 2015-10-16
2015-10-16 7978
79781. Значение IQ по шкале Векслера (Л/= 100; а = 15) некоторого тестируемого равно 125. Вопрос о степени выраженности интеллекта у данного индивидуума переформулируем следующим образом: насколько часто или редко встречаются значения IQ ниже или выше 125? Решение. Перейдем от шкалы IQ к единицам
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
стандартного отклонения (г-значениям): г=(125-100)/15= 1,66. По таблице из приложения 1 находим площадь под кривой справа от этого значения, она равна 0,0485. Это значит, что IQ 125 и выше встречается довольно редко — менее, чем в 5% случаев.
2. Какова вероятность того, что случайно выбранный человек будет иметь 1Q по шкале Векслера в диапазоне от 100 до 120? Решение. В единицах стандартного отклонения Zi =0,0; Zi = 1,66. Площадь справа от Z\ —0,5, справа от Zj — примерно 0,0918, следовательно, площадь между Z\ и г2 равна 0,5-0,0918 = 0,4082. Таким образом, вероятность того, что случайно выбранный человек будет иметь IQ в диапазоне от 100 до 120, равна примерно 0,41.
Несмотря на исходный постулат, в соответствии с которым свойства в генеральной совокупности имеют нормальное распределение, реальные данные, полученные на выборке, нечасто распределены нормально. Более того, разработано множество методов, позволяющих анализировать данные без всякого предположения о характере их распределения как в выборке, так и в генеральной совокупности. Эти обстоятельства иногда приводят к ложному убеждению, что нормальное распределение — пустая математическая абстракция, не имеющая отношения к психологии. Тем не менее, как мы увидим в дальнейшем, можно указать по крайней мере на три важных аспекта применения нормального распределения:
1. Разработка тестовых шкал.
2. Проверка нормальности выборочного распределения для принятия ре
шения о том, в какой шкале измерен признак — в метрической или по
рядковой.
3. Статистическая проверка гипотез, в частности — при определении риска
принятия неверного решения.
РАЗРАБОТКА ТЕСТОВЫХ ШКАЛ
Тестовые шкалы разрабатываются для того, чтобы оценить индивидуальный результат тестирования путем сопоставления его с тестовыми нормами, полученными на выборке стандартизации. Выборка стандартизации специально формируется для разработки тестовой шкалы — она должна быть репрезентативна генеральной совокупности, для которой планируется применять данный тест. Впоследствии при тестировании предполагается, что и тестируемый, и выборка стандартизации принадлежат одной и той же генеральной совокупности.
Исходным принципом при разработке тестовой шкалы является предположение о том, что измеряемое свойство распределено в генеральной совокупности в соответствии с нормальным законом. Соответственно, измерение в тестовой шкале данного свойства на выборке стандартизации также должно обеспечивать нормальное распределение. Если это так, то тестовая шкала яв-
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
ляется метрической — точнее, равных интервалов. Если это не так, то свойство удалось отразить в лучшем случае — в шкале порядка. Естественно, что большинство стандартных тестовых шкал являются метрическими, что позволяет более детально интерпретировать результаты тестирования — с учетом свойств нормального распределения — и корректно применять любые методы статистического анализа. Таким образом, основная проблема стандартизации теста заключается в разработке такой шкалы, в которой распределение тестовых показателей на выборке стандартизации соответствовало бы нормальному распределению.
Исходные тестовые оценки — это количество ответов на те или иные вопросы теста, время или количество решенных задач и т. д. Они еще называются первичными, или «сырыми» оценками. Итогом стандартизации являются тестовые нормы — таблица пересчета «сырых» оценок в стандартные тестовые шкалы.
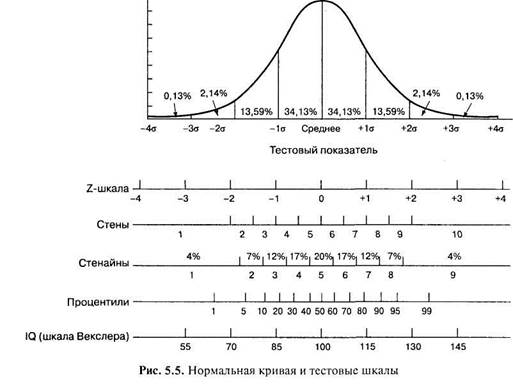 |
Существует множество стандартных тестовых шкал, основное назначение которых — представление индивидуальных результатов тестирования в удобном для интерпретации виде. Некоторые из этих шкал представлены на рис. 5.5. Общим для них является соответствие нормальному распределению, а различаются они только двумя показателями: средним значением и масштабом (стандартным отклонением — о), определяющим дробность шкалы.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
Общая последовательность стандартизации (разработки тестовых норм — таблицы пересчета «сырых» оценок в стандартные тестовые) состоит в следующем:
1) определяется генеральная совокупность, для которой разрабатывается
методика и формируется репрезентативная выборка стандартизации;
2) по результатам применения первичного варианта теста строится рас
пределение «сырых» оценок;
3) проверяют соответствие полученного распределения нормальному за
кону;
4) если распределение «сырых» оценок соответствует нормальному, про
изводится линейная стандартизация;
5) если распределение «сырых» оценок не соответствует нормальному, то
возможны два варианта:
• перед линейной стандартизацией производят эмпирическую норма
лизацию;
• проводят нелинейную нормализацию.
Проверка распределения «сырых» оценок на соответствие нормальному закону производится при помощи специальных критериев, которые мы рассмотрим далее в этой главе.
Линейная стандартизация заключается в том, что определяются границы интервалов «сырых» оценок, соответствующие стандартным тестовым показателям. Эти границы вычисляются путем прибавления к среднему «сырых» оценок (или вычитания из него) долей стандартных отклонений, соответствующих тестовой шкале. Пример, приведенный ниже, демонстрирует процедуру линейной стандартизации.
ПРИМЕР_______________________________________________________________
Предположим, получено распределение «сырых» оценок, соответствующее нормальному, со средним Мх = 22 и стандартным отклонением ох= 6. В качестве стандартной тестовой шкалы выбрана 10-балльная шкала стенов, предложенная Р. Кет-телом {Mst = 5,5; osl = 2). Результатом линейной стандартизации должна являться таблица пересчета из шкалы «сырых» оценок в шкалу стенов. Для этого каждому стандартному значению ставится в соответствие интервал «сырых» оценок. Границы интервалов определяются следующим образом. Среднее «сырых» оценок должно делить шкалу стенов ровно пополам (1—5 — ниже среднего, 6—10 — выше среднего). Следовательно, среднее «сырых» оценок Мх = 22 — это граница стенов 5 и 6. Следующая граница справа — отделяющая стены 6 и 7 — отстоит от среднего на as,/2. Этой границе должна соответствовать граница «сырых» оценок Мх + ох/2 = 22 + 3 = 25. Так же определяются границы всех оставшихся интервалов, а границы крайних интервалов остаются открытыми. Результатом являются тестовые нормы — таблица пересчета «сырых» баллов в стандартные тестовые оценки (табл. 5.1)1.
 1 Обратите внимание, что левая граница каждого диапазона «сырых» оценок исключает границу интервалов, а правая — включает ее. Можно было бы сделать и наоборот, но главное, чтобы границы соседних диапазонов не совпадали, во избежание недоразумений при попадании индивидуального значения на границу интервалов.
1 Обратите внимание, что левая граница каждого диапазона «сырых» оценок исключает границу интервалов, а правая — включает ее. Можно было бы сделать и наоборот, но главное, чтобы границы соседних диапазонов не совпадали, во избежание недоразумений при попадании индивидуального значения на границу интервалов.
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
Табл ица 5.1 Тестовые нормы — таблица пересчета «сырых» баллов в стены
| Стены | ||||||||||
| «Сырые» баллы | <11 | 11-13 | 14-16 | 17-19 | 20-22 | 23-25 | 26-28 | 29-31 | 32-34 | >34 |
Пользуясь этой таблицей тестовых норм индивидуальный результат («сырой» балл) переводят в шкалу стенов, что позволяет интерпретировать выраженность измеряемого свойства.
В общем случае границы интервалов определяются по формуле г-преоб-разования:
K/f с/.— A/f /т
| о\ |
z = -
о\
где Xj — искомая граница интервала «сырых» оценок, stt — граница интервала в стандартной тестовой шкале, Мх, ох, Msh osl — средние и стандартные отклонения «сырых» оценок (х) и стандартной шкалы (st).
Эмпирическая нормализация применяется, когда распределение «сырых» баллов отличается от нормального. Она заключается в изменении содержания тестовых заданий. Например, если «сырая» оценка — это количество задач, решенных испытуемыми за отведенное время, и получено распределение с правосторонней асимметрией, то это значит, что слишком большая доля испытуемых решает больше половины заданий. В этом случае необходимо либо добавить более трудные задания, либо сократить время решения.
Нелинейная нормализация применяется, если эмпирическая нормализация невозможна или нежелательна, например, с точки зрения затрат времени и ресурсов. В этом случае перевод «сырых» оценок в стандартные производится через нахождение процентильных границ групп в исходном распределении, соответствующих процентильным границам групп в нормальном распределении стандартной шкалы. Каждому интервалу стандартной шкалы ставится в соответствие такой интервал шкалы «сырых» оценок, который содержит ту же процентную долю выборки стандартизации. Величины долей определяются по площади под единичной нормальной кривой, заключенной между соответствующими данному интервалу стандартной шкалы г-оценками.
Например, для того чтобы определить, какой «сырой» балл должен соответствовать нижней границе стена 10, необходимо сначала выяснить, какому г-значению соответствует эта граница (z = 2). Затем по таблице нормального распределения (приложение 1) надо определить, какая доля площади под нормальной кривой находится правее этого значения (0,023). После этого определяется, какое значение отсекает 2,3% наибольших значений «сырых» баллов выборки стандартизации. Найденное значение и будет соответствовать границе 9 и 10 стена.
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
ПРИМЕР
 Рассмотрим пример нелинейной нормализации. Допустим, разрабатываемый тест предполагает решение 20 заданий. Объем выборки стандартизации N= 200 человек. Сначала строится таблица распределения частот «сырых» оценок (табл. 5.2).
Рассмотрим пример нелинейной нормализации. Допустим, разрабатываемый тест предполагает решение 20 заданий. Объем выборки стандартизации N= 200 человек. Сначала строится таблица распределения частот «сырых» оценок (табл. 5.2).
Таб л и ца 5.2
| Таблица распределения частот | «сырыхх | » оценок | |||||||||||||||||
| Оценка | |||||||||||||||||||
| Частота |
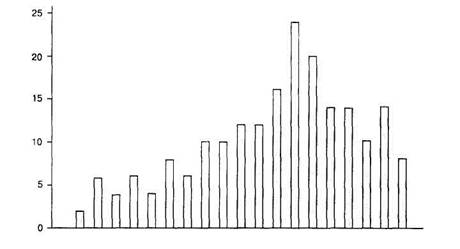
Исходное распределение заметно отличается от нормального — оно имеет правостороннюю асимметрию (рис. 5.6). В качестве стандартной выберем шкалу стенай-нов, для каждой градации которой известны процентные доли (см. рис. 5.5). Исходя из этих процентных долей и таблицы распределения «сырых» оценок строится таблица тестовых норм (табл. 5.3). Сначала отбираются 4% испытуемых, решивших наименьшее количество заданий. У нас 8 испытуемых (4%) решили менее 4 заданий. Это число заданий будет соответствовать 1 -му стенайну. Второму стенайну будет соответствовать результат следующих 7% (14) испытуемых: от 4 до 6 заданий, и т. д. Итог нелинейной стандартизации — таблица перевода «сырых» оценок в шкальные, стенайны (табл. 5.3).
Табл и ца 5.3 Пример нелинейной нормализации: пересчет «сырых» оценок в шкалу стенайнов
| Стенайны | |||||||||
| % | |||||||||
| «Сырые» оценки | <4 | 4-6 | 7-9 | 10-12 | 13-14 | 15-16 | 17-18 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Рис. 5.6. Распределение «сырых» оценок (по данным табл. 5.2)
Изложенные основы психодиагностики позволяют сформулировать математически обоснованные требования к тесту. Тестовая методика должна содержать:
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
□ описание выборки стандартизации;
□ характеристику распределения «сырых» баллов с указанием среднего и
стандартного отклонения;
□ наименование, характеристику стандартной шкалы;
□ тестовые нормы — таблицы пересчета «сырых» баллов в шкальные.
ПРОВЕРКА НОРМАЛЬНОСТИ РАСПРЕДЕЛЕНИЯ
Для проверки нормальности используются различные процедуры, позволяющие выяснить, отличается ли от нормального выборочное распределение измеренной переменной. Необходимость такого сопоставления возникает, когда мы сомневаемся в том, в какой шкале представлен признак — в порядковой или метрической. А сомнения такие возникают очень часто, так как заранее нам, как правило, не известно, в какой шкале удастся измерить изучаемое свойство (исключая, конечно, случаи явно номинативного измерения).
Важность определения того, в какой шкале измерен признак, трудно переоценить, по крайней мере, по двум причинам. От этого зависит, во-первых, полнота учета исходной эмпирической информации (в частности, об индивидуальных различиях), во-вторых, доступность многих методов анализа данных. Если исследователь принимает решение об измерении в порядковой шкале, то неизбежное последующее ранжирование ведет к потере части исходной информации о различиях между испытуемыми, изучаемыми группами, о взаимосвязях между признаками и т. д. Кроме того, метрические данные позволяют использовать значительно более широкий набор методов анализа и, как следствие, сделать выводы исследования более глубокими и содержательными.
Наиболее весомым аргументом в пользу того, что признак измерен в метрической шкале, является соответствие выборочного распределения нормальному. Это является следствием закона нормального распределения. Если выборочное распределение не отличается от нормального, то это значит, что измеряемое свойство удалось отразить в метрической шкале (обычно — интервальной).
Существует множество различных способов проверки нормальности, из которых мы кратко опишем лишь некоторые, предполагая, что эти проверки читатель будет производить при помощи компьютерных программ.
Графический способ (Q-Q Plots, Р-Р Plots). Строят либо квантильные графики, либо графики накопленных частот. Квантильные графики (Q-Q Plots) строятся следующим образом. Сначала определяются эмпирические значения изучаемого признака, соответствующие 5, 10,..., 95-процентилю. Затем по таблице нормального распределения для каждого из этих процентилей определяются z-значения (теоретические). Два полученных ряда чисел задают координаты точек на графике: эмпирические значения признака от-
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
кладываются на оси абсцисс, а соответствующие им теоретические значения — на оси ординат. Для нормального распределения все точки будут лежать на одной прямой или рядом с ней. Чем больше расстояние от точек до прямой линии, тем меньше распределение соответствует нормальному. Графики накопленных частот (Р-Р Plots) строятся подобным образом. На оси абсцисс через равные интервалы откладываются значения накопленных относительных частот, например 0,05; 0,1;...; 0,95. Далее определяются эмпирические значения изучаемого признака, соответствующие каждому значению накопленной частоты, которые пересчитываются в z-значения. По таблице нормального распределения определяются теоретические накопленные частоты (площадь под кривой) для каждого из вычисленных г-зна-чений, которые откладываются на оси ординат. Если распределение соответствует нормальному, полученные на графике точки лежат на одной прямой.
Критерии асимметрии и эксцесса. Эти критерии определяют допустимую степень отклонения эмпирических значений асимметрии и эксцесса от нулевых значений, соответствующих нормальному распределению. Допустимая степень отклонения — та, которая позволяет считать, что эти статистики существенно не отличаются от нормальных параметров. Величина допустимых отклонений определяется так называемыми стандартными ошибками асимметрии и эксцесса. Для формулы асимметрии (4.10) стандартная ошибка определяются по формуле:
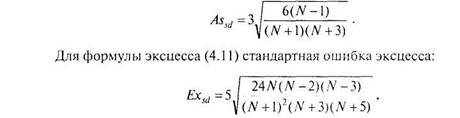 |
где N — объем выборки.
Выборочные значения асимметрии и эксцесса значительно отличаются от нуля, если не превышают значения своих стандартных ошибок. Это можно считать признаком соответствия выборочного распределения нормальному закону. Следует отметить, что компьютерные программы вычисляют показатели асимметрии, эксцесса и соответствующие им стандартные ошибки по другим, более сложным формулам.
Статистический критерий нормальности Колмогорова-Смирнова считается наиболее состоятельным для определения степени соответствия эмпирического распределения нормальному. Он позволяет оценить вероятность того, что данная выборка принадлежит генеральной совокупности с нормальным распределением. Если эта вероятность р< 0,05, то данное эмпирическое распределение существенно отличается от нормального, а если р > 0,05, то делают вывод о приблизительном соответствии данного эмпирического распределения нормальному.
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
Причины отклонения от нормальности. Общей причиной отклонения формы выборочного распределения признака от нормального вида чаще всего является особенность процедуры измерения: используемая шкала может обладать неравномерной чувствительностью к измеряемому свойству в разных частях диапазона его изменчивости.
ПРИМЕР
 Предположим, выраженность некоторой способности определяется количеством выполненных заданий за отведенное время. Если задания простые или время слишком велико, то данная измерительная процедура будет обладать достаточной чувствительностью лишь в отношении части испытуемых, для которых эти задания достаточно трудны. И слишком большая доля испытуемых будет решать все или почти все задания. В итоге мы получим распределение с выраженной правосторонней асимметрией. Можно, конечно, впоследствии повысить качество измерения путем эмпирической нормализации, добавив более сложные задания или сократив время выполнения данного набора заданий. Если же мы чрезмерно усложним измерительную процедуру, то возникнет обратная ситуация, когда большая часть испытуемых будет решать малое количество заданий и эмпирическое распределение приобретет левостороннюю асимметрию.
Предположим, выраженность некоторой способности определяется количеством выполненных заданий за отведенное время. Если задания простые или время слишком велико, то данная измерительная процедура будет обладать достаточной чувствительностью лишь в отношении части испытуемых, для которых эти задания достаточно трудны. И слишком большая доля испытуемых будет решать все или почти все задания. В итоге мы получим распределение с выраженной правосторонней асимметрией. Можно, конечно, впоследствии повысить качество измерения путем эмпирической нормализации, добавив более сложные задания или сократив время выполнения данного набора заданий. Если же мы чрезмерно усложним измерительную процедуру, то возникнет обратная ситуация, когда большая часть испытуемых будет решать малое количество заданий и эмпирическое распределение приобретет левостороннюю асимметрию.
Таким образом, такие отклонения от нормального вида, как право- или левосторонняя асимметрия или слишком большой эксцесс (больше 0), связаны с относительно низкой чувствительностью измерительной процедуры в области моды (вершины графика распределения частот).
Последствия отклонения от нормальности. Следует отметить, что задача получения эмпирического распределения, строго соответствующего нормальному закону, нечасто встречается в практике исследования. Обычно такие случаи ограничиваются разработкой новой измерительной процедуры или тестовой шкалы, когда применяется эмпирическая или нелинейная нормализация для «исправления» эмпирического распределения. В большинстве случаев соответствие или несоответствие нормальности является тем свойством измеренного признака, который исследователь должен учитывать при выборе статистических процедур анализа данных.
| Заметно ли "на глаз" отличие распределения от нормального вида? |
| X |
 В общем случае при значительном отклонении эмпирического распределения от нормального следует отказаться от предположения о том, что признак измерен в метрической шкале. Но остается открытым вопрос о том, какова мера существенности этого отклонения? Кроме того, разные методы анализа данных обладают различной чувствительностью к отклонениям от нормальности. Обычно при обосновании перспективности этой проблемы приводят принцип Р. Фишера, одного из «отцов-основателей» современной статистики: «Отклонения от нормально-
В общем случае при значительном отклонении эмпирического распределения от нормального следует отказаться от предположения о том, что признак измерен в метрической шкале. Но остается открытым вопрос о том, какова мера существенности этого отклонения? Кроме того, разные методы анализа данных обладают различной чувствительностью к отклонениям от нормальности. Обычно при обосновании перспективности этой проблемы приводят принцип Р. Фишера, одного из «отцов-основателей» современной статистики: «Отклонения от нормально-
ЧАСТЬ I. ОСНОВЫ ИЗМЕРЕНИЯ И КОЛИЧЕСТВЕННОГО ОПИСАНИЯ ДАННЫХ
го вида, если только они не слишком заметны, можно обнаружить лишь для больших выборок; сами по себе они вносят малое отличие в статистические критерии и другие вопросы»1. К примеру, при малых, но обычных для психологических исследований выборках (до 50 человек) критерий Колмогорова-Смирнова недостаточно чувствителен при определении даже весьма заметных «на глаз» отклонений от нормальности. В то же время некоторые процедуры анализа метрических данных вполне допускают отклонения от нормального распределения (одни — в большей степени, другие — в меньшей). В дальнейшем при изложении материала мы при необходимости будем оговаривать меру жесткости требования нормальности.
Задачи и упражнения
1. Некоторое свойство измеряется при помощи тестовой шкалы СЕЕВ
(Л/=500, о= 100). Какая приблизительно доля генеральной совокупно
сти имеет балл от 600 до 700?
2. В генеральной совокупности значения IQ в шкале Векслера распределе
ны приблизительно нормально со средним 100 и стандартным отклоне
нием 15. С помощью таблиц определите следующие вероятности:
а) вероятность того, что случайно выбранный человек будет иметь IQ
между 79 и 121;
б) вероятность того, что случайно выбранный человек будет иметь IQ
выше 127; ниже 73.
3. Определите при помощи квантильного графика, соответствует ли нор
мальному виду распределение переменной со следующими значениями
процентилей:

В области каких значений шкала, в которой измерен признак, обладает большей дифференцирующей способностью (чувствительностью), а в какой — меньшей?
ОБРАБОТКА НА КОМПЬЮТЕРЕ
Критерии асимметрии и эксцесса. Выбираем Analyze > Descriptive Statistics > Descriptives... В окне диалога переносим из левого окна в правое интересующие нас переменные. Нажимаем кнопку Options..., ставим флажок Distribution >
 1 Цит. по: Справочник по прикладной статистике: В 2 т. / Под ред. Э. Ллойда, У. Ледермана. М., 1989. Т. 1.С. 270.
1 Цит. по: Справочник по прикладной статистике: В 2 т. / Под ред. Э. Ллойда, У. Ледермана. М., 1989. Т. 1.С. 270.
ГЛАВА 5. НОРМАЛЬНЫЙ ЗАКОН РАСПРЕДЕЛЕНИЯ И ЕГО ПРИМЕНЕНИЕ
Kurtosis, Skewness, нажимаем Continue, затем ОК. В таблице результатов столбцы Kurtosis и Skewness содержат значения асимметрии (Kurtosis) и эксцесса (Skewness) и соответствующие им стандартные ошибки (Std. Error). Распределение соответствует нормальному виду, если для соответствующей переменной абсолютные значения асимметрии и эксцесса не превышают свои стандартные ошибки.
Графический способ. Выбираем Graphs > РР... — графики накопленных частот (или Graphs > QQ... — квантильные графики). Открывается диалог Р-Р Plots (Q-Q Plots). Переносим из левого в правое окно интересующие нас переменные. Нажимаем ОК. В окне результатов просматриваем графики Normal Р-Р Plot... (Normal Q-Q Plot...), на которых по горизонтальной оси отложены соответствующие эмпирические значения, а по вертикальной оси — теоретические значения. Чем ближе точки графиков к прямой линии, тем меньше отличие распределения от нормального вида.
Критерий нормальности Колмогорова-Смирнова. Выбираем Analyze > Nonpa-rametric Tests > 1-Sample K-S... Открывается диалог One-Sample Kolmogorov-Smirnov Test. Переносим из левого в правое окно интересующие нас переменные. Нажимаем ОК. В соответствующем переменной столбце находим Kolmogorov-SmirnovZ (значение критерия) и Asymp. Sig. (2-tailed) (вероятность того, что распределение соответствует нормальному виду). Если значение Asymp. Sig. меньше или равно 0,05, то распределение существенно отличается от нормального вида. Если Asymp. Sig. больше 0,05, то существенного отличия от нормальности не обнаружено.
Глава 6








