 2017-12-14
2017-12-14 4368
4368Расчет параметров уравнения линейной регрессии, проверку их статистической значимости и построения интервальных оценок можно выполнить значительно быстрее автоматически при использовании Пакета анализа Excel (программа «Регрессия»)
Пусть исходные данные примера 2.1 (расходы на питание – личный доход) представлены в Excel.
Выбираем команду Анализ данных→Регрессия.
В диалоговом окне режима Регрессия задаются следующие параметры:
® Входной интервал У – вводится ссылка на ячейки, содержащие данные по результативному признаку.
® Входной интервал Х – вводится ссылка на ячейки, содержащие факторные признаки.
® Метки – установите флажок в активное состояние, если выделены и заголовки столбцов.
® Константа- ноль – установите флажок в активное состояние, если оцениваете регрессионное уравнение без свободного члена.
При необходимости задаются и другие параметры.
Результаты расчетов с использованием инструмента Регрессия выводятся под общим названием Вывод итогов в виде следующих таблиц.
| Регрессионная статистика | |
| Множественный R | 0,952 |
| R- квадрат | 0,907 |
| Нормированный R- квадрат | 0,875 |
| Стандартная ошибка | 1,817 |
| Наблюдения |
| Дисперсионный анализ | |||||
| df | SS | MS | F | Значимость F | |
| Регрессия | 96,1 | 96,1 | 29,12 | 0,01247 | |
| Остаток | 9,9 | 3,3 | |||
| Итого |
| Коэффи- циенты | Стандартная ошибка | t-статис- тика | P- зна- чение | Нижнее 95% | Верхние 95% | |
| Y – пересеч. | -1,75 | 1,65 | -1,06 | 0,36669 | -7,001 | 3,501 |
| X | 0,775 | 0,14361 | 5,40 | 0,01247 | 0,318 | 1,232 |
Результаты работы программы «Регрессия» полностью совпадают с полученными ранее расчетами.
При необходимости выводятся предсказанные значения  результативного признака и значения остатков.
результативного признака и значения остатков.
| ВЫВОД ОСТАТКА | ||
| Наблюдение | Предсказанное у | Остатки |
| -0,2 | 1,2 | |
| 2,9 | -0,9 | |
| -2 | ||
| 9,1 | 1,9 | |
| 12,2 | -0,2 |
Коэффициенты регрессии, их стандартные ошибки и коэффициент детерминации составляют:
a = -1,75; b =0,775;  = 1,65;
= 1,65;  =0,143;
=0,143;  = 0,907
= 0,907
Результаты регрессионного анализа принято записывать в виде:
ȳ= -1,75+0,775х; = 0,907,
( 1,65 )( 0,143 )
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Статическая значимость коэффициента  = 0,907 устанавливается по F – тесту. Поскольку Значимость F= 0,0124 <α=0,05, то = 0,907 значим при уровне 5%. Модель в целом значима.
= 0,907 устанавливается по F – тесту. Поскольку Значимость F= 0,0124 <α=0,05, то = 0,907 значим при уровне 5%. Модель в целом значима.
Обычно проверка значимости коэффициента а не производится. Оценим статистическую значимость коэффициента b.
Поскольку P – значение = 0,0124 < 0,05, то коэффициент b = 0,775 значим на уровне 5%.
Результаты оценивания регрессии совместимы не только с полученным значением коэффициента регрессии b = 0,775, но и с некоторым его множеством (доверительным интервалом). С вероятностью 95% доверительный интервал коэффициента b есть (0,318 ….1,232).
Пример. Имеются данные (усл. ед.) о расходах на питание y и душевого похода х для девяти групп семей:
| х | |||||||||
| у |
Используя результаты работы программы «Регрессия», проанализируйте зависимость расходов на питание от величины душевого дохода.
Результаты регрессионного анализа записываем в виде:
ȳ= 66,04+0,107 х, = 0,885,
( 11,72 ) ( 0,015 )
где в скобках указаны стандартные ошибки коэффициентов регрессии.
Качество модели оценивается коэффициентов .
Величина = 0,885 означает, что фактором душевого дохода можно объяснить 88,5% вариации (разброса) расходов на питание.
Установим статистическую значимость коэффициента .
Поскольку Значимость F = 0,000158 < α = 0,05, то =0,885 значим при уровне 5%.
Направление связи между переменными у и х определяет знак коэффициента b =0,107 ˃ 0, т.е. связь является прямой(положительной).
Коэффициент b =0,107 показывает, что при увеличении душевого дохода на 1 усл. ед. расходы на питание в среднем увеличиваются на 0,107 усл. ед.
Оценим статистическую значимость коэффициента b. Поскольку Р – значение = 0,000158 < α = 0,05, то коэффициент b =0,107 значим на 5 %-ном уровне. С вероятностью 95% доверительный интервал коэффициента b есть (0,073; 0,142).
Вследствие большой популярности эконометрических исследований на Западе средства построения эконометрических моделей включены во все известные интегрированные офисные средства (Microsoft Office, Perfect Office и т. д.) и табличные процессоры (Excel, Lotus 1-2-3, Quattro Pro и др.).
Рассмотрим методику построения эконометрических моделей с помощью встроенных функций Microsoft Excel.
Построение эконометрических моделей требует выполнения множества расчетов по определению параметров и характеристик.
В зависимости от целей исследования и вида уравнения регрессии расчеты в Excel могут быть выполнены с помощью различных функций ЛИНЕЙН, ЛГРФПРИБЛ, ТЕНДЕНЦИЯ, РОСТ и др.
Приведем методику использования MS Excel для построения эконометрических уравнений на примере линейной регрессии (ЛИНЕЙН).
Встроенная статистическая функция ЛИНЕЙН определяет параметры линейной регрессии:
y=mx+b или y=m1x1 + m2x2 +...+ b,
где зависимое значение y является функцией независимого значения x. Значения m - это коэффициенты, соответствующие каждой независимой переменной x, а b - константа.
Синтаксис:
ЛИНЕЙН (известные значения y; известные значения x; конст; статистика)
известные значения y - это множество значений y, которые уже известны для соотношения y=mx+b.
Массив известные значения х может содержать одно или несколько множеств переменных.
Конст - это логическое значение, которое указывает, требуются ли, чтобы константа b была равна нулю. Константа принимает одно из двух значений ИСТИНА или ЛОЖЬ. Если конст имеет значение истина или опущено, то b вычисляется, если конст имеет значение ЛОЖЬ, то b полагается равным 0.
Статистика - это логическое значение, которое указывает, требуется ли вернуть дополнительную статистику по регрессии.
Статистика также принимает одно из значений ИСТИНА или ЛОЖЬ. В первом случае дополнительная статистика рассчитывается, во втором случае не рассчитывается.
Дополнительные статистические характеристики функции ЛИНЕЙН приведены ниже Дополнительные статистические характеристики функции ЛИНЕЙН приведены ниже:
b, m1, m2,…mn – коэффициенты регрессии (параметры модели);
se1, se2,...,sen - стандартные значения ошибок для коэффициентов m1,m2,...,mn;
seb - стандартное значение ошибки для постоянной b;
r2 - коэффициент детерминированности;
sey - стандартная ошибка для оценки y;
F - F -статистика, используемая для определения того, является ли наблюдаемая взаимосвязь между зависимой и независимой переменными случайной или нет;
df - степени свободы, используемые для нахождения F -критических значений в статистической таблице (для определения уровня надежности модели нужно сравнить значения в таблице с F -статистикой функции ЛИНЕЙН);
ssreg - регрессионая сумма квадратов;
ssresid - остаточная сумма квадратов.
Характеристики выводятся на экран дисплея в виде приведенного ниже массива (таблицы):
| mn | mn-1 | … | m2 | m1 | b |
| sen | Sen-1 | … | se2 | se1 | seb |
| r2 | Seу | … | |||
| F | Df | … | |||
| ssreg | ssresid | … |
Порядок выполнения расчетов следующий:
1. Вводятся исходные данные или открывается существующий файл, содержащий исходные данные.
2. В рабочем окне Excel выделяется диапазон ячеек 5*(n +1) (5 число строк, (n +1) - число столбцов, n – число показателей факторов) для вывода результатов расчета.
3. Активизируются "Мастер функций" любым из способов:
а) в главном меню выбирается Вставка/Функция;
б) на панели инструментов Стандартная нажимается кнопка (fx)

4. В появившемся окне "Мастер функций шаг 1 из 2" среди категорий выбирается Статистические, среди функций - ЛИНЕЙН шаг 1 из 2 (рис. 3.1.1)
Рис. 3. 1. 1. Диалоговое окно "Мастер функций шаг 1 из 2"
5. В появившемся втором окне "Мастер функций" (рис. 3. 1. 2)
вводятся аргументы, т.е. указываются диапазоны ячеек рабочего окна EXCEL, в которых находятся исходные данные для У и Х, а также значения аргументов константа и статистика.
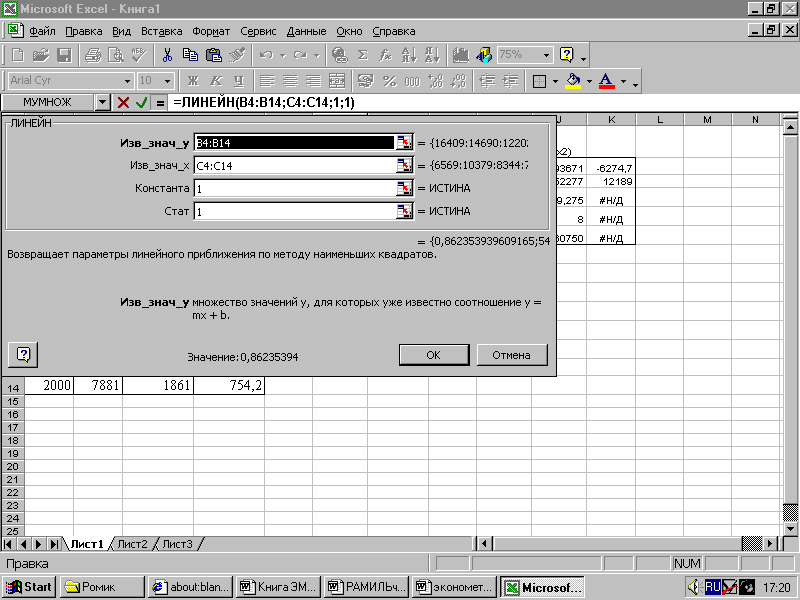
Рис. 3. 1. 2. Второе диалоговое окно "Мастер функций"

Рис. 3. 1. 3. Результат вычисления функции ЛИНЕЙН
6. Нажимается кнопка ОК. В выделенном диапазоне рабочего окна
Excel появляется результат - численное значение для коэффициента регрессии (b). Чтобы вывести всю статистику следует нажать клавишу <F2>, а затем - комбинацию клавиш <Ctrl>+<Shift>+<Enter>.

