 2018-02-14
2018-02-14 2701
2701
3.6.1.Гипотеза о близости к нулю математического ожидания остатков
Здесь используется критерий Стьюдента для остатков и проверяется нуль-гипотеза:
 (3.17)
(3.17)
Så - среднее квадратичное отклонение остатков – мера рассеяния остатков относительно своего среднего
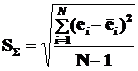 (3.18)
(3.18)
Замечание: Здесь число степеней свободы равно (N – 1), так как на вычисление среднего (центра рассеяния) расходуется одна степень свободы:
 (3.19)
(3.19)
где Se- среднее квадратичное отклонение наблюдений Y i относительно поверхности регрессии 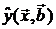 :
:
 (3.20)
(3.20)
где, k – число членов уравнения регрессии, включая свободный член.
3.6.2. Гипотеза о статистической значимости коэффициентов регрессии bj
|
|
|
Используя t – критерий Стьюдента проверяем нуль гипотезу:
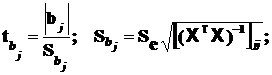 (3.21)
(3.21)
где под корнем стоит значение диагонального элемента информационной матрицы Фишера.
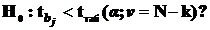
Выводы:
· Если данное неравенство выполнено, то коэффициент bj – статистически не значим.
· Если все коэффициенты в уравнение регрессии не значимы то уравнение регрессии не значимо: влияние регрессоров Х j на формирование значений Y не различимо на фоне случайных возмущений {E i }. Модель не адекватна.
· Если все коэффициенты уравнения регрессии значимы, то нарушение адекватности в данном пункте (по данной гипотезе) нет. Но вывод об адекватности делать рано, должны быть выполнены все предпосылки метода наименьших квадратов.
· Если часть коэффициентов уравнения регрессии значима, а часть не значима, то это не является снованием для нарушения адекватности. Значимая часть регрессоров может адекватно описывать объект.
· Незначимые коэффициенты уравнения регрессии и соответствующие им регрессоры следует исключить из модели: они не несут никакой полезной информации.
3.6.3. Гипотеза о статистической значимости всего уравнения регрессии в целом
Используется критерий Фишера- Снедекора F и проверяется нуль-гипотеза:
 (3.22)
(3.22)
QR – сумма квадратов отклонений расчетных значений  от среднего
от среднего  , обусловленная вариацией факторов; Qe - сумма квадратов отклонений расчетных значений
, обусловленная вариацией факторов; Qe - сумма квадратов отклонений расчетных значений  от фактически наблюдаемых, обусловленная влиянием случайных возмущений E i (включая влияние неучтенных в модели факторов).
от фактически наблюдаемых, обусловленная влиянием случайных возмущений E i (включая влияние неучтенных в модели факторов).
|
|
|

Выводы:
1. Если гипотеза Н0 выполнена, то уравнение регрессии в целом статистически незначимо и можно сразу делать вывод о неадекватности модели.
2. Если нуль-гипотеза Н0 не выполнена, т.е. F>Fтаб, то уравнение регрессии в целом значимо и можно переходить к проверке других гипотез.
3.6.4. Оценка качества уравнения регрессии
Для комплексной оценки качества уравнения регрессии используется коэффициент детерминации R2
Коэффициент детерминации R2 как мера качества уравнения регрессии характеризует долю вариации зависимой переменной, обусловленную регрессией (влиянием факторов), в общей вариацией результативной переменной Yi; чем ближе коэффициент детерминации R2 к единице, тем лучше уравнение регрессии аппроксимирует экспериментальные данные, тем ближе эмпирические точки располагаются к линии регрессии, тем больше прогностическая сила модели.
Замечание: Коэффициент множественной детерминации, определяется по результатам линейного корреляционного анализа, не следует смешивать с рассматриваемым коэффициентом детерминации R2, справедливого и для моделей, нелинейных по регрессорам (в этом случае его следует называть «индексом множественной детерминации»). Другими словами,
R2¹[R j. 12…m]2.
Это разные коэффициенты: первый из них связан с регрессионным анализом, т.е. привязан к конкретной параметрической модели , а второй связан корреляционным анализом линейно-связанных случайных величин, т.е. с корреляционной матрицей K. Сходство только в термине «детерминация», а расчетные формулы – разные:
 (3.23)
(3.23)
 (3.24)
(3.24)
Последняя формула справедлива только для линейных корреляционных связей.
Приемы улучшения качества модели:
1). Сделать предварительное сглаживание временного ряда (одномерного или многомерного) по методу простой скользящей средней или экспоненциального сглаживания. Данный прием применяют только при наличии упорядочения наблюдений во времени, т.е. для использования данных пространственного типа он не применяется.
2). Использовать нормирование всех переменных и зависимых и независимых:
 (3.25)
(3.25)
3). Выявить и выбросить из процедуры метода наименьших квадратов аномальные точки.
Выводы:
1. Приемлемость получаемого значения R2 определяется целями моделирования: если допустимы грубые (прикидочные) оценки, то можно принять R2 ~ 0,8, для более точных оценок R2 > 0,9.
2. Если база данных (БД) сильно зашумлена (или даже сознательно искажена, что имеет место в задачах налогового и финансового контроля), то может оказаться, что никакие «ухищрения» (о них речь позже) не позволяют получить R2>0,9. Что делать тогда?
Рекомендации:
Повысить информативность базы данных за счет различных алгоритмов предпроцессорной обработки (сглаживание, если база данных упорядочена по времени; кластеризации данных; компрессия данных (факторный анализ); расширения бахзы данных как парирование ее зашумленности; накнец – переход к другим моделям:
- нейросетевым [2,3,12,14]
- нечетким [14,15];
- фрактальным [4,6,9].
3.6.5. Скорректированный коэффициент детерминации
Недостаток нескорректированного коэффициента детерминации в том, что R2 увеличивается при введении новых факторов, хотя качество уравнения регрессии может и не возрастать, т.е. вводимые регрессоры являются малозначимыми. Скорректированный (адаптивный) коэффициент множественной детерминации определяется по формуле:
|
|
|
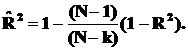 (3.26)
(3.26)
В отличие от не скорректированного коэффициента детерминации R2 этот коэффициент может в принципе уменьшаться при увеличении числа регрессоров (за счет знаменателя второго члена), если эти дополнительные регрессоры малозначимы, т.е.  более информативен, чем R2, но с одной оговоркой: для вновь вводимых регрессоров критерий Стьюдента должен быть больше 1 по модулю:
более информативен, чем R2, но с одной оговоркой: для вновь вводимых регрессоров критерий Стьюдента должен быть больше 1 по модулю:

3.6.6. Проверка гипотезы о чисто случайном характере остатков
Здесь может быть два случая:
Случай а): База данных упорядочена по времени: вектор – строки (или кортежи  ) расположены в порядке возрастания времени, т.е. образует многомерный временной ряд.
) расположены в порядке возрастания времени, т.е. образует многомерный временной ряд.
t i =t1,t2,…..tn; tn>t i -1, " i = 
В этом случае можно применить для оценки чисто случайного характера остатков {е i } два критерия: поворотных точек, либо критерий Фостера – Стьюарта [1] (отсутствие тренда в остатках). Для оценки наличия автокорреляции в остатках можно использовать критерий Дарбина – Уотсона [5].
1). При проверке гипотезы об отсутствии временного тренда в остатках по критерию поворотных точек проверяется нуль гипотеза:
 (3.27)
(3.27)
Если данное неравенство истинно, т.е. экспериментальное число поворотных точек p, определяемое по графику, меньше теоретического, то это означает, что имеется тренд в остатках и остатки не являются чисто случайными.
Если неравенство нарушено, то тренда в остатках нет, и их можно считать случайными, как не содержащими тренда.


Если нуль-гипотеза Н0 выполняется, то временного тренда нет.
2). Проверка гипотезы о наличии автокорреляции в остатках по критерию Дарбина-Уотсона
Автокорреляция – это корреляция между членами одного и того же временного ряда.
Здесь можно испльзовать d – статистику Дарбина-Уотсона:
 (3.28)
(3.28)
|
|
|
Смысл этого критерия: чем меньше разность суммируемых членов, тем сильнее проявление «последействия», т.е. влияния предыдущего остатка на последующий и тем вероятнее наличие автокорреляции остатков.
Замечание:
1. Если d>2, то перед входом в таблицу теоретических значений d-критерия надо сделать преобразование переменных:
d®d¢ = 4-d
Выводы:
· Автокорреляция имеет место, остатки не являются чисто случайными, нарушена адекватность модели, если d < dтаб.min.
· Ничего сказать об автокорреляции енльзя, нужно использовать другие критерии, если d Î [dтаб.min; dтаб.max].
· Автокорреляция отсутствует, нарушений адекватности нет, если
d > dтаб.max.
При неопределенной ситуации применяются другие критерии. В частности, можно использовать первый коэффициент автокорреляции, т.е. коэффициент линейной парной корреляции между соседними членами временного ряда еt, еt-1:
 (3.29)
(3.29)
 (3.30)
(3.30)
Случай б): База данных не упорядочена во времени (например, при социологических опросах, данные по разным странам т.д.)
В этих случаях упомянутые выше критерии поворотных точек, Фостера- Стьюарта, Дарбина- Уотсона в принципе неприменимы. Вместо них проверяется тест на отсутствие гетероскедастичности, т.е. корреляции между регрессорами  и остатками
и остатками  [5]. Например, можно использовать тест Уайта: строится линейное уравнение регрессии для квадратов остатков:
[5]. Например, можно использовать тест Уайта: строится линейное уравнение регрессии для квадратов остатков:
 (3.31)
(3.31)
Гипотеза о статистической значимости линейного уравнения регрессии для квадратов остатков в целом проверяется по критерию Фишера-Стьюдента, точно так же как и для основного уравнения регрессии.
 (3.32)
(3.32)
 (3.33)
(3.33)
Вывод:
Если нуль-гипотеза для критерия Фишера выполняется, то гетероскедастичности нет, если неравенство не выполняется, то это означает что гетероскедастичность есть, т.е. остатки е i не являя.тся случайными и это указывает на нарушение предпосылки 3 метода наименьших квадратов. В этом случае модель не адекватна.
3.6.7. Проверка гипотезы о нормальном законе распределения остатков
Обычно используется (R/S) - критерий, т.е. нормированный размах остатков:
(R/S) = (еmax-еmin)/Se, (3.34)
где Se определяется формулой (3.20).
Вывод:
Если  , то гипотеза о нормальном законе распределение остатков {е i } не отвергается.
, то гипотеза о нормальном законе распределение остатков {е i } не отвергается.
В противном случае – отвергается.
Общий вывод: Если все 6 гипотез, рассмотренные выше, о предпосылках метода наименьших квадратов выполняются и критерий качества модели R2 приемлем для поставленных целей моделирования, то модель считается адекватной и пригодной для практического применения.
Замечание. Если выборка деформируется (сужается или расширяется) либо изменяется принимаемый уровень значимости a оценок, то проверку адекватности надо делать заново.

