 2015-05-30
2015-05-30 4644
4644Интерпретация результатов заключается в том, что проводятся расчеты по математической модели и анализ полученного решения. Если модель удовлетворяет требованиям качества, то она может быть использована для прогнозирования, либо для анализа внутреннего механизма исследуемых процессов. Оцененная эконометрическая модель может использоваться как для структурного анализа, включая обратное влияние на экономическую теорию, так и для прогнозирования и связанной с ним выработки экономической политики.
12. Определение тесноты связи между факторами: линейный коэффициент корреляции, коэффициент детерминации.
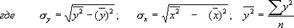 |
Уравнение регрессии всегда дополняется показателем тесноты связи. При использовании линейной регрессии в качестве такового показателя выступает линейный коэффициент корреляции r.
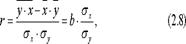 |
Одна из формул линейного коэффициента корреляции имеет вид:
Коэффициент корреляции находится в пределах: - 1 < r < 1.
Если b > 0, то 0 < r < 1, и, наоборот, при b < 0, - 1 < r < 0.
Линейный коэффициент корреляции оценивает тесноту связи рассматриваемых признаков в ее линейной форме. Поэтому близость абсолютного значения линейного коэффициента корреляции к нулю еще не означает отсутствие связи между признаками. При нелинейном виде модели связь может оказаться достаточно тесной.
Квадрат линейного коэффициента корреляции называется коэффициентом детерминации. Он характеризует долю дисперсии результативного показателя y, объясняемую регрессией.
Соответственно величина 1 - r2 характеризует долю дисперсии у, вызванную влиянием остальных, неучтенных в модели, факторов.
13. Оценка тесноты связи в нелинейной регрессионной модели.
Уравнение нелинейной регрессии, так же, как и в случае линейной зависимости, дополняется показателем тесноты связи. В данном случае это индекс корреляции: 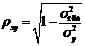 . (1.21)
. (1.21)
Величина данного показателя находится в пределах: 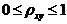 . Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
. Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
Квадрат индекса корреляции носит название индекса детерминации и характеризует долю дисперсии результативного признака 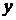 , объясняемую регрессией, в общей дисперсии результативного признака:
, объясняемую регрессией, в общей дисперсии результативного признака:
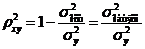 , (1.22)
, (1.22)
т.е. имеет тот же смысл, что и в линейной регрессии;
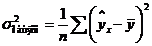 .
.
Индекс детерминации 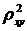 можно сравнивать с коэффициентом детерминации
можно сравнивать с коэффициентом детерминации 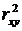 для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
Индекс детерминации используется для проверки существенности в целом уравнения регрессии по 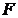 -критерию Фишера:
-критерию Фишера:
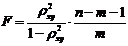 , (1.23)
, (1.23)
где – индекс детерминации, 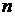 – число наблюдений,
– число наблюдений, 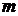 – число параметров при переменной
– число параметров при переменной 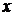 . Фактическое значение -критерия (1.23) сравнивается с табличным при уровне значимости
. Фактическое значение -критерия (1.23) сравнивается с табличным при уровне значимости 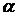 и числе степеней свободы
и числе степеней свободы 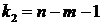 (для остаточной суммы квадратов) и
(для остаточной суммы квадратов) и 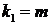 (для факторной суммы квадратов).
(для факторной суммы квадратов).
О качестве нелинейного уравнения регрессии можно также судить и по средней ошибке аппроксимации, которая, так же как и в линейном случае, вычисляется по формуле 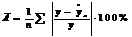
14. Оценка существенности параметров и статистическая проверка гипотез. t-критерий Стьюдента.
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных его параметров. С этой целью по каждому из параметров определяется его стандартная ошибка: mb и ma.
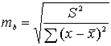 ,
, 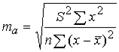 (8.2)
(8.2)
где S2 – остаточная дисперсия на одну степень свободы.
Величина стандартной ошибки совместно с t -распределением Стьюдента при n -2 степенях свободы применяется для проверки существенности коэффициента регрессии.
При гипотезе Н0: b - b0 =0, t -статистика выглядит следующим образом:
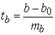
Значение сравнивается с табличным значением при определенном уровне значимости и числе степеней свободы (n -2).
Если фактическое значение t -критерия превышает табличное, то гипотезу о несущественности коэффициента регрессии можно отклонить.
Процедура оценивания существенности параметра а не отличается от уже рассмотренной для коэффициента
15. Взаимосвязь t-статистики и F-статистики для парной регрессии.
Существует связь между 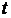 -критерием Стьюдента и -критерием Фишера:
-критерием Стьюдента и -критерием Фишера: 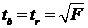 . В прогнозных расчетах по уравнению регрессии определяется предсказываемое
. В прогнозных расчетах по уравнению регрессии определяется предсказываемое 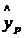 значение как точечный прогноз
значение как точечный прогноз 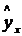 при
при 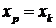 , т.е. путем подстановки в уравнение регрессии
, т.е. путем подстановки в уравнение регрессии 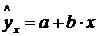 соответствующего значения . Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки , т.е.
соответствующего значения . Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки , т.е. 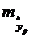 , и соответственно интервальной оценкой прогнозного значения :
, и соответственно интервальной оценкой прогнозного значения :
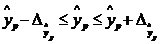 ,
,
где 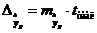 , а
, а 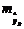 – средняя ошибка прогнозируемого индивидуального значения:
– средняя ошибка прогнозируемого индивидуального значения:
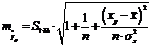 .
.
16. Коэффициент эластичности. Его смысл и определение.
Среди нелинейных моделей наиболее часто используется степенная функция 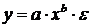 , которая приводится к линейному виду логарифмированием:
, которая приводится к линейному виду логарифмированием:
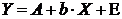 ,
,
где 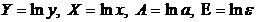 . Т.е. МНК мы применяем для преобразованных данных:
. Т.е. МНК мы применяем для преобразованных данных:
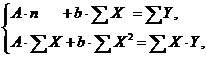
а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр 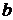 в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности.
в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности.
Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%. Формула для расчета коэффициента эластичности имеет вид:
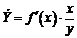 . (1.19)
. (1.19)
Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора , то обычно рассчитывается средний коэффициент эластичности:
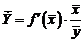 . (1.20)
. (1.20)
Приведем формулы для расчета средних коэффициентов эластичности для наиболее часто используемых типов уравнений регрессии:
17.Оценка статистической значимости уравнения в целом. F-критерий Фишера.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, т. е. регрессией у по х, так и вызванный действием прочих причин (необъясненная вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на результат у. Это равносильно тому, что коэффициент детерминации R2 будет приближаться к единице.
Любая сумма квадратов отклонений связана с числом степеней свободы (df— degrees of freedom), т. е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности N и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из N возможных 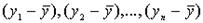 требуется для образования данной суммы квадратов.
требуется для образования данной суммы квадратов.
Так, для общей суммы квадратов 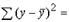 требуется (n -1) независимых отклонений, ибо по совокупности из n единиц после расчета среднего уровня варьируют лишь (n - 1) число отклонений. При расчете факторной суммы квадратов
требуется (n -1) независимых отклонений, ибо по совокупности из n единиц после расчета среднего уровня варьируют лишь (n - 1) число отклонений. При расчете факторной суммы квадратов 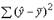 - 1 степень свободы, и при расчете остаточной суммы квадратов
- 1 степень свободы, и при расчете остаточной суммы квадратов 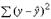 - (n -2) степени свободы.
- (n -2) степени свободы.
Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F – отношения (F - критерий):
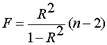 (8.1)
(8.1)
В качестве нулевой гипотезы Н0 выдвигается предположение о том, что линейной зависимости между x и y не существует.
Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для Н0 необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз.
Английским статистиком Снедекором разработаны таблицы критических значений F -отношений при разных уровнях существенности нулевой гипотезы и различном числе степеней свободы.
Табличное значение F -критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F -отношения признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи.
Если же величина окажется меньше табличной, то вероятность нулевой гипотезы выше заданного уровня (например, 0,05) и она не может быть отклонена, без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически незначимым, Н0 не отклоняется.
18. Модель множественной регрессии.
Множественная регрессия – уравнение связи с несколькими независимыми переменными:
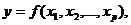
где 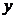 - зависимая переменная (результативный признак);
- зависимая переменная (результативный признак);
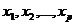 - независимые переменные (факторы).
- независимые переменные (факторы).
Линейная модель множественной регрессии имеет вид:
Yi = α0 + α1 xi 1 + α2 xi 2 +... + α mxim + ε i (4.1)
Коэффициент регрессии α j показывает, на какую величину в среднем изменится результативный признак Y, если переменную xj увеличить на единицу измерения, т.е. α j является нормативным коэффициентом. Обычно предполагается, что случайная величина ε i имеет нормальный закон распределения с математическим ожиданием равным нулю и с дисперсией σ2.
Анализ уравнения (4.1) и методика определения параметров становятся более наглядными, а расчетные процедуры существенно упрощаются, если воспользоваться матричной формой записи уравнения (4.2):
Y = X α + ε (4.2)
где Y — вектор зависимой переменной размерности n ×1, представляющий собой n наблюдений значений yj,
X — матрица n наблюдений независимых переменных Х 1, Х 2, Х 3,..., Хm, размерность матрицы X равна n ×(m +1);
α — подлежащий оцениванию вектор неизвестных параметров размерности (m +1) ×1;
ε — вектор случайных отклонений (возмущений) размерности n ×1.
Таким образом, 
Уравнение (4.1) содержит значения неизвестных параметров α0, α1, α2,..., α m. Эти величины оцениваются на основе выборочных наблюдений, поэтому полученные расчетные показатели не являются истинными, а представляют собой лишь их статистические оценки. Модель линейной регрессии, в которой вместо истинных значений параметров подставлены их оценки (а именно такие регрессии и применяются на практике), имеет вид:
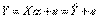 , (4.3)
, (4.3)
где α — вектор оценок параметров; е — вектор «оцененных» отклонений регрессии, остатки регрессии ε = Y - X α; 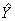 — оценка значений Y, равная Ха.
— оценка значений Y, равная Ха.
Для построения уравнения множественной регрессии чаще используются следующие функции:
 линейная –
линейная – 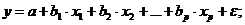
степенная – 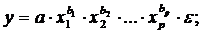

экспонента – 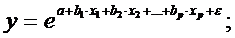
гипербола - 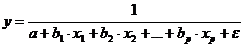 .
.
Можно использовать и другие функции, приводимые к линейному виду.
19. Ограничения модели множественной регрессии.
Предположим, что связь между объясняемой переменной 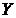 и объясняющими переменными
и объясняющими переменными 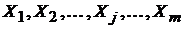 линейная, т.е.
линейная, т.е.
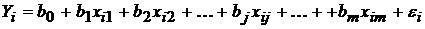 .
.
Пусть выполняются следующие условия:
1) 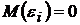 ,
, 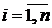 ;
;
2) 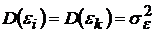 , для любых
, для любых 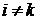 ;
;
3) 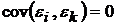 , ,
, ,
4) 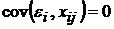 ,
, 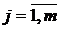 , т.е. распределение
, т.е. распределение 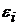 не зависит от распределения любой объясняющей переменной
не зависит от распределения любой объясняющей переменной 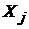 ;
;
5) ошибки имеют нормальный закон распределения, ;
6) 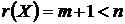 , т.е. ранг матрицы
, т.е. ранг матрицы 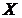 должен быть равен числу оцениваемых параметров
должен быть равен числу оцениваемых параметров 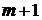 , что означает отсутствие линейной зависимости между объясняющими переменными
, что означает отсутствие линейной зависимости между объясняющими переменными 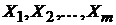 .
.
Тогда МНК-оценка вектора 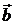 :
: 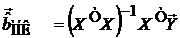 имеет наименьшую дисперсию в классе всех линейных несмещенных и состоятельных оценок.
имеет наименьшую дисперсию в классе всех линейных несмещенных и состоятельных оценок.
Условия Гаусса-Маркова 1)-6) называются предпосылками МНК для случая множественной линейной регрессии

