 2015-05-18
2015-05-18 46925
46925После того, как найдено уравнение линейной регрессии, проводится оценка, как уравнения в целом, так и отдельных его параметров.
Оценка значимости уравнения в целом, делается с помощью F-критерия. При этом выдвигается нулевая гипотеза H0, т.е. 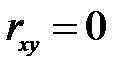 , и
, и 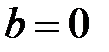 , и следовательно, фактор х не оказывает влияния на у, т.е. они не и взаимодействуют друг с другом.
, и следовательно, фактор х не оказывает влияния на у, т.е. они не и взаимодействуют друг с другом.
Сначала проанализируем общую дисперсию, это предшествует определению F- критерия. Центральное место занимает разложение общей суммы квадратов отклонений переменной у от среднего значения  на две части.
на две части.
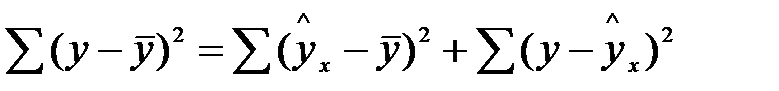
Общая сумма Объясненная Необъясненная квадратов регрессия (остаточная) отклонений регрессия
Общая сумма квадратов отклонений у от вызвана влиянием множества причин. Условно разделим их на две группы: изучаемый фактор х и прочие факторы.
Если фактор не оказывает влияние на результат, то линия регрессии на графике параллельна оси ОХ и 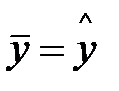 . Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. Сумма квадратов отклонений, объясняющей регрессией совпадает с общей суммой квадратов.
. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. Сумма квадратов отклонений, объясняющей регрессией совпадает с общей суммой квадратов.
Т.к. не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс. Он обусловлен влиянием фактора х, т.е. регрессией у по х, а также вызван действием прочих причин (необъясненная вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у, приходится на долю объясненную вариацией. Если сумма квадратов отклонений, обусловленных регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное воздействие на у. Это равносильно тому, что 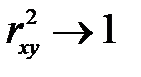 .
.
Любая сумма квадратных отклонений связана с числом степеней свободы (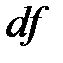 ), т.е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом, определяемым по ней констант. Т.о. число степеней свободы должно показать, сколько независимых отклонений из n возможных
), т.е. с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом, определяемым по ней констант. Т.о. число степеней свободы должно показать, сколько независимых отклонений из n возможных 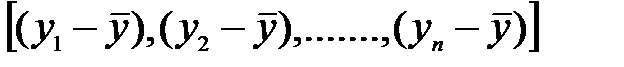 требуется для образования данной суммы квадратов. Так, для общей суммы квадратов
требуется для образования данной суммы квадратов. Так, для общей суммы квадратов 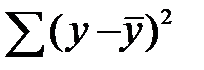 требуется
требуется 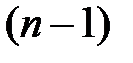 независимых отклонений, т. к. по совокупности из n единиц после расчёта среднего уровня свободно варьируется лишь число отклонений.
независимых отклонений, т. к. по совокупности из n единиц после расчёта среднего уровня свободно варьируется лишь число отклонений.
Например, 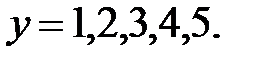
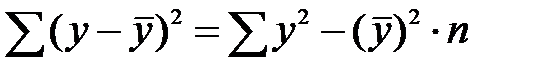
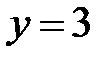 , тогда
, тогда 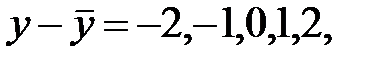 т. к.
т. к. 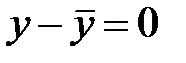 , то свободно варьируются только 4 отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
, то свободно варьируются только 4 отклонения, а пятое отклонение может быть определено, если предыдущие четыре известны.
При расчёте объясненной или факторной суммы квадратов 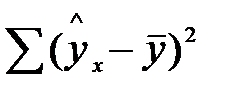 используются теоретические (расчётные) значения результативного признака
используются теоретические (расчётные) значения результативного признака 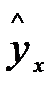 , найденные из уравнения
, найденные из уравнения 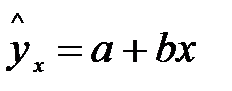 .
.
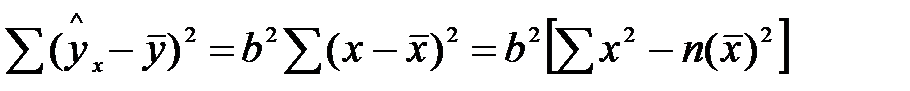
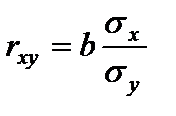 , а
, а 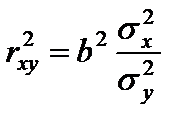
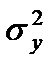 - общая дисперсия признака у;
- общая дисперсия признака у;
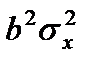 - дисперсия признака у, обусловленная фактором х.
- дисперсия признака у, обусловленная фактором х.
Поскольку при заданном объёме наблюдений по х и у факторная сумма квадратов при линейной регрессии зависит только от одной константы (коэффициента регрессии b), то данная сумма квадратов имеет одну степень свободы.
К этому же выводу можно прийти по другому.
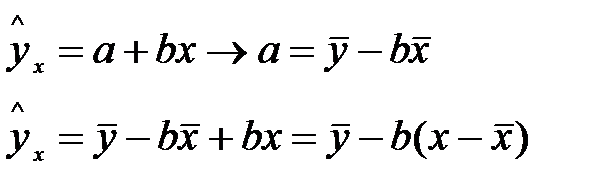
Отсюда следует, что при заданном наборе переменных у и х расчетное значение 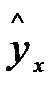 является в линейной регрессии функцией только одного параметра - коэффициента регрессии, поэтому факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
является в линейной регрессии функцией только одного параметра - коэффициента регрессии, поэтому факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.
Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет 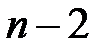 . Число степеней свободы для общей суммы квадратов определяется числом единиц, и т. к. мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, то есть
. Число степеней свободы для общей суммы квадратов определяется числом единиц, и т. к. мы используем среднюю вычисленную по данным выборки, то теряем одну степень свободы, то есть 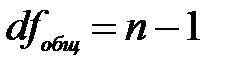 .
.
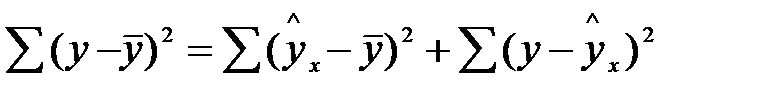
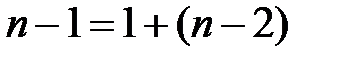
Разделив каждую переменную сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или дисперсию на 1 степень свободы.
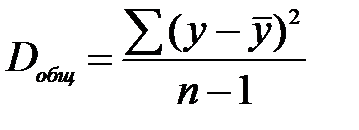 ;
; 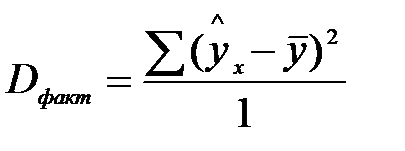 ;
; 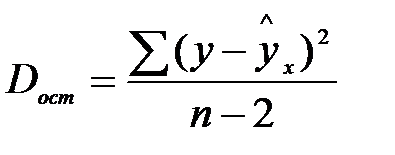 .
.
Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчёте на одну степень свободы, получим величину F-критерия.
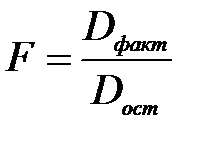
F-критерий для проверки нулевой гипотезы.
Н0 : 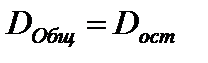 .
.
Если Н0 справедлива, то фактическая и остаточная дисперсии не отличаются друг от друга. Для Н0 необходимо опровержение, чтобы Д факт превышала Д ост в несколько раз.
Английский статистик Снедекор разработал таблицу критических значений F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы.
Вычисленное значение F-отношений признаётся достоверным (отличным от единицы), если оно больше табличного. В этом случае Н0 (отсутствие связи) отклоняется и делается вывод о существенности этой связи: 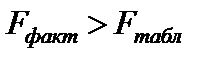 ,
, 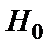 отклоняется.
отклоняется.
Если же 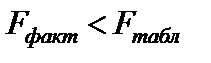 , то вероятность Н0 выше заданного уровня (например 0,05) и она не может быть отклонена без серьёзного риска сделать неправильный вывод о наличии связи.
, то вероятность Н0 выше заданного уровня (например 0,05) и она не может быть отклонена без серьёзного риска сделать неправильный вывод о наличии связи.
Н0 не отклоняется, а уравнение регрессии становится незначимым.
Величина F-критерия связана с коэффициентом детерминации 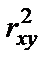 . Факторную сумму квадратов отклонений можно представить как
. Факторную сумму квадратов отклонений можно представить как 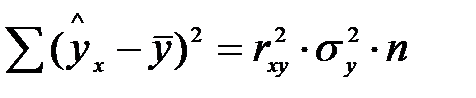 , (
, (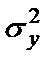 - общая дисперсия y;
- общая дисперсия y; 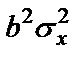 - дисперсия y, обусловленая фактором x (факторная)), а остаточную сумму
- дисперсия y, обусловленая фактором x (факторная)), а остаточную сумму 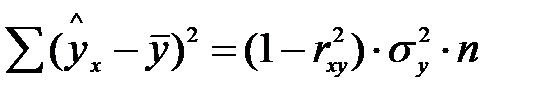 (
(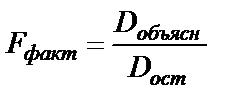 ,
, 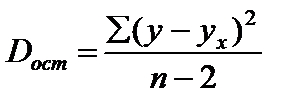 ). Тогда
). Тогда 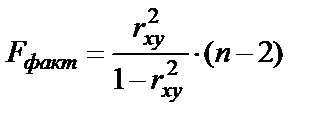 .
.
Оценка значимости уравнения регрессии даётся в виде таблицы дисперсионного анализа.
| Источники вариации | Число степеней свободы |  квадратов отклонений квадратов отклонений | Дисперсия на 1 степень свободы | Fотн | |
| Факт. | Табл.  | ||||
| Общая Объясняющая Остаточная | - | - | - 6,61 - |
В линейной регрессии обычно оценивается значимость не только уравнения в целом, но и отдельных параметров. Поэтому по каждому из параметров определяется его стандартная ошибка: 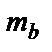 и
и 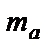 ,
, 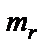 .
.
Стандартная ошибка коэффициента регрессии определяется по формуле: 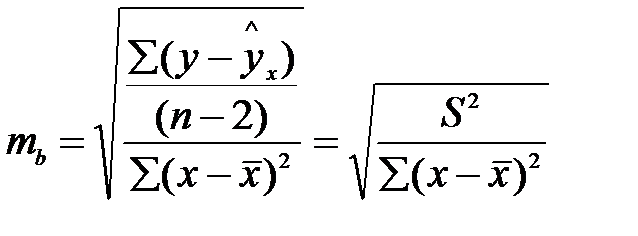 ;
;
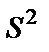 - остаточная дисперсия на одну степень свободы ошибки.
- остаточная дисперсия на одну степень свободы ошибки.
Величина стандартной ошибки совместно с t-распределением Стьюдента при n-2 степенях свободы применяется для проверки существенности коэффициента регрессии и для расчёта его доверительных интервалов.
Для оценки существенности коэффициента регрессии его величина сравнивается со стандартной ошибкой, т.е. определяется фактическое значение t-критерия Стьюдента: 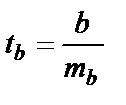 , который сравнивается с табличным значением при определённом уровне значимости
, который сравнивается с табличным значением при определённом уровне значимости 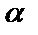 и числе степеней свободы
и числе степеней свободы 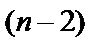 ,
, 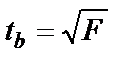 .
.
Если фактическое значение больше табличного, то гипотезу о несущественности коэффициентов отвергаем. Доверительный интервал для коэффициента регрессии b определим по формуле 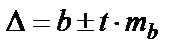 предельная ошибка.
предельная ошибка.

Так как коэффициент регрессии носит в эконометрических исследованиях чётко экономическую интерпретацию, то доверительные интервалы не должны содержать противоречивых результатов, например, 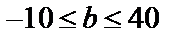 . То есть, что истинное значение коэффициента одновременно содержит положительные, отрицательные величины и даже 0, чего не может быть.
. То есть, что истинное значение коэффициента одновременно содержит положительные, отрицательные величины и даже 0, чего не может быть.
Стандартная ошибка параметра a определяется:
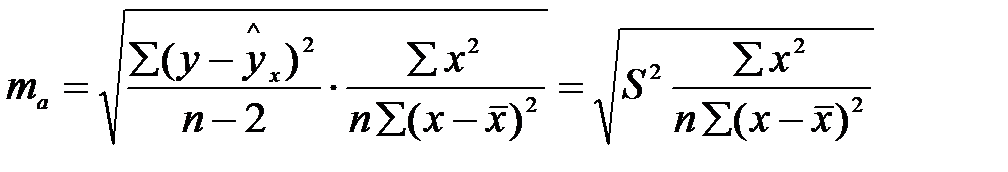
Процедура оценивания не отличается от рассмотренной выше для b.
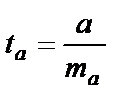 , его величина сравнивается с табличной, при
, его величина сравнивается с табличной, при 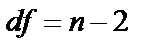 .
.
Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы для каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, то есть о незначительном отличии их от нуля. Оценки значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путём сопоставления их значений с величиной случайной ошибки (S2 остаточная дисперсия на 1 степень свободы, 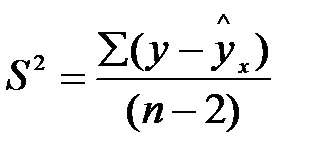 ).
).
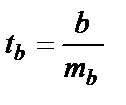 ;
; 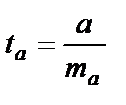 ;
; 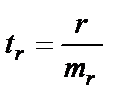 ;
;
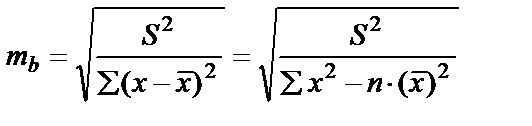 ;
; 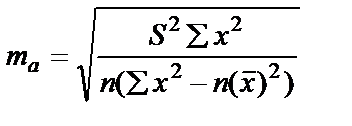 ;
; 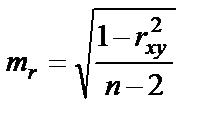 .
.
Сравниваем фактические и критические (табл.) значения и принимаем или отвергаем Н0
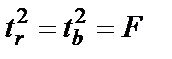
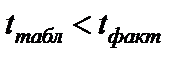 , то Н0 отклоняется, и считается, что
, то Н0 отклоняется, и считается, что  и
и  сформировались под влиянием систем фактора x.
сформировались под влиянием систем фактора x.
Для расчёта доверительного интервала определяем предельную ошибку  для каждого показателя.
для каждого показателя.
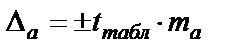 ;
; 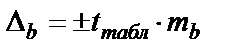 .
.
Формулы для расчёта доверительных интервалов имеют вид:
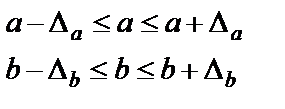
Если в границы доверительного интервала попадает нуль, то есть нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается равный 0, так как не может одновременно принимать положительное и отрицательное значения степенями свободы.
Значимость линейного коэффициента корреляции проверяется на основе величины коэффициента корреляции mr
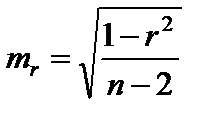 .
.
Фактическое значение t-критерия Стьюдента определяется
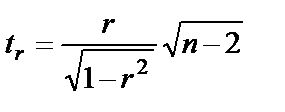 , данная формула свидетельствует, что в парной линейной регрессии
, данная формула свидетельствует, что в парной линейной регрессии 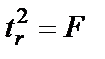 , ибо
, ибо 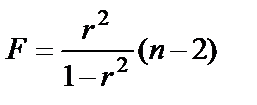 , а также
, а также 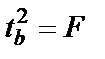 , следовательно
, следовательно 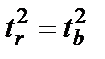 .
.
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения.
Если 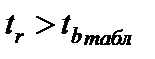 при
при 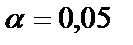 . То есть коэффициент а существенно отличен от нуля – является правильной, а зависимость достоверной.
. То есть коэффициент а существенно отличен от нуля – является правильной, а зависимость достоверной.
Рассмотренная формула оценки коэффициента корреляции рекомендуется к применению при большом числе наблюдений и если r не близко к +1 или -1. Если 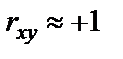 , то распределение его оценок отличается от нормального или распределения Стьюдента, так как величина
, то распределение его оценок отличается от нормального или распределения Стьюдента, так как величина 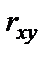 ограничена значениями (-1; +1). Чтобы обойти это затруднение Р. Фишером было предложено для оценки существенности ввести вспомогательную величину z, связанную с следующим отношением
ограничена значениями (-1; +1). Чтобы обойти это затруднение Р. Фишером было предложено для оценки существенности ввести вспомогательную величину z, связанную с следующим отношением
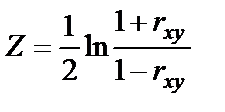
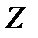 изменяется
изменяется  , что соответствует нормальному распределению. Стандартная ошибка величины
, что соответствует нормальному распределению. Стандартная ошибка величины 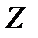 определяется
определяется 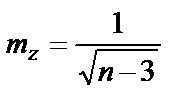 , где n – число наблюдений.
, где n – число наблюдений.
При r = 0,991 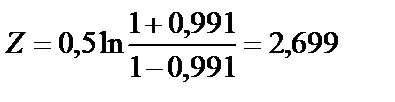
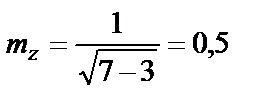 .
.
Z можно взять в таблице для соответствующего значения r.
Выдвигаем гипотезу H0 – корреляция отсутствует: 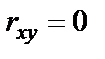 .
.
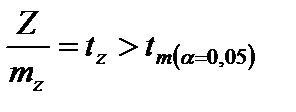 , то есть фактическое значение
, то есть фактическое значение 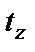 превышает его табличное значение на уровне значимости
превышает его табличное значение на уровне значимости 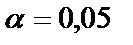 и
и 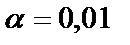 .
.
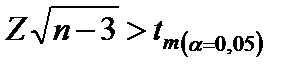
В виду того, что r и z связаны между собой приведённым выше отношением, можно вычислить критические значения r, соответствующие каждому из значений z. Таблицы критических значений r разработаны для уровней значимости 0,05 и 0,01 и соответствующего числа степеней свободы. Критические значения предполагают справедливость нулевой гипотезы, то есть мало отличается от нуля. Если фактическое значение коэффициента по абсолютной величине превышает табличное, то данное значение считается существенным.
Если же 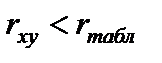 , то фактическое значение r несущественно.
, то фактическое значение r несущественно.
Интервалы прогноза по линейному уравнению регрессии.
В прогнозных расчётах по уравнению регрессии определяется то, что 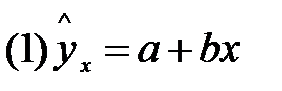 уравнение не является реальным, для
уравнение не является реальным, для 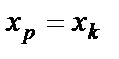 есть ещё стандартная ошибка
есть ещё стандартная ошибка 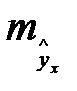 . Поэтому интервальная оценка прогнозного значения
. Поэтому интервальная оценка прогнозного значения 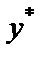
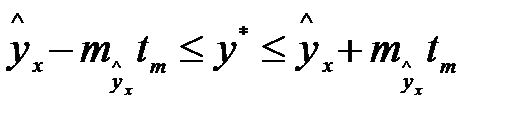
Выразим из уравнения 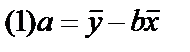
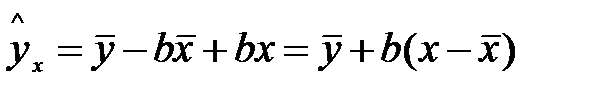 , то есть стандартная ошибка
, то есть стандартная ошибка 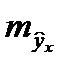 зависит
зависит  и ошибки коэффициента регрессии b,
и ошибки коэффициента регрессии b,
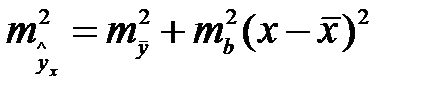 .
.
Из теории выборки известно, что 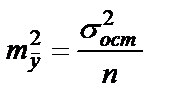 . Используя в качестве оценки
. Используя в качестве оценки 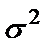 остаточную дисперсию на одну степень свободы , получим формулу расчёта ошибки среднего значения переменной y:
остаточную дисперсию на одну степень свободы , получим формулу расчёта ошибки среднего значения переменной y: 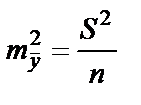 .
.
Ошибка коэффициента регрессии: 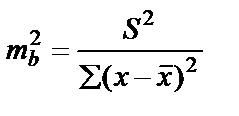 .
.
В прогнозных расчетах по уравнению регрессии определяется уравнение как точечный прогноз 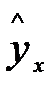 при , то есть путём подстановки в уравнение регрессии
при , то есть путём подстановки в уравнение регрессии 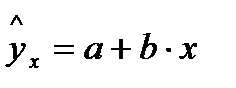 . Однако точечный прогноз явно нереален.
. Однако точечный прогноз явно нереален.
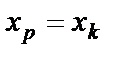
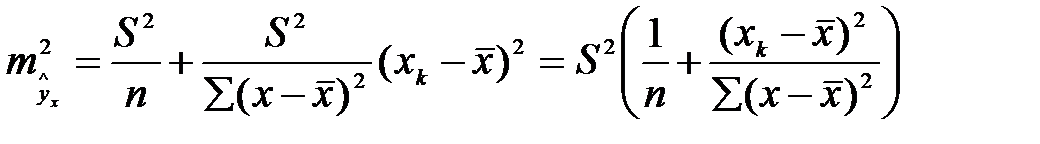
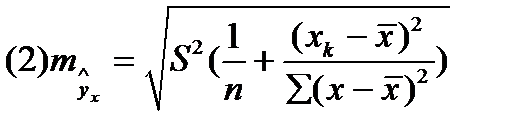 - формула стандартной ошибки предсказываемого значения y при заданных
- формула стандартной ошибки предсказываемого значения y при заданных 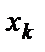 , характеризует ошибку положения линии регрессии. Величина стандартной ошибки
, характеризует ошибку положения линии регрессии. Величина стандартной ошибки 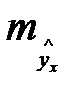
 , достигает min при
, достигает min при 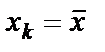 , и возрастает по мере того, как «удаляется» от
, и возрастает по мере того, как «удаляется» от 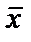 в любом направлении. То есть чем больше разность между и x, тем больше ошибка
в любом направлении. То есть чем больше разность между и x, тем больше ошибка 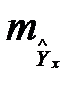 , с которой предсказывается среднее значение y для заданного значения .
, с которой предсказывается среднее значение y для заданного значения .
Можно ожидать наилучшие результаты прогноза, если признак - фактор x находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении от .
Если же значение оказывается за пределами наблюдаемых значений х, используемых при построении ЛР, то результаты прогноза ухудшаются в зависимости то того, насколько отклоняется от области наблюдаемых значений фактора х. Доверит. интервалы при 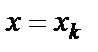 .
.
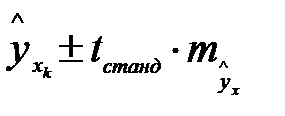
На графике доверительной границы  представляет собой гиперболы, расположенные по обе стороны от линии регрессии.
представляет собой гиперболы, расположенные по обе стороны от линии регрессии.
| Доверит. интервал |
| Нижняя доверит. граница |
| ЛР |
| Верхняя доверит. граница |
| xk |
| x |
| y |
Две гиперболы по обе стороны от линии регрессии определяют 95%-ные доверительные интервалы для среднего значения y при заданном значении x.
Однако фактические значения y варьируют около среднего значения  . Индивидуальные значения y могут отклоняться от
. Индивидуальные значения y могут отклоняться от  на величину случайной ошибки
на величину случайной ошибки 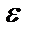 , дисперсия которой оценивается как остаточная дисперсия на одну степень свободы . Поэтому ошибка предсказываемого индивидуального значения y должна включать не только стандартную ошибку
, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы . Поэтому ошибка предсказываемого индивидуального значения y должна включать не только стандартную ошибку 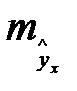 , но и случайную ошибку.
, но и случайную ошибку.
Средняя ошибка прогнозируемого индивидуального значения y 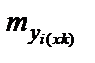 составит:
составит:
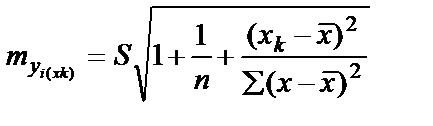 .
.
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения y, но и от точности прогноза значений фактора x.
Его величина может задаваться на основе анализа других моделей, исходя из конкретной ситуации, а также из анализа динамики данного фактора.
Рассмотренная формула средней ошибки индивидуального значения признака y () может быть использована также для оценки существенности различия предсказываемого значения исходя из регрессионной модели и выдвинутой гипотезы развития событий.
Понятие о множественной регрессии. Классическая линейная модель множественной регрессии (КЛММР). Определение параметров уравнения множественной регрессии методом наименьших квадратов.
Парная регрессия используется при моделировании, если влиянием других факторов, воздействующих на объект исследования можно пренебречь.
Например, при построении модели потребления того или иного товара от дохода, исследователь предполагает, что в каждой группе дохода одинаково влияние на потребление таких факторов, как цена товара, размер семьи, ее состав. Однако, уверенности в справедливости данного утверждения нет.
Прямой путь решения такой задачи состоит в отборе единиц совокупности с одинаковыми значениями всех других факторов, кроме дохода. Он приводит к планированию эксперимента – метод, который используется в естественнонаучных исследованиях. Экономист лишен возможности регулировать другие факторы. Поведение отдельных экономических переменных контролировать нельзя, т.е. не удается обеспечить равенство прочих условий для оценки влияния одного исследуемого фактора.
Как поступить в этом случае? Надо выявить влияние других факторов, введя их в модель, т.е. построить уравнение множественной регрессии.
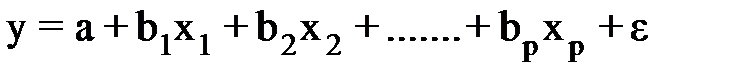
Такого рода уравнения используется при изучении потребления.
Коэффициенты bj – частные производные у по факторами хi
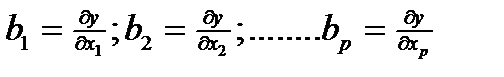 при условии, что все остальные хi = const
при условии, что все остальные хi = const
Рассмотрим современную потребительскую функцию (впервые 30е годы предложил Кейнс Дж.М.) как модель вида С = f(y,P,M,Z)
c - потребление. у – доход
P – цена, индекс стоимости.
M – наличные деньги
Z – ликвидные активы
При этом 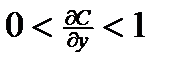
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функций издержек производства, в макроэкономических вопросах и других вопросах эконометрики.
В настоящее время множественная регрессия – один из наиболее распространенных методов в эконометрике.
Основная цель множественной регресси – построить модель с большим числом факторов, определив при этом влияние каждого их них в отдельности, а также совокупное воздействие на моделируемый показатель.
Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели.
Она включает в себя два круга вопросов:
1. Отбор факторов;
2. Выбор уравнения регрессии.
Включение в уравнение множественной регрессии того или иного набора факторов связано с представлением исследователя о природе взаимосвязи моделируемого показателя с другими экономическими явлениями. Требования к факторам, включаемым во множественную регрессию:
1. они должны быть количественно измеримы, если необходимо включить в модель качественный фактор, не имеющий количественного измерения, то ему нужно придать количественную определенность (например, в модели урожайности качество почвы задается в виде баллов; в модели стоимости объектов недвижимости: районы должны быть проранжированы).
2. факторы не должны быть интеркоррелированы и тем более находиться в точной функциональной связи.
Включение в модель факторов с высокой интеркорреляцией, когда Rуx1<Rx1x2 для зависимости 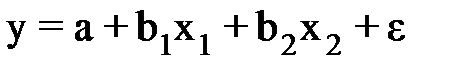 может привести к нежелательным последствиям – система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии.
может привести к нежелательным последствиям – система нормальных уравнений может оказаться плохо обусловленной и повлечь за собой неустойчивость и ненадежность оценок коэффициентов регрессии.
Если между факторами существует высокая корреляция, то нельзя определить их изолированное влияние на результативный показатель и параметры уравнения регрессии оказываются интерпретируемыми.
В уравнение 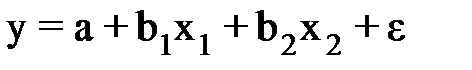 предполагается, что факторы х1 и х2 независимы друг от друга, rх1х2 = 0, тогда параметр b1 измеряет силу влияния фактора х1 на результат у при неизменном значении фактора х2. Если rх1х2 =1, то с изменением фактора х1 фактор х2 не может оставаться неизменным. Отсюда b1 и b2 нельзя интерпретировать как показатели раздельного влияния х1 и х2 и на у.
предполагается, что факторы х1 и х2 независимы друг от друга, rх1х2 = 0, тогда параметр b1 измеряет силу влияния фактора х1 на результат у при неизменном значении фактора х2. Если rх1х2 =1, то с изменением фактора х1 фактор х2 не может оставаться неизменным. Отсюда b1 и b2 нельзя интерпретировать как показатели раздельного влияния х1 и х2 и на у.
Пример, рассмотрим регрессию себестоимости единицы продукции у (руб.) от заработной платы работника х (руб.) и производительности труда z (ед. в час).
у = 22600 - 5x - 10z + e
коэффициент b2 = -10, показывает, что с ростом производительности труда на 1 ед. себестоимость единицы продукции снижается на 10 руб. при постоянном уровне оплаты.
Вместе с тем параметр при х нельзя интерпретировать как снижение себестоимости единицы продукции за счет роста заработной платы. Отрицательное значение коэффициента регрессии при переменной х обусловлено высокой корреляцией между х и z (rхz = 0,95). Поэтому роста заработной платы при неизменности производительности труда (не учитывая инфляции) быть не может.
Включенные во множественную регрессию факторы должны объяснить вариацию независимой переменной. Если строиться модель с набором р факторов, то для нее рассчитывается показатель детерминации R2, которая фиксирует долю объясненной вариации результативного признака за счет рассматриваемых в регрессии р факторов. Влияние других неучтенных в модели факторов оценивается как 1-R2 c соответствующей остаточной дисперсией S2.
При дополнительном включении в регрессию р+1 фактора коэффициент детерминации должен возрастать, а остаточная дисперсия уменьшается.
R2p+1≥ R2p и S2p+1 ≤ S2p.
Если же этого не происходит и данные показатели практически мало отличаются друг от друга, то включенный в анализ фактор xр+1 не улучшает модель и практически является лишним фактором.
Если для регрессии, включающей 5 факторов R2 = 0,857, и включенный 6 дало R2 = 0,858, то нецелесообразно включать в модель этот фактор.
Насыщение модели лишними факторами не только не снижает величину остаточной дисперсии и не увеличивает показатель детерминации, но и приводит к статистической не значимости параметров регрессии по критерию t-Стьюдента.
Таким образом, хотя теоретически регрессионная модель позволяет учесть любое число факторов, практически в этом нет необходимости.
Отбор факторов производиться на основе теоретико-экономического анализа. Однако, он часто не позволяет однозначно ответить на вопрос о количественной взаимосвязи рассматриваемых признаков и целесообразности включения фактора в модель.
Поэтому отбор факторов осуществляется в две стадии:
- на первой – подбирают факторы, исходя из сущности проблемы.
- на второй – на основе матрицы показателей корреляции определяют t-статистики для параметров регрессии.
Коэффициенты интеркоррелиции (т.е. корреляция между объясняющими переменными) позволяют исключить из моделей дублирующие факторы. Считается, что две переменные явно коллинеарны, т.е. находятся между собой в линейной зависимости, если rxixj ≥0,7.
Поскольку одним из условий построения уравнения множественной регрессии является независимость действия факторов, т.е. rхixj = 0, коллинеарность факторов нарушает это условие. Если факторы явно коллинеарны, то они дублируют друг друга и один из них рекомендуется исключить из регрессии.
Предпочтение при этом отдается не фактору, более тесно связанному с результатом, а тому фактору, который при достаточно тесной связи с результатом имеет наименьшую тесноту связи с другими факторами. В этом требовании проявляется специфика множественной регрессии как метода исследования комплексного воздействия факторов в условиях их независимости друг от друга.
Рассмотрим матрицу парных коэффициентов корреляции при изучении зависимости у = f(x, z, v)
| y | x | z | V | |
| Y | ||||
| X | 0,8 | |||
| Z | 0,7 | 0,8 | ||
| V | 0,6 | 0,5 | 0,2 |
Очевидно, факторы x и z дублируют друг друга. В анализ целесообразно включит фактор z, а не х, так как корреляция z с у слабее чем корреляция фактора х с у (rуz < rух), но зато слабее межфакторная корреляция (rzv< rхv)
Поэтому в данном случае в уравнение множественной регрессии включает факторы z и v. По величине парных коэффициентов корреляции обнаруживается лишь явная коллинеарность факторов. Но наиболее трудности возникают при наличии мультиколлинеарности факторов, когда более чем два фактора связаны между собой линейной зависимостью, т.е. имеет место совокупное воздействие факторов друг на друга.
Наличие мультиколлинеарности факторов может означать, что некоторые факторы будут всегда действовать в унисон. В результате вариация в исходных данных перестает быть полностью независимой, и нельзя оценить воздействие каждого фактора в отдельности. Чем сильнее мультиколлинеарности факторов, тем менее надежна оценка распределения суммы объясненной вариации по отдельным факторам с помощью МНК.
Если рассмотренная регрессия у = a + bx + cx + dv + e, то для расчета параметров, применяется МНК
Sy = Sфакт +Se
или 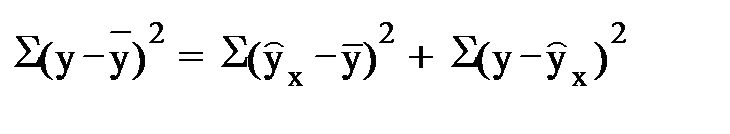 = +
= +
общая сумма = факторная + остаточная

