные величины Q1, Q2,… Qm будут независимыми и распределены по закону распределения c2 с числом степеней свободы соответственно r1, r2,… rm.
Т.к. в нашем случае ошибки наблюдений подчинены нормальному закону распределения с me = 0, De = s2, то можно показать, что соответствующие вариации Sобщ, Sфакт, Sост подчинены s2 × c2 распределению с числом степеней свободы соответственно rобщ, rфакт, rост.
При этом rобщ = N – 1 = rфакт + rост = (m-1) + (N-m) = N – 1, т.е. условие выполняется.
Для проведения дисперсионного анализа представим результаты в форме таблицы дисперсионного анализа.
| Источник рассеивания | Сумма квадратов отклонений | Число степеней свободы | Оценка дисперсии |
| 1. Между уровнями фактора (факторные) | 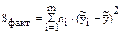 | rфакт = m - 1 | 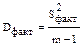 |
| 2. Ошибки наблюдений | 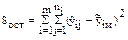 | rост = N - m | 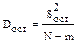 |
| 3. Общее отклонение | 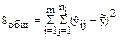 | rобщ = N - 1 | 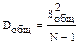 |