 2015-01-21
2015-01-21 1601
1601Она построена на предположении о том, что устранение ошибки в программе приводит к увеличению времени наработки на одну и ту же случайную величину.
Модель Джелинского-Моранды.
Эта модель основана на следующих предположениях:
1. Время до следующего отказа распределено экспоненциально;
2. Интенсивность отказов программы пропорциональна количеству оставшихся в программе ошибок.
Согласно этим допущениям ВБР программ как функция времени ti равна:
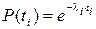
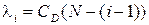 , (1)
, (1)
где i – число обнаруженных ошибок;
CD – коэффициент пропорциональности, CD» 0,02 (определяется по методу максимума правдоподобия);
N – первоначальное число ошибок программы. В выражении (1) отчет времени начинается от момента последнего (i –1)-го отказа программы.
Модель Шумана.
Данная модель отличается от модели Джелинского-Моранды только тем, что периоды времени отладки и эксплуатации программ рассматриваются отдельно.
Модель Шика-Вольвертона.
Основой этой модели является предположение о том, что интенсивность ошибок программы пропорциональна не только количеству оставшихся в программе ошибок, но и времени потраченному на отладку.
Экспоненциальная модель надежности программ.
Модель основана на предположении об экспоненциальном характере изменения во времени числа ошибок в программе.
В этой модели прогнозируется надежность программы на основе данных, полученных во время тестирования. В модели вводится суммарное время функционирования τ, которое отсчитывается от момента начала тестирования программы (с устранением обнаруженных ошибок) до конца контрольного момента, когда производится оценка надежности.
Предполагается, что все ошибки в программе независимы и проявляются в случайные моменты времени с постоянной средней интенсивностью в течении всего времени выполнения программы. Основное отличие данной модели от предыдущих состоит в том, что интенсивность отказов предполагается непрерывной функцией. Это упрощает математическое описание модели.
Пусть М – число ошибок, имеющихся в программе перед тестированием (М рассматривается как некоторая константа);
m (τ)– конечное число исправленных ошибок;
m 0(τ)– число оставшихся ошибок.
Тогда:
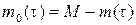 , (2)
, (2)
Предполагается, что интенсивность отказов пропорциональна числу оставшихся ошибок m 0(τ), т.е.:
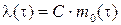 . (3)
. (3)
С – коэффициент пропорциональности учитывающий реальное быстродействие компьютера и число команд в программе.
Считаем (дополнительное предположение), что в процессе корректировки новые ошибки не порождаются, т.е. что интенсивность исправления ошибок 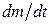 будет равна интенсивности их обнаружения, т.е.:
будет равна интенсивности их обнаружения, т.е.:
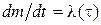 (4)
(4)
Решая совместно два вышеуказанных уравнения (3) и (4) получаем:
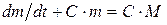 (5)
(5)
Перед началом работы компьютера (t = 0) ни одна ошибка исправлена не была (τ = 0), поэтому решением управления является:
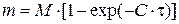 , (6)
, (6)
где m – число исправленных ошибок в течении времени τ.
Среднее время наработки на отказ в течении времени τ после тестирования характеризуют надежность программы:
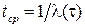
Следовательно:
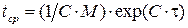 (7)
(7)
Среднее время наработки на отказ увеличивается по мере выявления и исправления ошибок.
Рассмотренная модель может применяться для определения времени испытаний программ с целью достижения заданного уровня надежности, а также для оценки числа оставшихся в программе ошибок.
Модель надежности больших программных комплексов.
Для прогноза надежности больших программных комплексов может быть использована марковская модель. Надежность всего программного комплекса определяется как функция надежности ее составных частей. Подобная оценка значительно облегчается, если программа строится по модульному принципу. Надежность программного комплекса будет зависеть от последовательности выполняемых модулей и надежности каждого из этих модулей.
Прогнозирование надежности на ранних этапах их разработок.
В настоящее время наиболее отработаны способы прогнозирования ожидаемого числа ошибок в программах [1, 11].
Оценка ожидаемого числа ошибок 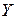 в программе выражается через линейную зависимость:
в программе выражается через линейную зависимость:
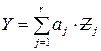 ,
,
где r – число существующих параметров;
aj – коэффициент, зависящий от типа программ (управляющий, ввода-вывода, вычислительные, служебные);
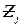 – j -параметр программы.
– j -параметр программы.
В качестве параметров выбраны величины:
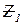 – сложность уловных операторов IF
– сложность уловных операторов IF
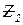 – общее число ветвлений;
– общее число ветвлений;
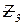 – общее число связей с прикладными программами;
– общее число связей с прикладными программами;
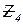 – общее число связей с системными программами;
– общее число связей с системными программами;
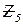 – число операций ввода-вывода;
– число операций ввода-вывода;
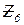 – число вычислительных операторов;
– число вычислительных операторов;
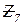 – число операторов обработки данных;
– число операторов обработки данных;
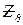 – число комментариев.
– число комментариев.
Если число ожидаемых в программе ошибок оценено, то интенсивность отказов программы оценивается по выражению:
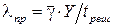 , (8)
, (8)
где tреш – среднее время однократного прохождения программы;
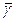 – усредненное по всем ошибкам значение γ – условной вероятности того, что ошибка в программе проявляется при прохождении программы.
– усредненное по всем ошибкам значение γ – условной вероятности того, что ошибка в программе проявляется при прохождении программы.
Рекомендуется оценивать γ экспериментально (статистически), определяя интенсивность отказа и количество ошибок для нескольких программ. Тогда:
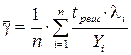
λi, Yi, tреш – соответственно интенсивность отказов, количество ошибок и время решения для i -й программы;
n – количество испытанных программ.
Интуитивная модель.
Эта модель используется при экспериментальной оценке числа ошибок в программе.
Согласно этой модели число ошибок в программе оценивается как:
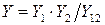 ,
,
где Y 1, Y 2 – число ошибок, обнаруженных первым и вторым программистами, отлаживающих независимо друг от друга первоначальный текст программы, а Y 12 – число ошибок, обнаруженных как первым, так и вторым программистами.
Очевидно, что первоначальный текст программы должен быть разработан при этом третьим программистом, чтобы поставить отлаживающих текст программистов в равные условия.
Для прогнозирования надежности ПО, в частности для прогнозирования количества не выявленных ошибок на этапе тестирования имеется интуитивная модель.
Пусть одна группа тестирования обнаруживает N 1, а другая N 2 ошибок, N 12 – количество ошибок, обнаруженных обеими группами. Обозначим через N общее количество ошибок ПО. Если ввести понятие эффективности тестирования групп как отношения количества выявленных ошибок к их общему числу, то эффективности тестирования групп соответственно 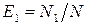 ,
, 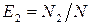 ;
;
Предполагается, что эффективность тестирования каждой группы одинакова как на всем множестве пространства ошибок ПО, так и на любом его подмножестве. В этом случае справедливо соотношение:
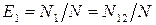 ;
;
Подстановка N 2 приводит к выражению вида:
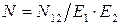 ,
,
где 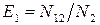 ;
; 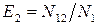 ;
;
Пример. Пусть группы тестирования обнаружили соответственно 20 и 25 ошибок, из них 5-ошибки обнаруженные обеими группами. В этом случае Е 1 = 0,2; Е 2 = 0,25.
Общее количество ошибок N = 100, а количество ошибок, оставшихся в не выявленными – 60.
Контрольные вопросы и задания
1. Для чего используются модели надежности ПО ИС?
2. Какие параметры надежности можно определить с помощью моделей ПО?
3. Оцените преимущества и недостатки известных моделей ПО.
4. С помощью какой модели можно прогнозировать надежность ПО на этапах разработки ИС?
5. Какие существуют методы повышения надежности ПО?
6. Оцените общее число ошибок в тексте программы, если программа проверена тремя специалистами и если первый из них нашел в программе 3 ошибки, второй – 5 ошибок, а третий – 6 ошибок, причем две ошибки из найденных были общими у всех специалистов.
7. Какие существуют пути повышения надежности ПО компьютеров и КС?
8. Для чего используют модель надежности Шумана?
9. В чем суть интуитивной модели надежности программ?
10. Как оценить ожидаемое число ошибок в программе, если использовать модель надежности программ на ранних этапах разработки.
Литература: 2,3,6, 8,11
Лекция 16
Тема: Надежность отказоустойчивых систем (ОУС). Назначение и свойства ОУС, примеры реализации
План.
2. Назначение и свойства отказоустойчивых КС.
3. Примеры реализации. Система: TANDEM,
4. Системы: STAR, SIFT.
Ключевые слова
Отказоустойчивость, надежность, конфигурация, восстановление, метод контрольных точек, неисправности, повтор программы, активная отказоустойчивость, пассивная отказоустойчивость, маскирование, рестарт, аппаратное восстановление, программное восстановление, интенсивность отказов, наработка на отказ, безотказная работа, высокая готовность, резервирование, граф состояний.
Для систем управления производственными процессами и приложений по оперативной обработке информации совершенно естественны повышенные требования к организации высоконадежных вычислений. Современные телекоммуникационные системы, системы управлениям воздушным и наземным транспортом, медицинские учреждения, фондовые биржи, банки и промышленные предприятия не могут приостановить свою работу из-за неисправности компьютерной системы. В подобных приложениях простой может привести к задержке выхода продукции, потере прибылей, поломке оборудования и к человеческим жертвам. Поэтому проблема обеспечения надежности и отказоустойчивости современных компьютеров является очень актуальной и перспективной.
В настоящее время одной из основных задач построения компьютерных систем (КС) остается обеспечение их продолжительного надежного функционирования. Эта задача имеет три составляющие: надежность, высокая готовность и удобство обслуживания. Её решение предполагает, в первую очередь, борьбу с неисправностями системы, порождаемыми отказами и сбоями в её работе.
2. Назначение и свойства отказоустойчивых КС
Отказоустойчивость – свойство архитектуры КС, позволяющее пользователю или функциональной программе продолжать работу и тогда, когда в аппаратных или программных средствах возникают отказы.
По способу реализации отказоустойчивость подразделяется на активную и пассивную.
Активная отказоустойчивость базируется на процессах обнаружения отказа, локализации отказа и реконфигурации системы. Отказы обнаруживается при помощи средств контроля, локализируется с помощью средств диагностирования и устраняются автоматической реконфигурацией системы (см. п. 3).
Пассивная отказоустойчивость заключается в свойстве системы не потерять свои функциональные свойства в случае отказа отдельных элементов системы. Пассивная отказоустойчивость связана с увеличением количества аппаратуры в несколько раз. Пассивная отказоустойчивость применяется в случае особо ответственных КС, когда не допустимы даже кратковременные перерывы в обработке КС, а также для обеспечения отказоустойчивости его важнейших блоков или устройств.
Применение активной отказоустойчивости характеризуется более экономными расходом аппаратных средств, чем применение пассивной отказоустойчивости. Однако оно связано с некоторыми потерями времени при восстановлении работы системы после отказа, а также потерями некоторой части данных. Активная отказоустойчивость реализуема только в многопроцессорных системах (с общей памятью, общей шиной, матричной, кольцевой или другой структурой). В то же время применение пассивной отказоустойчивости гарантирует практически безостановочную работу КС и сохранение всей информации. Эти обстоятельства и определяют области применения активной и пассивной отказоустойчивости.
Введение отказоустойчивости является одним из методов повышения надежности КС. Вопрос о построении и применении отказоустойчивых систем возникает тогда, когда другие пути повышения надежности не могут обеспечить требуемого уровня надежности по техническим причинам, или тогда, когда они отказываются экономически не оправданными.
Отдельно от надежности отказоустойчивость системы может быть охарактеризована коэффициентом разряжения первичного потока отказов Кр, показывающим, какая доля из всех отказов системы влечет за собой отказ системы. Коэффициент разряжения равен:
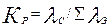
где 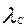 - интенсивность отказов системы, а ålЭ – суммарная интенсивность отказов всех элементов системы.
- интенсивность отказов системы, а ålЭ – суммарная интенсивность отказов всех элементов системы.
В то время как случайные отказы аппаратуры в нормальных условиях работы – редкие события, вероятность разрушения аппаратуры в тяжелых условиях, например в космосе, может быть значительной.
В тяжелых условиях работы аппаратуры механизмы отказа являются часто зависимыми, обусловленными одной и той же внешней причиной. Поэтому наряду с известными вероятностными методами теории надежности для отказоустойчивых систем представляет интерес детерминированный подход. В качестве меры отказоустойчивости при детерминированном подходе служит d-устойчивость – максимальное число d элементов или других структурных единиц системы, отказ которых ещё не влечет со собой отказ системы.
Примеры реализации отказоустойчивых КС
В настоящее время существуют различные отказоустойчивые компьютерные системы. Типичными примерами таких систем являются: TANDEM, STRATUS, STAR, SIFT, AS220 и другие. Они имеют различное целевое назначение, созданы различными фирмами и обладают принципиальными отличиями в реализации средств обеспечения отказоустойчивости. Рассмотрим некоторые из них.
Система TANDEM
Данная система представляет собой КС, обеспечивающие непрерывное функционирование, в том числе при отказе одного или нескольких элементов аппаратуры. КС предназначена для использования в режиме реального времени, когда требуется высокая надежность.
В состав системы TANDEM может входит от 1 до 16 процессорных модулей, каждый из которых содержит блок управления, 16-разрядный процессор, блок памяти и канал ввода-вывода. Все части этой системы резервированы. Система не имеет выделенного ведущего процессора, функции управления выполняет все процессоры системы. КС допускает ремонт во время работ, т.е. возможность удаления отказавших ТЭЗов и возвращения исправных без прекращения выполнения программ пользователей. Это достигается наличием нескольких процессоров, дублированным доступом к устройствам ввода-вывода, резервированной системой электропитания и операционной системой, основанной на сообщениях.
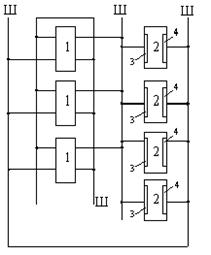
Рис. 4. Структура системы TANDEM
На рис. 4 изображена структура системы TANDEM, состоящей из трех процессоров 1 и четырех контроллеров ввода-вывода 2. Процессоры типа мини-ЭВМ сообщаются через 16-разрядную параллельную дублированную систему шин Ш. Все контроллеры ввода-вывода имеют по два порта 3,4 и доступ по двум каналам, от двух разных процессоров.
Запоминающие устройства на дисках такие имеют по два порта; каждое устройство доступно от двух контроллеров. Данные с диска остаются доступными даже тогда, когда и процессор, и контроллер отказывают.
При отказе привода диска записи могут быть восстановлены, если они были до его остановки записаны на другом диске. Если все записи на дисках дублированы, то система имеет копии всех данных. Когда диск заменяется, записи на нем можно восстанавливать во время работы основной системы.
Электропитание всех процессоров и дисков – независимое.
Каждый процессор системы содержит собственную копию операционной системы, обладающую локальной таблицей, отражающей состояние всех доступных устройств системы.
Контрольные точки. Они являются ключевым механизмом в системе TANDEM. Для каждого текущего вычислительного процесса в системе имеется идентичный полуактивный дублирующий процесс в другом процессоре. Дублирующий процесс должен заменить основной процесс в случае отказа соответствующего процессора. Основной процесс посылает дублирующему процессу «Контрольные соотношения», которые определяют состояние процесса в критических точках вычисления.
Операционная система в каждом процессоре возбуждает дублирующий процесс после обнаружения того, что основной процесс отказал. Дублирующий процесс может тогда продолжать процесс, начиная от состояния, зафиксированного в последней контрольной точке.
Программное обеспечение содержит виртуальную операционную систему и позволяет осуществлять мультипрограммную обработку.
Система сообщений. Изоляция процессов пользователя в TANDEM обеспечивается формированием сообщений. Например, программа пользователя, нуждающаяся в некоторых данных, записанных на диске, формирует некоторое «сообщение», адресованное программе логического управления диском. Просматривая свои таблицы ресурсов, локальная копия операционной системы определяет фактическое местонахождение искомого процесса.
Изоляция задач пользователя существенна для обеспечения ремонта во время работы системы, кроме того, такая изоляция обеспечивает постепенной рост производительности системы.
Система STAR
Компьютерная система STAR (Self-Testing and Repairing) – самопроверяемая и ремонтируемая КС предназначена для беспилотных космических полетов большой продолжительности (до 10 лет). Здесь выбран следующий принцип организации средств обеспечения отказоустойчивости (СОО). В каждый момент времени функционирует одна вычислительная машина, снабженная эффективными схемами контроля для обнаружения неисправностей и достаточным количеством резервных блоков. При этом используется ненагруженный резерв, т.е. на резервные блоки не подается напряжение питания. В системе STAR большая часть функций средств отказоустойчивости реализуется в виде аппаратного блока (введением структурной избыточности) (рис.6).
|
Поскольку в системе предусмотрен только один рабочий компьютер, потребовалось организовать специальное аппаратное «ядро», которое обеспечило бы диагностику отказов в компьютере, автоматическую замену неисправных блоков на резервные и выработку управляющих сигналов, запускающих программную процедуру восстановления. Это «ядро», получило название – процессор контроля и восстановления (ПКВ).
Схема (рис.6) состоит из семи типов различных модулей, соединенных между собой четырехпроводными шинами и имеющих резервные копии.
УП – управляющий процессор содержит счетчик адресов и индексные регистры, осуществляет модификацию адресов команд перед их выполнением;
ЛП – логический процессор – выполняет логические операции над информационными словами (напряжение питания подается сразу на 2 копии);
ОАП – основной арифметический процессор выполняет арифметические операции над информационными словами;
ПЗУ – постоянное запоминающее устройство;
ПВВ – процессор ввода-вывода содержит буферные регистры ввода-вывода и процессор прерывания, управляет запросами на прерывания;
ПКВ – процессор контроля и восстановления управляет работой компьютера и осуществляет восстановление (питание подается одновременно на три корни, тройной нагруженный резерв).
Информация между модулями передается по шине записи в память и шине считывания из памяти в виде восьми 4-разрядных посылок, т.е. разрядность слова-32. Параллельно-последовательный принцип обработки выбран по причине снижения потребляемой мощности и вероятности отказа в системе [4,6,7].
Модуль ПКВ – самый оригинальный модуль в этой компьютерной системе. Он следит за работой шин посредством проверки справедливости кодов с обнаружением ошибок, а также за сообщениями о состоянии различных функциональных модулей. Если приходит сигнал ошибки с какого-либо модуля или в шину поступает неправильно закодированная информация с выхода модуля, то ПКВ инициирует повторное выполнение сегмента программы. Если ошибка повторяется, производится замена неисправного блока резервным с помощью шины управления.
Функции обнаружения ошибок и восстановления в данной системе подробно описаны в [3,5,7].
Система STAR одна из первых отказоустойчивых КС и идеология её построения оказала большое влияние на последующие разработки КС данного типа.
Система SIFT (Softwave Implemented Fault Tolerance) – представляет собой КС, предназначенную для управления полетом самолета в особо сложных условиях. Основной принцип построения системы, состоит в обеспечении отказоустойчивости в основном программными способами, а не аппаратными. Особенностью СОО является параллельное выполнение каждой программы несколькими блоками обработки данных. Процедуры обнаружения и анализа ошибок и реконфигурация системы возложены на программное обеспечение, отсюда и название системы. Локализация отказов достигается применением специально разработанной избыточной системы шинных соединений блоков обработки данных. Как минимум троекратное резервирование выполнения программ позволяет устранить влияние любого одиночного отказа блока обработки данных или шины, а устойчивость к последовательности отказов создается за счет реконфигурации системы.
Эти примеры приводятся здесь как иллюстрация разных подходов к реализации СОО для конкретных применений и по существу на них хорошо просматривается та совокупность задач, с которыми сталкивается разработчик современных компьютерных систем.
Современный уровень развития отказоустойчивых КС может быть охарактеризован также данными о зарубежных специализированных компьютерах [7,8] для космических кораблей (табл. 1).
Таблица 1.
| Параметры | Выпускающая фирма и тип компьютера | |||||
| CDS 496 | DELCO M-362 | GE.DEC PDP-11 | LITTON 4516 E | RCA SCP-234 | Rockwell DF-224 | |
| Быстродействие, тыс. оп/с | 650/840 | |||||
| Длина слова, бит | 16(42) | 16/32 (120) | 16/32 | |||
| Вероятность безотказной работы, P(t) | 0,925 за один год | 0,99 за один год | 0,99 за два года | 0,98 за два года | 0,899 за два года | 0,92 за три года |
Приведенные в таблице 1 значения вероятности безотказной работы определены с учетом резервирования. В случае дублирования эти данные соответствуют интенсивности отказов порядка
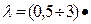 10-5 1/ t
10-5 1/ t
для одного компьютера, что достижимо при использовании компонентов наиболее высокого качества и надежности. В типичном случае дублированы устройства ввода-вывода, центральный процессор и устройства управления памятью. Оперативные запоминающие устройства объемом в десяти Кслов секционированы. Переключающие устройства для включения резервов построены с использованием логических схем с переплетениями [7]. В системах применяется аппаратный оперативный контроль вместе с программным тестовым контролем и диагностикой, которые дополняют друг друга и вырабатывают сигналы для автоматического включения резерва.
В компьютерных системах, предназначенных для непилотируемых космических кораблей, наряду с автоматическим контролем и включением резерва предусматриваются наземный телеметрический контроль и реконфигурация системы через каналы телеуправления в случае обнаружения отказов.
Контрольные вопросы и задания
1. Как обеспечить высокую надежность при создании современных компьютерных систем?
2. Какой вид контроля в КС является наиболее перспективным?
3. Дайте определение понятию «реконфигурация».
4. Определите виды ошибок в КС которые можно исправить с помощью маскирования.
5. Какие бывают КС по способу реализации отказоустойчивости?
6. Постройте граф состоянии и переходов процесса восстановления в отказоустойчивых КС.
7. Что характеризует коэффициент разряжения КС?
8. Объясните способы реализации СОО, заложенные в системе TANDEM.
9. Что называется «контрольной точкой»?
10. Для каких целей предназначена система STAR?
11. Какова функция ПКВ в системе STAR?
12. Какой вид контроля используется в системе SIFT?
13. Укажите типичные значения вероятности безотказной работы современных высоконадежных компьютеров.
Литература: 1, 2, 3, 5, 10, 11.
Лекция 17
Тема: Методы и алгоритмы автоматического восстановления ИС
План
1. Реконфигурация в технических устройствах ИС.
2. Способы восстановления в высоконадежных КС.
3. Модель процесса автоматического восстановления отказоустойчивых КС.
Ключевые слова
Отказоустойчивая система, безотказность, реконфигурация, автоматическое восстановление, интенсивность восстановления, состояния, динамическое резервирование, избыточность, активная отказоустойчивость, модель восстановления.
Реконфигурация и способы восстановления КС.
Среди перечисленные выше методов обеспечения и повышения надежности наиболее перспективными являются использование новых способов восстановления, автоматической реконфигурации и создание отказоустойчивых КС. Рассмотрим эти вопросы.
Реконфигурация КС – изменение состава и способа взаимодействия программных и аппаратных средств системы с целью исключения отказавших программных или аппаратных компонентов. Реконфигурация производится после выявления отказа. Различают статическую и динамическую реконфигурацию.
Статическая реконфигурация системы осуществляется путем отключения неисправных компонентов КС. Динамическая реконфигурация по принципу проведения делится на следующие виды: замещение, дублирование, постепенная «деградация».
После реконфигурации для продолжения нормальной работы системы необходимо её восстановить, восстановление системы происходит на двух уровнях (рис. 1).
1. Аппаратный уровень. Здесь производится восстановление отказавших компонентов КС двумя способами:
· автоматическое восстановление, реализуемое путем реконфигурации системы. При этом предполагается, что в системе имеется ряд запасных блоков, благодаря которым она возвращается в работоспособное состояние;
· ремонт (восстановление вручную). В этом случае отказавший блок отключается от системы и она продолжает работу с меньшей производительностью, либо приостанавливается до возвращения отремонтированного блока в активную часть КС.
|






2. Программный уровень, здесь осуществляется восстановление информации о состоянии КС, необходимой для продолжения её работы.
Средства восстановления включаются в работу при обнаружении ошибки системой контроля. Способ восстановления зависит от уровня, на котором обнаружена ошибка. В зависимости от нарушений в работе системы можно выделить следующие способы восстановления: маскирование, повторение операции, возврат к контрольной точке, программный рестарт. На рис. 2 приведен алгоритм автоматического восстановления вычислительного процесса после сбоев, где использованы все виды восстановления.
Маскированием называется исправление ошибки с помощью корректирующих кодов или резервирования. Восстановление путем маскирования или повторения операции выполняется в том случае, когда ошибка обнаружена средствами контроля логического уровня и, следовательно, не успела распространиться.
Восстановление путем повторения операции может быть успешным, если ошибка была случайной или перемежающейся и самоустранилась при повторении, т.е. проявилась как сбой. Поскольку длительность случайной ошибки может быть разной, система должна повторять операции несколько раз. Повторение может быть на уровне микрокоманд, команд и операций ввода-вывода.
В тех случаях, когда ошибка обнаруживается средствами функционального или системного уровня, т.е. успела исказить информацию, используется восстановление путем возврата к контрольной точке.
Контрольной точкой называется некоторая точка в вычислительном процессе (программе), для которой сохранены промежуточные результаты вычислений, и к которой в случае ошибки можно вернуться (передать управление). Этот способ восстановления требует по ходу вычислительного процесса формирования контрольных точек (т.е. периодического запоминания промежуточных результатов вычислительного процесса).
Программным рестартом называется повторный запуск вычислительного задания. Этот способ восстановления используется в том случае, когда ошибка обнаружена средствами контроля пользовательского уровня. Маскирование и повторение операции как способы восстановления более предпочтительны, так как обеспечивают ранее обнаружение ошибки и восстановление. Однако они требуют значительных затрат аппаратуры.
Сохранение работоспособности компьютеров при отказах имеет большое значение при эксплуатации систем, работающих в реальном масштабе времени, систем с разделением времени, систем телеобработки, диалоговых систем и др.
Автоматическое восстановление вычислительного процесса при отказах может быть достигнуто путем введения в КС свойств отказоустойчивости.
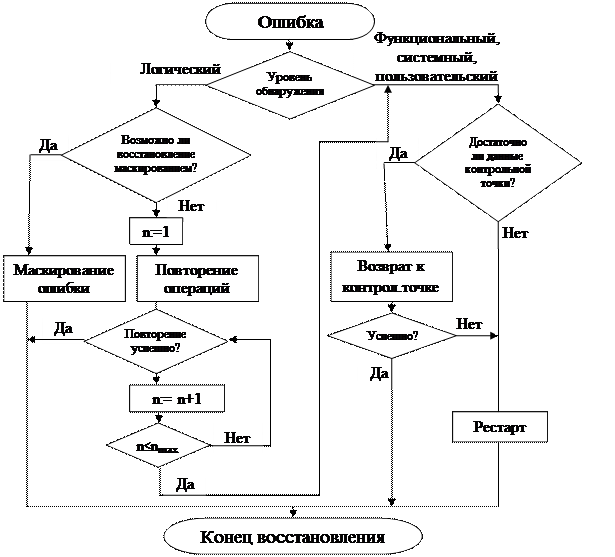
Рис. 2. Функционирование вычислительного процесса.
Модель процесса автоматического восстановления
отказоустойчивых КС
Автоматическое восстановление в компьютерных системах является новым подходам, обеспечивающим высокую степень надежности, готовности и отказоустойчивости КС.
Ниже предлагается модель, описывающая общие свойства различных процессов восстановления, некоторой гипотетической отказоустойчивой КС. Она включает все возможные процессы восстановления, применяемые в реальных КС. Множество возможных событий в системе обозначим через
S={S1,S2,…,S16}.
Процессы восстановления в пассивных и активных отказоустойчивых КС имеют много общего. Рассмотрим граф на рис. 3.[1,7,10]:
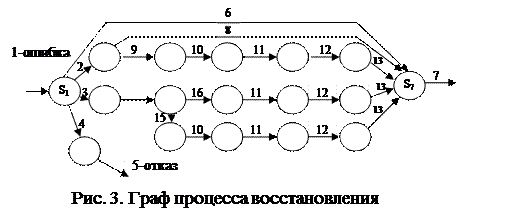
Возникшая в КС ошибка S1 может обнаруживаться либо аппаратными S2, либо программными S3 средствами контроля, либо не обнаруживаться средствами контроля S4. В последнем случае результатом является отказ системы S5.
В зависимости от степени применения пассивной отказоустойчивости в КС ошибка может быть маскирована S6 и вычислительный процесс продолжается без задержки S7. При обнаружении ошибки аппаратными средствами в большинстве систем проводится повторение выполняемой операции в заданное число раз. Если повторение было успешным, т.е. имел место сбой, последствия которого при повторении операции исчезли, вычислительный процесс продолжается S8. Для повторении операции необходимо чтобы аппаратные средства сохранили операнды до окончания контроля над выполненной операцией. Если повторении операции было безуспешным S9, то это говорит об устойчивой ошибке в аппаратуре и поэтому производится автоматическая реконфигурация S10.
Реконфигурация может заключаться либо в замене отказавшей подсистемы (устройства, процессора) за счет резервов, либо в её простом отключении. В последнем случае имеет место постепенная деградация системы. После реконфигурации производится восстановление информации S12. Для этого по ходу вычислительного процесса предусмотрены контрольные точки, в которых состояние системы и вычислительного процесса подвергаются контролю. В случае положительного результата контроля состояние данной программы и данного процессора (промежуточные результаты, содержание регистров и др.) записывается либо в оперативной памяти другого процессора, либо на магнитных лентах или дисках.
В ходе восстановления информации содержание этих дублирующих записей переписывается в тот процессор, который после реконфигурации берет на себя функции отказавшего. Затем, начиная с контрольной точки, вычислительный процесс возобновляется S13.
Аналогичные процедуры проводятся в случае, когда ошибка обнаружена программными средствами. После обнаружения ошибки программными средствами могут быть задействованы тесты S14. Если тесты подтверждают наличие устойчивого отказа S15, то следует реконфигурация S10, возврат к контрольной точке S11, восстановление данных S12 и повторение вычислений S13. Если устойчивого отказа нет S16, то повторяются перечисленные операции без реконфигурации.
Восстановление может оказаться безуспешным также в случае наличия ошибки в программах, разрушения информации в контрольных точках, исчерпания резервов или снижения производительности системы из-за отказов.
Описанный выше процесс может варьироваться в конкретных системах, особенно что касается способов обнаружения отказов. Иногда, например процессоры системы подтверждают свою работоспособность специальными сигналами. По этим сигналам во всех действующих процессорах системы формируется таблицы, показывающие состояние всех других процессоров. На основании этих таблиц обмен с отказавшими процессорами прекращается.
Контрольные вопросы и задания
1. Определите виды ошибок в КС которые можно исправить с помощью маскирования.
2. Дайте определение понятию «реконфигурация».
3. Что такое динамическая и статическая реконфигурация.
4. Постройте граф состоянии и переходов процесса восстановления в отказоустойчивых КС.
5. Что называется контрольной точкой в вычислительном процессе?
6. Определите понятие «программный рестарт».
7. Какой вид отказа является наиболее жестким в теории надежности?
8. Назовите основные метод автоматического восстановления в КС.
Литература: 1, 2, 3, 5, 10.
Лекция 18
Тема: Задачи оптимального резервирования отказоустойчивых ИС
План
1. Прямая и обратная задачи резервирования в отказоустойчивых систем (ОУС).
2. Метод множителей Лагранжа для нахождения оптимального резерва в ОУС.
3. Градиентные метод оптимизации надежности.
4. Расчетные формулы. Графическая зависимость доминирующей последовательности ОУС.
Ключевые слова
Резервирование, отказоустойчивость, высоконадежные системы, задачи оптимизации, метод множителей Лагранжа, оптимальное резервирования, градиентных метод, экстремум функции, доминирующая последовательность, стоимостный показатель.

