 2015-01-13
2015-01-13 1638
1638При экспериментальном изучении зависимости между величинами мы считаем, что значение аргумента известны точно, но из-за случайных ошибок измерения значение аргументы тоже являются случайными величинами поэтому набл.значения представляющие собой систему из двух СВ.
Строгая функциональная зависимость реализуется редко, т.к обе величины подвержены действию случайных фактов, среди которых м.б и общие действующие на обе величины, в этом случае зависимость явл статической.
Статистической называют зависимость при которой изменение одной из величин влечет изменение закона распределения другой, в частности, если при изменении одной из величин изменяется среднее значение другой, то зависимость называется корреляционной, а сами величины корреляционными.
Известно, что для повышения надежности результатов и изменения дисперсии оценок нужны повторные измерения, т.е для одного и того же значения аргумента значения другой величины может наблюдаться несколько раз, тогда результаты измерений оформляются двухвходовой таблицей, в которой в верхней строке записываются значения одной величины (например, аргумента Х), а в левом столбце – значения другой величины (ф-ции У).
На пересечении строк и столбцов записываем частоты nij наблюдающихся пар (xi, yj)- это таблица называется корреляционной.
При повторных изменениях среднее значение одной величины при фиксированном значении другой называется условным средним.
Например, ýх –среднее значение величины У, при Х=х, если условные средние ýх зависят от значений х, т.е если Х и У связаны корреляционной зависимостью, то уравнение ýх=f*(х) назыв выборным уравнением регрессии У на Х, а её график – выборочной линией регрессии У на Х.
Регрессия – это зависимость МО СВ от значений других СВ.
Линейная регрессия – корреляционная регрессия между СВ Х и У, при которой выборочная уравнения прямой линии регрессии У на Х имеет вид ýх- ý=rВ(σу/σх)(х-х’),
Где ýх- условная средняя;
х’ и ý – выборочные средние признаков Х и У;
σу и σх – выборочная СКО;
rВ – выборочный коэффициент корреляции, причём rВ= (х’ý- х’*ý)/(σу*σх)
Пример. Реш-е: усовные ср.вычисляем по формуле: 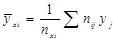 Так для х=0,5: у0,5‾=3,66
Так для х=0,5: у0,5‾=3,66
Условные ср.для соответствующих значений Х наносим на график.
По расположению точек делаем вывод о лин.коррелиции м/у признаками.
х‾=1/100*(3*0,3+29*0,4+47*0,5+..+2*08)=0,497; х‾2=0,2569; у‾=3,65; у‾2=14,65; σх=√(0,2569-(0,497)2)=9,945*10-2;σу=√(14,35-(3,65)2)=1,014; (ху)‾=1,893.
rВ=((ху)‾- х‾*у‾)/σхσу= 0,7829
Значение rВ дост.близко к 1, поэтому лин.св.м/у признаками должна быть признана дост.сильной. Ур-е прямой регрессии:
ух‾-у‾= rВ* σу/σх *(х-х‾)
ух‾=7,983х-0,3173
Найдем крайние точки для построения прямой регрессии У на Х: у 0,3=2,08; у0,8=6,07
34. Статистическая гипотеза. Виды гипотез. Ошибки 1-го и 2-го рода. Статистический критерий проверки нулевой гипотезы. Наблюдаемое значение критерия.
§ 1. Статистическая гипотеза. Нулевая и конкурирующая, простая и сложная гипотезы
Часто необходимо знать закон распределения генеральной совокупности. Если закон распределения неизвестен, но имеются основания предположить, что он имеет определенный вид (назовем его А), выдвигают гипотезу: генеральная совокупность распределена по закону А. Таким образом, в этой гипотезе речь идет о в и де предполагаемого распределения.
Возможен случай, когда закон распределения известен, а его параметры неизвестны. Если есть основания предположить, xто неизвестный параметр Θ равен определенному значению Θ0, выдвигают гипотезу: Θ=Θ0. Таким образом, в этой гипотезе речь идет о предполагаемой величине параметра одного известного распределения.
Возможны и другие гипотезы: о равенстве параметров двух или нескольких распределений, о независимости выборок и многие другие.
Статистической называют гипотезу о виде неизвестного распределения, или о параметрах известных распределений.
Например, статистическими являются гипотезы:
1) генеральная совокупность распределена по закону Пуассона;
2) дисперсии двух нормальных совокупностей равны между собой.
В первой гипотезе сделано предположение о виде неизвестного распределения, во второй - о параметрах двух известных распределений.
Гипотеза «на Марсе есть жизнь» не является статистической, поскольку в ней не идет речь ни о виде, ни о параметрах распределения.
Наряду с выдвинутой гипотезой рассматривают и противоречащую ей гипотезу. Если выдвинутая гипотеза будет отвергнута, то имеет место противоречащая гипотеза. По этой причине эти гипотезы целесообразно различать.
Нулевой (основной) называют выдвинутую гипотезу H0.
Конкурирующей (альтернативной) называют гипотезу H1 которая противоречит нулевой.
Например, если нулевая гипотеза состоит в предположении, что математическое ожидание а нормального распределения равно 10, то конкурирующая гипотеза, в частности, может состоять в предположении, что α≠10. Коротко это записывают так: H0:а=10; Н1:α ≠10.
Различают гипотезы, которые содержат только одно и более одного предположений.
Простой называют гипотезу, содержащую только одно предположение. Например, если λ -параметр показательного распределения, то гипотеза H0: λ=5—простая. Гипотеза H0: математическое ожидание нормального распределения равно 3 (σ известно)—простая.
Сложной называют гипотезу, которая состоит из конечного или бесконечного числа простых гипотез. Например, сложная гипотеза Н: λ>5 состоит из бесчисленного множества простых вида Hi: λ=bi, где bi—любое число, большее 5. Гипотеза H0: математическое ожидание нормального распределения равно 3 (σ неизвестно)—сложная.
§ 2. Ошибки первого и второго рода
Выдвинутая гипотеза может быть правильной или неправильной, поэтому возникает необходимость ее проверки. Поскольку проверку производят статистическими методами, ее называют статистической. В итоге статистической проверки гипотезы в двух случаях может быть принято неправильное решение, т. е. могут быть допущены ошибки двух родов.
Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза.
Ошибка второго рода состоит в том, что будет принята неправильная гипотеза.
Подчеркнем, что последствия этих ошибок могут оказаться весьма различными. Например, если отвергнуто правильное решение.«продолжать строительство жилого дома», то эта ошибка первого рода повлечет материальный ущерб; если же принято неправильное решение «продолжать строительство», несмотря на опасность обвала стройки, то эта ошибка второго рода может повлечь гибель людей. Можно привести примеры, когда ошибка первого рода влечет более тяжелые последствия, чем ошибка второго рода.
Замечание I. Правильное решение может быть принято также в двух случаях:
1) гипотеза принимается, причем и в действительности она правильная;
2) гипотеза отвергается, причем и в действительности она неверна.
Замечание 2. Вероятность совершить ошибку первого рода принято обозначать через α; ее называют уровнем значимости. Наиболее часто уровень значимости принимают равным 0,05 или 0,01. Если, например, принят уровень значимости, равный 0,05, то это означает, что в пяти случаях из ста имеется риск допустить ошибку первого рода (отвергнуть правильную гипотезу).
§ 3. Статистический критерий проверки нулевой гипотезы. Наблюдаемое значение критерия
Для проверки нулевой гипотезы используют специально подобранную случайную величину, точное или приближенное распределение которой известно. Эту величину обозначают через U или Z, если она распределена нормально, F или v2- по закону Фишера-Снедекора, Т-по закону Стьюдента, χ2-по закону «хи квадрат» и т. д. Поскольку в этом параграфе вид распределения во внимание приниматься не будет, обозначим эту величину в целях общности через К.
Статистическим критерием (или просто критерием) называют случайную величину K, которая служит для проверки нулевой гипотезы.
Например, если проверяют гипотезу о равенстве дисперсий двух нормальных генеральных совокупностей, то в качестве критерия К принимают отношение исправленных выборочных дисперсий: F=s12/s22.
Эта - величина случайная, потому что в различных опытах дисперсии принимают различные, наперед неизвестные
значения, и распределена по закону Фишера-Снедекора. Для проверки гипотезы по данным выборок вычисляют
частные значения входящих в критерий величин и таким образом получают частное (наблюдаемое) значение критерия.
Наблюдаемым значением Kнабл называют значение критерия, вычисленное по выборкам. Например, если по двум
выборкам найдены исправленные выборочные дисперсии
s12= 20 и s22= 5, то наблюдаемое значение критерия F: Fнабл=s12/s22=20/5=4.
35. Критическая область. Отыскание критических областей. Мощность критерия.
§ 4. Критическая область. Область принятия гипотезы. Критические точки
После выбора определенного критерия множество всех его возможных значений разбивают на два непересекающихся подмножества: одно из них содержит значения критерия, при которых нулевая гипотеза отвергается, а другая - при которых она принимается.
Критической областью называют совокупность значений критерия, при которых нулевую гипотезу отвергают.
Областью принятия гипотезы (областью допустимых значений) называют совокупность значений критерия, при которых гипотезу принимают.
Основной принцип проверки статистических гипотез можно сформулировать так: если наблюдаемое значение критерия принадлежит критической области -гипотезу отвергают, если наблюдаемое значение критерия принадлежит области принятия гипотезы -гипотезу принимают.
Поскольку критерий К -одномерная случайная величина, все ее возможные значения принадлежат некоторому интервалу. Поэтому критическая область и область принятия гипотезы также являются интервалами и, следовательно, существуют точки, которые их разделяют.
Критическими точками (границами) kкр называют точки, отделяющие критическую область от области принятия гипотезы.
Различают одностороннюю (правостороннюю или левостороннюю) и двустороннюю критические области.
Правосторонней называют критическую область, определяемую неравенством К>kкр>где kкр -положительное число.
Левосторонней называют критическую область, определяемую неравенством К<kкр, где kкр-отрицательное число.
Односторонней называют правостороннюю или левостороннюю критическую область.
Двусторонней называют критическую область, определяемую неравенствами К<k1, K>k2, где k2>k1.
В частности, если критические точки симметричны относительно нуля, двусторонняя критическая область определяется неравенствами (в предположении, чтоkкр>0): K<-kкр, К>kкр, или равносильным неравенством |К|>kкр.
§ 5. Отыскание правосторонней критической области
Как найти критическую область? Обоснованный ответ на этот вопрос требует привлечения довольно сложной теории. Ограничимся ее элементами. Для определенности начнем с нахождения правосторонней критической области, которая определяется неравенством K>kкр, где kкр>0- Видим, что для отыскания правосторонней критической области достаточно найти критическую точку. Следовательно, возникает новый вопрос: как ее найти?
Для ее нахождения задаются достаточной малой вероятностью- уровнем значимости α. Затем ищут критическую точку kкp, исходя из требования, чтобы при условии справедливости нулевой гипотезы вероятность того, что критерий К примет значение, большее kкр, была равна принятому уровню значимости: P(K>kкр)=α.
Для каждого критерия имеются соответствующие таблицы, по которым и находят критическую точку, удовлетворяющую этому требованию.
Замечание 1. Когда критическая точка уже найдена, вычисляют по данным выборок наблюденное значение критерия и, если окажется, что Кнабл>kкр, то нулевую гипотезу отвергают; если же Кнабл<kкр, то нет оснований, чтобы отвергнуть нулевую гипотезу.
Пояснение. Почему правосторонняя критическая область была определена исходя из требования, чтобы при справедливости нулевой гипотезы выполнялось соотношение P(K>kкр)=α? (*)
Поскольку вероятность события К>kкр мала (α -малая вероятность), такое событие при справедливости нулевой гипотезы, в силу принципа практической невозможности маловероятных событий, в единичном испытании не должно наступить. Если все же оно произошло, т. е. наблюдаемое значение критерия оказалось больше kкр, то это можно объяснить тем, что нулевая гипотеза ложна и, следовательно, должна быть отвергнута. Таким образом, требование (*) определяет такие значения критерия, при которых нулевая гипотеза отвергается, а они и составляют правостороннюю критическую область.
Замечание 2. Наблюдаемое значение критерия может оказаться большим kкр не потому, что нулевая гипотеза ложна, а по другим причинам (малый объем выборки, недостатки методики эксперимента и др.). В этом случае, отвергнув правильную нулевую гипотезу, совершают ошибку первого рода. Вероятность этой ошибки равна уровню значимости α. Итак, пользуясь требованием (*), мы с вероятностью α рискуем совершить ошибку первого рода.
Заметим кстати, что в книгах по контролю качества продукции вероятность признать негодной партию годных изделий называют «риском производителя», а вероятность принять негодную партию - «риском потребителя».
Замечание 3. Пусть нулевая гипотеза принята; ошибочно думать, что тем самым она доказана. Действительно, известно, что один пример, подтверждающий справедливость некоторого общего утверждения, еще не доказывает его. Поэтому более правильно говорить «данные наблюдений согласуются с кулевой гипотезой и, следовательно, не дают оснований ее отвергнуть».
На практике для большей уверенности принятия гипотезы ее проверяют другими способами или повторяют эксперимент, увеличив объем выборки.
Отвергают гипотезу более категорично, чем принимают. Действительно, известно, что достаточно привести один пример, противоречащий некоторому общему утверждению, чтобы это утверждение отвергнуть. Если оказалось, что наблюдаемое значение критерия принадлежит критической области, то этот факт и служит примером, противоречащим нулевой гипотезе, что позволяет ее отклонить.
§ 6. Отыскание левосторонней и двусторонней критических областей
Отыскание левосторонней и двусторонней критических областей сводится (так же, как и для правосторонней) к нахождению соответствующих критических точек.
Левосторонняя критическая область определяется неравенством К< kкр(kкр<0). Критическую точку находят исходя из требования, чтобы при справедливости нулевой гипотезы вероятность того, что критерий примет значение, меньшее kкр, была равна принятому уровню значимости: P(K>kкр)=α
Двусторонняя критическая область определяется неравенствами К <k1, K> k2. Критические точки находят исходя из требования, чтобы при справедливости нулевой гипотезы сумма вероятностей того, что критерий примет значение, меньшее k1 или большее k2, была равна принятому уровню значимости: P(K<k1)+ P(K>k2)=α(*)
Ясно, что критические точки могут быть выбраны бесчисленным множеством способов. Если же распределение критерия симметрично относительно нуля и имеются основания (например, для увеличения мощности*) выбрать симметричные относительно нуля точки -kкр и kкр,(kкр >0), то P(K<-kкр)+ P(K>kкр).
Учитывая (*), получим Р(К>kкр)=α/2.
Это соотношение и служит для отыскания критических точек двусторонней критической области.
Как уже было указано, критические точки находят по соответствующим таблицам.
§ 7. Дополнительные сведения о выборе критической области. Мощность критерия
Мы строили критическую область, исходя из требования, чтобы вероятность попадания в нее критерия была равна α при условии, что нулевая гипотеза справедлива. Оказывается целесообразным ввести в рассмотрение вероятность попадания критерия в критическую область при условии, что нулевая гипотеза неверна и, следовательно, справедлива конкурирующая.
Мощностью критерия называют вероятность попадания критерия в критическую область при условии, что справедлива конкурирующая гипотеза. Другими словами, мощность критерия есть вероятность того, что нулевая гипотеза будет отвергнута, если верна конкурирующая гипотеза.
Пусть для проверки гипотезы принят определенный уровень значимости и выборка имеет фиксированный объем. Остается произвол в выборе критической области. Покажем, что ее целесообразно построить так, чтобы мощность критерия была максимальной. Предварительно убедимся, что если вероятность ошибки второго рода (принять неправильную гипотезу) равна β, то мощность равна 1-β. Действительно, если β -вероятность ошибки второго рода, т. е. события «принята нулевая гипотеза, причем справедлива конкурирующая», то мощность критерия равна 1-β.
Пусть мощность 1-β возрастает; следовательно, уменьшается вероятность β совершить ошибку второго рода. Таким образом, чем мощность больше, тем вероятность ошибки второго рода меньше.
Итак, если уровень значимости уже выбран, то критическую область следует строить так, чтобы мощность критерия была максимальной. Выполнение этого требования должно обеспечить минимальную ошибку второго рода, что, конечно, желательно.
Замечание 1. Поскольку вероятность события «ошибка второго рода допущена» равна β, то вероятность противоположного
события «ошибка второго рода не допущена» равна 1-β, т. е. мощности критерия. Отсюда следует, что мощность критерия есть вероятность того, что не будет допущена ошибка второго рода.
Замечание 2. Ясно, что чем меньше вероятности ошибок первого и второго рода, тем критическая область «лучше». Однако
при заданном объеме выборки уменьшить одновременно α и β невозможно; если уменьшить α, то β будет возрастать. Например, если принять α=0, то будут приниматься все гипотезы, в том числе и неправильные, т. е. возрастает вероятность β ошибки второго рода.
Как же выбрать а наиболее целесообразно? Ответ на этот вопрос зависит от «тяжести последствий» ошибок для каждой конкретной задачи. Например, если ошибка первого рода повлечет большие потери, а второго рода—малые, то следует принять возможно меньшее α.
Если α уже выбрано, то, пользуясь теоремой Ю. Неймана и Э. Пирсона, изложенной в более полных курсах, можно построить критическую область, для которой β будет минимальным и, следовательно, мощность критерия максимальной.
Замечание 3. Единственный способ одновременного уменьшения вероятностей ошибок первого и второго рода состоит
в увеличении объема выборок.

