 2014-02-02
2014-02-02 6535
6535Примечание
Классификация по способу организации
Классификация по технологии обработки данных и способу доступа к данным
Классификация по сфере применения
Корпоративные информационные системы
Групповые информационные системы
Групповые информационные системы ориентированы на коллективное использование информации членами рабочей группы и чаще всего строятся на базе локальной вычислительной сети. При разработке таких приложений используются серверы баз данных (называемые также SQL-серверами) для рабочих групп. Существует довольно большое количество различных SQL-серверов, как коммерческих, так и свободно распространяемых. Среди них наиболее известны такие серверы баз данных, как Oracle, DB2, Microsoft SQL Server, InterBase, Sybase, Informix.
Корпоративные информационные системы являются развитием систем для рабочих групп, они ориентированы на крупные компании и могут поддерживать территориально разнесенные узлы или сети. Корпоративная (интегрированная)ИС автоматизирует все функции управления на всех уровнях управления. Такая ИС является многопользовательской, функционирует в распределенной вычислительной сети.
В основном они имеют иерархическую структуру из нескольких уровней. Для таких систем характерна архитектура клиент-сервер со специализацией серверов или же многоуровневая архитектура. При разработке таких систем могут использоваться те же серверы баз данных, что и при разработке групповых информационных систем. Однако в крупных информационных системах наибольшее распространение получили серверы Oracle, DB2 и Microsoft SQL Server.
Для групповых и корпоративных систем существенно повышаются требования к надежности функционирования и сохранности данных. Эти свойства обеспечиваются поддержкой целостности данных, ссылок и транзакций в серверах баз данных.
По сфере применения информационные системы обычно подразделяются на четыре группы (рисунок 2):
· системы обработки транзакций;
· системы поддержки принятия решений;
· информационно-справочные системы;
· офисные информационные системы.
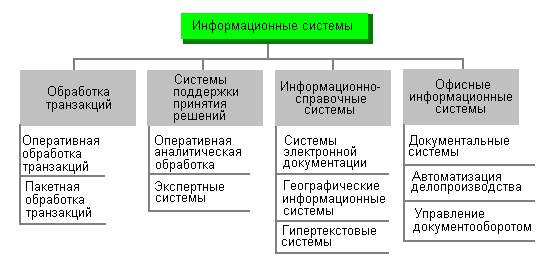
Рисунок 2 - Деление информационных систем по сфере применения
Системы обработки транзакций, в свою очередь, по оперативности обработки данных, разделяются на пакетные информационные системы и оперативные информационные системы.
Логической единицей функционирования систем операционной обработки данных является транзакция. Управление транзакциями необходимо для поддержания логической целостности базы данных. Поддержка механизма транзакций является обязательным условием даже однопользовательских, а тем более для многопользовательских СУБД. То свойство, что каждая транзакция начинается при целостном состоянии базы данных и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к базе данных. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый из пользователей может, в принципе, ощущать себя единственным пользователем СУБД.
| Транзакцией называется последовательность операций над базой данных, рассматриваемых СУБД как единое целое. |
Например, транзакция может состоять из операций чтения, удаления, вставки и модификации данных.
Если все операции успешно выполнены, то транзакция также считается успешно выполненной и СУБД фиксирует (COMMIT) все изменения данных, произведенные этой транзакцией (то есть заносит изменения во внешнюю память). Если же хотя бы одна операция транзакции заканчивается неудачей, то транзакция считается невыполненной и производится откат (ROLLBACK) — отмена всех изменений данных, произведенных в ходе выполнения транзакции, и возврат базы данных к состоянию до начала выполнения транзакции.
Чтобы использование механизмов обработки транзакций позволило обеспечить целостность данных и изолированность пользователей, транзакции должны обладать четырьмя основными свойствами:
1 a tomicity - атомарности – транзакция выполняется как единая операция доступа к базе данных (должны быть выполнены все операции манипулирования данными, входящие в транзакцию, или ни одна операция не должна выполняться совсем);
2 c onsistency - согласованности – гарантия взаимной целостности данных (т.е. выполнение ограничений целостности базы данных после окончания транзакции);
3 i solation - изолированности – гарантия того, что транзакции в многопользовательской системе с одной базой данных будут выполняться отдельно друг от друга, если они изменяют одни и те же данные;
4 d urability - долговечности – если транзакция выполнена успешно, то произведенные ею изменения не будут потеряны ни при каких обстоятельствах.
Транзакции, обладающие четырьмя перечисленными свойствами, по первым буквам их английских названий, называют ACID -транзакциями.
В информационных системах организационного управления преобладает режим оперативной обработки транзакций — OLTP (On-Line Transaction Processing), для отражения актуального состояния предметной области в любой момент времени, а пакетная обработка занимает весьма ограниченную часть. Для систем OLTP характерен регулярный (возможно, интенсивный) поток довольно простых транзакций, играющих роль заказов, платежей, запросов и т. п. Важными требованиями для них являются:
- высокая производительность обработки транзакций;
- гарантированная доставка информации при удаленном доступе к БД по телекоммуникациям.
Системы поддержки принятия решений — DSS (Decision Support System) — представляют собой другой тип информационных систем, в которых с помощью довольно сложных запросов производится отбор и анализ данных в различных разрезах: временных, географических и по другим показателям.
Системы оперативной аналитической обработки OLAP (On-Line Analysis Processing) ориентированы на выполнение более сложных, чем системы OLTP, запросов, требующих статистической обработки накопленных за некоторый промежуток времени (исторических) данных, моделирования процессов предметной области, прогнозирования развития явлений. Такие системы часто включают средства обработки информации на основе методов искусственного интеллекта (ИИ), средств графического представления данных, оперируют большими объемами исторических данных, позволяя выделить из них содержательную информацию - получить знания из данных.
Пример. Типы выполняемых запросов:
- в OLTP-системе продажи железнодорожных билетов – «Есть ли свободные места в купе поезда Москва-Кисловодск, отправляющегося 20 августа в 23.15?»
- в OLAP-системе запрос может быть таким: «Каков будет объем продажи железнодорожных билетов в денежном выражении в следующие 3 месяца с учетом сезонных колебаний?»
Экспертные системы (ЭС) – это системы искусственного интеллекта, предназначенные для моделирования логики эксперта в некоторой предметной области для оказания новичкам высокопрофессиональной помощи специалиста. В состав ЭС входят, кроме базы данных, еще база знаний (БЗ) и механизм логического вывода, позволяющий получать советы экспертной системы, основанные на хранящихся в БЗ знаниях экспертов.
Обширный класс информационно-справочных систем основан на гипертекстовых документах и мультимедиа. Наибольшее развитие такие информационные системы получили в сети Интернет.
Класс офисных информационных систем нацелен па перевод бумажных документов в электронный вид, автоматизацию делопроизводства и управление документооборотом.
ПРИМЕЧАНИЕ. Следует отметить, что приводимая классификация по сфере применения в достаточной степени условна. Крупные информационные системы очень часто обладают признаками всех перечисленных выше классов. Кроме того, корпоративные информационные системы масштаба предприятия обычно состоят из ряда подсистем, относящихся к различным сферам применения.
По технологии обработки данных в БД информационные системы подразделяются на
- централизованные
- распределенные
Централизованная БД хранится в памяти одной вычислительной системы. Если эта вычислительная система является компонентом сети ЭВМ, возможен распределенный доступ к такой базе. Такой способ использования БД часто применяют в локальных сетях персональных компьютеров (ПК).
Распределенная БД состоит из нескольких, возможно пересекающихся или даже дублирующих друг друга частей, хранимых в различных ЭВМ вычислительной сети. Работа с такой базой осуществляется с помощью системы управления распределенной БД (СУРБД).
По способу доступа к данным БД бывают
- с локальным доступом
- с удаленным (сетевым) доступом.
По способу организации групповые и корпоративные информационные системы подразделяются на следующие классы (рисунок 3):
- системы на основе архитектуры файл-сервер;
- системы на основе архитектуры клиент-сервер;
- системы на основе многоуровневой архитектуры;
- системы на основе Интернет/интранет-технологий.
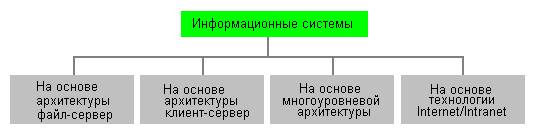
Рисунок 3 - Деление информационных систем по способу организации
В любой информационной системе можно выделить необходимые функциональные компоненты (таблица 1), которые помогают понять ограничения различных архитектур информационных систем. Рассмотрим более подробно особенности вариантов построения информационных приложений.
Таблица 1 - Типовые функциональные компоненты информационной системы
| Обозначение | Наименование | Характеристика |
| PS | Presentation Services (средства представления) | Обеспечиваются устройствами, принимающими ввод от пользователя и отображающими то, что сообщает ему компонент логики представления PL, с использованием соответствующей программной поддержки |
| PL | Presentation Logic (логика представления) | Управляет взаимодействием между пользователем и ЭВМ. Обрабатывает действия пользователя при выборе команды в меню, нажатии кнопки или выборе элемента из списка |
| BL | Business orApplication Logic (прикладная логика) | Набор правил для принятия решений, вычислений и операций, которые должно выполнить приложение |
| DL | Data Logic (логика управления данными) | Операции с базой данных (SQL-операторы), которые нужно выполнить для реализации прикладной логики управления данными |
| DS | Data Services (операции с базой данных) | Действия СУБД, вызываемые для выполнения логики управления данными, такие как манипулирование данными, определения данных, фиксация или откат транзакций и т. п. СУБД обычно компилирует SQL-предложения |
| FS | File Services (файловые операции) | Дисковые операции чтения и записи данных для СУБД и других компонентов. Обычно являются функциями операционной системы (ОС) |
Архитектура файл-сервер не имеет сетевого разделения компонентов диалога PS и PL и использует компьютер для функций отображения, что облегчает построение графического интерфейса. Файл-сервер только извлекает данные из файлов, так что дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный процессор. Каждый новый клиент добавляет вычислительную мощность к сети.
Объектами разработки в файл-серверном приложении являются компоненты приложения, определяющие логику диалога PL, а также логику обработки BL и управления данными DL. Разработанное приложение реализуется либо в виде законченного загрузочного модуля, либо в виде специального кода для интерпретации.
В файл-серверных СУБД все данные обычно размещаются в одном или нескольких каталогах достаточно мощной машины, специально выделенной для этих целей и постоянно подключенной к сети. Такой компьютер называют файл-сервером. Между локальными и файл-серверными вариантами СУБД нет особых различий, т.к. в них все части собственно СУБД (кроме данных) находятся на компьютере клиента. По архитектуре они обычно одноуровневые (рисунок 4).
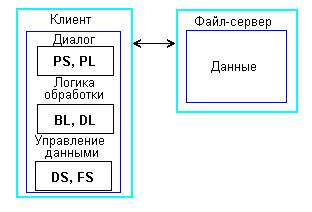
Рисунок 4 – Одноуровневая архитектура файл-сервер
Однако такая архитектура имеет существенный недостаток: при выполнении некоторых запросов к базе данных клиенту могут передаваться большие объемы данных, загружая сеть и приводя к непредсказуемости времени реакции. Значительный сетевой трафик особенно сильно сказывается при организации удаленного доступа к базам данных на файл-сервере через низкоскоростные каналы связи.
Пример. Если необходимо отыскать сведения об одной из фирм-партнеров в некоторой ИС, по сети вначале передается весь файл, содержащий сведения о многих сотнях партнеров, и лишь затем в созданной таким образом локальной копии данных отыскивается нужная запись. При интенсивной работе с данными уже нескольких десятков клиентов пропускная способность сети может оказаться недостаточной, и пользователя будут раздражать задержки в реакции СУБД на его требования.
Одним из вариантов устранения данного недостатка является удаленное управление файл-серверным приложением в сети. При этом в локальной сети размещается сервер приложений (рисунок 5), совмещенный с телекоммуникационным сервером (обычно называемым сервером доступа), в среде которого выполняются обычные файл-серверные приложения. Особенность состоит в том, что диалоговый ввод-вывод поступает от удаленных клиентов через телекоммуникации. Приложения не должны быть слишком сложными, иначе велика вероятность перегрузки сервера, или же нужна очень мощная платформа для сервера приложений.
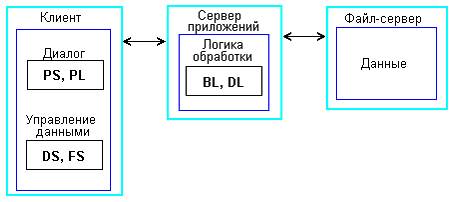
Рисунок 5 – Использование сервера приложений совместно с одноуровневой файл-серверной архитектурой
Одним из традиционных средств, на основе которых создаются файл-серверные системы, являются локальные СУБД. Однако такие системы, как правило, ни отвечают требованиям обеспечения целостности данных (в частности, они не поддерживают транзакции). Поэтому при их использовании задача обеспечения целостности данных возлагается на программы клиентов, что приводит к усложнению клиентских приложений. Однако эти инструменты привлекают своей простотой, удобством использования и доступностью. Поэтому файл-серверные информационные системы до сих пор представляют интерес для малых рабочих групп и, более того, нередко используются в качестве информационных систем масштаба предприятия.
Архитектура клиент-сервер предназначена для разрешения проблем файл-серверных приложений путем разделения компонентов приложения и размещения их там, где они будут функционировать наиболее эффективно. Особенностью архитектуры клиент-сервер является использование выделенных серверов баз данных, понимающих запросы на языке структурированных запросов SQL (Structured Query Language) и выполняющих поиск, сортировку и агрегирование информации.
Отличительная черта серверов БД — наличие справочника данных, в котором записана структура БД, ограничения целостности данных, форматы и даже серверные процедуры обработки данных по вызову или по событиям в программе. Объектами разработки в таких приложениях помимо диалога и логики обработки являются, прежде всего, реляционная модель данных и связанный с ней набор SQL-операторов для типовых запросов к базе данных.
Большинство конфигураций клиент-сервер использует двухуровневую модель, в которой клиент обращается к услугам сервера. Предполагается, что диалоговые компоненты PS и PL размещаются на клиенте, что позволяет обеспечить графический интерфейс. Компоненты управления данными DS и FS размещаются на сервере, а диалог (PS, PL),логика BL и DL — на клиенте. Двухуровневое определение архитектуры клиент-сервер использует именно этот вариант: приложение работает у клиента, СУБД — на сервере (рисунок 6).
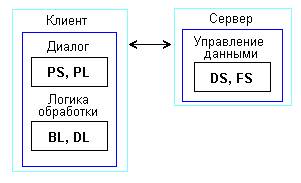
Рисунок 6 - Классический вариант клиент-серверной информационной системы
Поскольку эта схема предъявляет наименьшие требования к серверу, она обладает наилучшей масштабируемостью. Однако сложные приложения, вызывающие большое взаимодействие с БД, могут жестко загрузить как клиента, так и сеть. Результаты SQL-запроса должны вернуться клиенту для обработки, потому что там находится логика принятия решения. Такая схема приводит к дополнительному усложнению администрирования приложений, разбросанных по раз личным клиентским узлам.
Для сокращения нагрузки на сеть и упрощения администрирования приложений компонент BL можно разместить на сервере. При этом вся логика принятия решений оформляется в виде хранимых процедур и выполняется на сервере БД.
Хранимая процедура — процедура с операторами SQL для доступа к БД, вызываемая по имени с передачей требуемых параметров и выполняемая па сервере БД. Хранимые процедуры могут компилироваться, что повышает скорость их выполнения и сокращает нагрузку на сервер.
Хранимые процедуры улучшают целостность приложений и БД, гарантируют актуальность коллективно используемых операций и вычислений. Улучшается сопровождение таких процедур, а также безопасность (нет прямого доступа к данным).
Следует помнить, что перегрузка хранимых процедур прикладной логикой может перегрузить сервер, что приведет к потере производительности. Эта проблема особенно актуальна при разработке крупных информационных систем, в которых к серверу может одновременно обращаться большое количество клиентов. Поэтому в большинстве случаев следует принимать компромиссные решения: часть логики приложения размещать на стороне сервера, часть — на стороне клиента. Такие клиент-серверные системы называются системами с разделенной логикой. Данная схема при удачном разделении логики позволяет получить более сбалансированную загрузку клиентов и сервера, но при этом затрудняется сопровождение приложений.
Создание архитектуры клиент-сервер возможно и на основе многотерминальной системы. В этом случае в многозадачной среде сервера приложений выполняются программы пользователей, а клиентские узлы вырождены и представлены терминалами. Подобная схема информационной системы характерна для UNIX.
Архитектура клиент-сервер может использоваться как в сети с выделенным сервером, так и
в одноранговых локальных вычислительных сетях. В последнем случае каждая рабочая станция сети может выполнять одновременно функции клиента и функции сервера, т.е. обслуживать и направлять запросы.
К преимуществам сети с выделенным сервером относятся надежная система защиты информации, высокое быстродействие, отсутствие ограничений на число рабочих станций, простота управления, к недостаткам – высокая стоимость (из-за выделения одного компьютера под сервер), зависимость быстродействия и надежности сети от сервера, меньшая гибкость, чем в одноранговых сетях.
К преимуществам одноранговых сетей можно отнести низкую стоимость, высокую надежность, к недостаткам – зависимость эффективности работы от количества станций, сложность управления и обеспечения защиты информации, трудности обновления и изменения программного обеспечения станций.
В настоящее время архитектура клиент-сервер получила признание и широкое распространение как способ организации приложений для рабочих групп и информационных систем корпоративного уровня. Подобная организация работы повышает эффективность выполнения приложений за счет использования возможностей сервера БД, разгрузки сети и обеспечения контроля целостности данных.
Двухуровневые схемы архитектуры клиент-сервер могут привести к некоторым проблемам в сложных информационных приложениях с множеством пользователей и запутанной логикой. Решением этих проблем может стать использование многоуровневой архитектуры.
4.3. Многоуровневая архитектура
Многоуровневая архитектура стала развитием архитектуры клиент-сервер и в своей классической форме состоит из трех уровней (рисунок.7):
- нижний уровень представляет собой приложения клиентов, выделенные для выполнения функций и логики представлений PS и PL и имеющие программный интерфейс для вызова приложения на среднем уровне;
- средний уровень представляет собой сервер приложений, на котором выполняется прикладная логика BL и с которого логика обработки данных DL вызывает операции с базой данных DS;
- верхний уровень представляет собой удаленный специализированный сервер базы данных, выделенный для услуг обработки данных DS и файловых операций FS (без риска использования хранимых процедур).
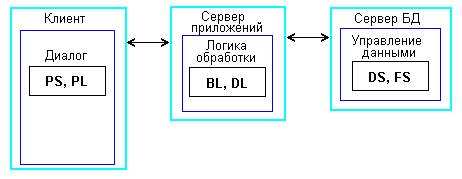
Рисунок 7 – Трехуровневая архитектура клиент-сервер
Подобную концепцию обработки данных пропагандируют, в частности, фирмы Oracle, Sun, Borland и др.
Трехуровневая архитектура позволяет еще больше сбалансировать нагрузку на разные узлы и сеть, а также способствует специализации инструментов для разработки приложений и устраняет недостатки двухуровневой модели клиент-сервер.
Централизация логики приложения упрощает администрирование и сопровождение. Четко разделяются платформы и инструменты для реализации интерфейса и прикладной логики, что позволяет с наибольшей отдачей реализовывать их специалистам узкого профиля. Наконец, изменения прикладной логики не затрагивают интерфейса, и наоборот. Но поскольку границы между компонентами PL, BL и DL размыты, прикладная логика может появиться на всех трех уровнях. Сервер приложений с помощью монитора транзакций обеспечивает интерфейс с клиентами и другими серверами, может управлять транзакциями и гарантировать целостность распределенной базы данных. Средства удаленного вызова процедур наиболее соответствуют идее распределенных вычислений; они обеспечивают из любого узла сети вызов прикладной процедуры, расположенной на другом узле, передачу параметров, удаленную обработку и возврат результатов. С ростом систем клиент-сервер необходимость трех уровней становится все более очевидной. Продукты для трехзвенной архитектуры, так называемые мониторы транзакций, являются относительно новыми. Эти инструменты в основном ориентированы па среду UNIX, однако прикладные серверы можно строить на базе Microsoft Windows NT с использованием вызова удаленных процедур для организации связи клиентов с сервером приложений. На практике в локальной сети могут использоваться смешанные архитектуры (двухуровневые и трехуровневые) с одним и тем же сервером базы данных. С учетом глобальных связей архитектура может иметь больше трех звеньев. В настоящее время появились новые инструментальные средства для гибкой сегментации приложений клиент-сервер по различным узлам сети.
Таким образом, многоуровневая архитектура распределенных приложений позволяет повысить эффективность работы корпоративной информационной системы и оптимизировать распределение ее программно-аппаратных ресурсов. Но пока на российском рынке по-прежнему доминирует архитектура клиент-сервер.
4.4 Интернет/интранет-технологии
В развитии технологии Интернет/интранет основной акцент пока что делается на разработке инструментальных программных средств. В то же время наблюдается отсутствие развитых средств разработки приложений, работающих с базами данных. Компромиссным решением для создания удобных и простых в использовании и сопровождении информационных систем, эффективно работающих с база ми данных, стало объединение Интернет/интранет-технологии с многоуровневой архитектурой. При этом структура информационного приложения приобретает следующий вид: браузер — сервер приложений — сервер баз данных — сервер динамических страниц — web-сервер. Благодаря интеграции Интернет/интранет-технологий и архитектуры клиент-сервер процесс внедрения и сопровождения корпоративной информационной системы существенно упрощается при сохранении достаточно высокой эффективности и простоты совместного использования информации.

