 2014-02-02
2014-02-02 4861
4861После того как данные получены, очищены, приведены к единому виду и помещены в хранилище, их необходимо анализировать. Для этого используется технология OLAP.
Двенадцать определяющих принципов OLAP были сформулированы в 1993 году Е.Ф.Коддом, "изобретателем" реляционных баз данных. OLAP - это OnLine Analytical Processing, то есть оперативный анализ данных. Позже определение Кодда было переработано в так называемый тест FASMI (Fast Analysis of Shared Multidimensional Information - быстрый анализ разделяемой многомерной информации), который требует, чтобы OLAP-приложение предоставляло следующие возможности быстрого анализа разделяемой многомерной информации: высокая скорость; анализ; разделение доступа; многомерность; работа с информацией..
Высокая скорость. Анализ должен производиться одинаково быстро по всем аспектам информации. При этом допустимое время отклика составляет не более 5 секунд.
Анализ. Должна существовать возможность производить основные типы числового и статистического анализа - предопределенного разработчиком приложения или произвольно определяемого пользователем.
Разделение доступа. Доступ к данным должен быть многопользовательским, при этом должен контролироваться доступ к конфиденциальной информации.
Многомерность. Основная, наиболее существенная характеристика OLAP.
Работа с информацией. Приложение должно иметь возможность обращаться к любой нужной информации, независимо от ее объема и места хранения.
Многомерное представление. OLAP предоставляет организациям максимально удобные и быстрые средства доступа, просмотра и анализа деловой информации. Что наиболее важно - OLAP обеспечивает пользователя естественной, интуитивно понятной моделью данных, организуя их в виде многомерных кубов (Cubes). Осями [L1][L2](dimensions) многомерной системы координат служат основные атрибуты анализируемого бизнес-процесса. Например, для процесса продаж это может быть категория товара, регион, тип покупателя. Практически всегда в качестве одного из измерений используется время. Внутри куба находятся данные, количественно характеризующие процесс, - так называемые меры (Measures). Это могут быть объемы продаж в штуках или в денежном выражении, остатки на складе, издержки и т.п. Пользователь, анализирующий информацию, может "нарезать" куб по разным направлениям, получать сводные (например, по годам) или, наоборот, детальные (по неделям) данные и осуществлять прочие операции, которые необходимы ему для анализа.
Хранение данных OLAP. В первую очередь нужно сказать о том, что, поскольку аналитик всегда оперирует некими суммарными (а не детальными) данными, в базах данных OLAP практически всегда хранятся наряду с детальными данными и так называемые агрегаты, то есть заранее вычисленные суммарные показатели. Примерами агрегатов может служить суммарный объем продаж за год или средний остаток товара на складе. Хранение заранее вычисленных агрегатов - это основной способ повышения скорости выполнения OLAP-запросов.
Однако построение агрегатов может привести к значительному увеличению объема базы данных.
Другой проблемой хранения OLAP-данных является разреженность многомерных данных. Например, если в 2000 году продаж в некотором регионе не было, то на пересечении соответствующих измерений куба не будет никакого значения. Если OLAP-сервер будет хранить в таком случае некое отсутствующее значение, то при значительной разреженности данных количество пустых ячеек (требующих, тем не менее, места для хранения) может во много раз превысить количество заполненных, и в результате общий объем неоправданно возрастет. Решения, предлагаемые для этого компанией Microsoft, приводятся ниже.
Разновидности OLAP. Для хранения OLAP-данных могут использоваться:
Специальные многомерные СУБД (OLAP-серверы). В этом случае говорят о MOLAP (Multidimensional OLAP). При выполнении сложных запросов, анализирующих данные в различных измерениях, многомерные СУБД обеспечивают большую производительность, чем реляционные. При этом скорость выполнения запроса не зависит от того, по какому измерению производится «срез» многомерного куба.
Традиционные реляционные СУБД - ROLAP (Relational OLAP). Применение специальных структур данных - схемы «звезды» (star) и «снежинки» (snowflake), а также хранение вычисленных агрегатов делают возможным многомерный анализ реляционных данных. Реляционные СУБД исторически более привычны, и в них сделаны значительные инвестиции, поэтому пока ROLAP более распространен.
Комбинированный вариант - HOLAP (Hybrid OLAP), совмещающий и тот и другой вид СУБД. Одним из вариантов совмещения двух типов СУБД является хранение агрегатов в многомерной СУБД, а детальных данных (имеющих наибольший объем) - в реляционной.
Компания Microsoft предлагает следующие средства OLAP-анализа:
В комплект Microsoft SQL Server 7.0 входит полнофункциональный OLAP-сервер - SQL Server OLAP Services. Сервер, естественно, предназначен для обслуживания запросов клиентов, а для этого требуется некий протокол взаимодействия и язык запросов. Например, для взаимодействия клиента с серверной реляционной СУБД - SQL Server - используются протоколы ODBC или OLE DB и язык запросов SQL. Для доступа к OLAP-серверу компанией Microsoft был разработан протокол OLE DB for OLAP и язык запросов к многомерным данным - MDX (MultiDimensional eXpression). Аналогично тому, как для упрощения и удобства над OLE DB разработан слой объектов ADO (ActiveX Data Objects), над OLE DB for OLAP построен ADO MD (MultiDimensional ADO).
Средства анализа данных в Microsoft Office 2000. Microsoft Excel 2000 содержит новый механизм сводных таблиц - OLAP PivotTable, который заменил собой одноименный механизм предыдущих версий. Наряду с прежними возможностями анализа реляционных данных, механизм PivotTable теперь включает возможности анализа OLAP-данных, то есть выступает в качестве OLAP-клиента. В качестве сервера может использоваться Microsoft SQL Server 7.0, а также любой продукт, поддерживающий интерфейс OLE DB for OLAP. Механизм сводных таблиц Excel в полном объеме поддерживает возможности, предоставляемые описанным выше сервисом PivotTable Services (PTS). Таким образом, анализируемые OLAP-данные могут находиться как в локальных кубах, так и на OLAP-сервере.
Microsoft Office 2000 содержит также набор ActiveX-компонентов, называемых Office 2000 Web Components, которые позволяют организовать анализ OLAP-данных средствами просмотра Web. К ним относятся следующие четыре компонента:
Spreadsheet - реализует ограниченную функциональность листа Excel.
PivotTable - "близнец" сводных таблиц Excel; может работать с данными OLAP Services.
Chart - позволяет строить диаграммы, основанные как на реляционных, так и на OLAP-данных.
Data Source - служебный компонент для привязки остальных компонентов к источнику данных.
При работе с OLAP-данными Web Components обращаются к PivotTable Services.
5.5. ТЕХНОЛОГИЯ АНАЛИЗА «DATA MINING»
Появление технологии Data Mining связано с необходимостью извлекать знания из накопленных информационными системами разнородных данных. Возникло понятие, которое по-русски стали называть «добыча», «извлечение» знаний. За рубежом утвердился термин «Data Mining».
Широко использовавшиеся раньше методы математической статистики оказались полезными главным образом для проверки заранее сформулированных гипотез (verification-driven data mining) и для «грубого» разведочного анализа, составляющего основу оперативной аналитической обработки данных (online analytical processing – OLAP).
Ключевое достоинство «Data Mining» по сравнению с предшествующими методами – возможность автоматического порождения гипотез о взаимосвязи между различными параметрами или компонентами данных. Работа аналитика при работе с традиционным пакетом обработки данных сводится фактически к проверке или уточнению одной-двух порожденных им самим гипотез. В тех случаях, когда начальных предположений нет, а объем данных значителен, существующие системы теряют работоспособность и превращаются в пожирателей времени аналитика.
Еще одна важная особенность систем Data Mining возможность обработки многомерных запросов и поиска многомерных зависимостей. Уникальна также способность систем data mining автоматически обнаруживать исключительные ситуации – т.е. элементы данных, "выпадающие" из общих закономерностей.
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining
ассоциация
классификация
кластеризация
прогнозирование
Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей. Примеры заданий на такой поиск при использовании Data Mining приведены в таблице 1.
Таблица 1 – Сравнение формулировок задач при использовании методов OLAP и Data Mining
| OLAP | Data Mining |
| Каковы средние показатели травматизма для курящих и некурящих? | Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму? |
| Каковы средние размеры телефонных счетов существующих клиентов в сравнении со счетами бывших клиентов (отказавшихся от услуг телефонной компании)? | Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании? |
| Какова средняя величина ежедневных покупок по украденной и не украденной кредитной карточке? | Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками? |
Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной статистики, распознавания образов, методов искусственного интеллекта, теории баз данных и др. (см. рис. 2).
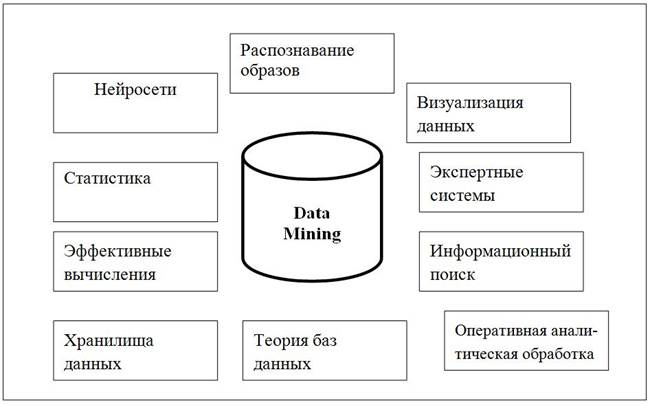
Рис.2. Data Mining как мультидисциплинарная система
Системы Data Mining интегрируют в себе сразу несколько подходов, но, как правило, с преобладанием какого-то одного компонента.
Приведем примеры некоторых возможных бизнес-приложений Data Mining.
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки с маркой магазина и компьютеризованные системы контроля. Типичные задачи, которые можно решать с помощью DataMining в сфере розничной торговли, это анализ покупательской корзины, исследование временных шаблонов, создание прогнозирующих моделей.
Анализ покупательской корзины (анализ сходства) предназначен для выявления товаров, которые покупатели стремятся приобретать вместе. Знание покупательской корзины необходимо для улучшения рекламы, выработки стратегии создания запасов товаров и способов их раскладки в торговых залах.
Исследование временных шаблонов помогает торговым предприятиям принимать решения о создании товарных запасов. Оно дает ответы на вопросы типа: «Если сегодня покупатель приобрел видеокамеру, то через какое время он вероятнее всего купит новые батарейки и пленку?».
Создание прогнозирующих моделей дает возможность торговым предприятиям узнавать характер потребностей различных категорий клиентов с определенным поведением, например, покупающих товары известных дизайнеров или посещающих распродажи. Эти знания нужны для разработки точно направленных, экономичных мероприятий по продвижению товаров.
Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач:
Выявление мошенничества с кредитными карточками. Путем анализа прошлых транзакций, которые впоследствии оказались мошенническими, банк выявляет некоторые стереотипы такого мошенничества.
Сегментация клиентов. Разбивая клиентов на различные категории, банки делают свою маркетинговую политику более целенаправленной и результативной, предлагая различные виды услуг разным группам клиентов.
Прогнозирование изменений клиентуры. Data Mining помогает банкам строить прогнозные модели ценности своих клиентов и соответствующим образом обслуживать каждую категорию.
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь также можно использовать методы Data Mining: для выявления мошенничества и анализа риска.
Выявление мошенничества. Страховые компании могут снизить уровень мошенничества, отыскивая определенные стереотипы в заявлениях о выплате страхового возмещения, характеризующих взаимоотношения между юристами, врачами и заявителями.
Анализ риска. Путем выявления сочетаний факторов, связанных с оплаченными заявлениями, страховщики могут уменьшить свои потери по обязательствам. Известен случай, когда в США крупная страховая компания обнаружила, что суммы, выплаченные по заявлениям людей, состоящих в браке, вдвое превышают суммы по заявлениям одиноких людей. Компания отреагировала на это новое знание пересмотром своей общей политики предоставления скидок семейным клиентам.
В настоящее время для решения задач DM используются нейросетевые технологии, статистические пакеты SAS, SPSS, STATISTICA, STATGRAPHICS и др. Исследование данных (Data Mining – DM) – одно из самых ценных новшеств SQL Server 2000.
В версии SQL Server 7.0 специалисты Microsoft впервые реализовали аналитическую службу OLAP, предоставляющую возможности составления нерегламентированных (гибких) запросов и анализа данных. В процессе работы с нерегламентированными запросами аналитик точно знает, на какие вопросы клиент хотел бы получить ответы, и просто извлекает нужную информацию из куба OLAP. Например, управляющий заведением типа Fast-food мог бы спросить: "Какова тенденция роста доходов и прибыли от продажи гамбургеров за последние четыре квартала?"
При проведении специального анализа данных аналитик имеет представление о том, что интересует его клиента, но перечня точно сформулированных вопросов у него нет. Например, в компании известно, что некоторые принадлежащие ей магазины розничной торговли не приносят дохода, но никто не понимает, чем это вызвано. Аналитик начинает навигацию по кубу данных OLAP, следуя за предположением, которое кажется ему наиболее верным. При этом он то углубляется в детали, то вращает размерности многомерного куба данных.
Исследование данных средствами DM отличается и от работы с нерегламентированными запросами, и от специального анализа данных. При проведении исследования данных службы Analysis Services путешествуют по информационным измерениям самостоятельно, отыскивают данные, которые относятся к делу, и представляют эти данные пользователю.
SQL Server 2000 применяет для предоставления возможностей DM новый интерфейс приложений (API), называемый OLE DB for Data Mining (OLE DB for DM).
В состав SQL Server 2000 вошли два алгоритма DM, так называемые деревья принятия решений и алгоритм кластеризации.

