2014-02-01
2014-02-01 1628
1628Сущность и причины автокорреляции в остатках
Автокорреляция в остатках обычно встречается при регрессионном анализе временных рядов, и почти не встречается при анализе пространственных выборок. Чаще встречается положительная автокорреляция. Она в большинстве случаев вызывается направленным постоянным воздействием некоторых неучтенных в модели факторов. При положительной автокорреляции остатки изменяются монотонно с течением времени наблюдения, а при отрицательной – следует частое изменение знака остатка.
Среди основных причин автокорреляции можно выделить следующие:
а) ошибки спецификации – неучет в модели какой-то важной объясняющей переменной или неверный выбор вида функции, что ведет к систематическим отклонениям точек наблюдения от линии регрессии,
б) инерция – запаздывание реакции экономической системы на изменение факторов,
в) сглаживание данных.
Последствия автокорреляции в остатках такие же, как и в случае гетероскедастичности (потеря эффективности, смещение дисперсий оценок параметров, занижение стандартных ошибок и завышение t –статистик параметров), а это может повлечь признание незначимых факторов значимыми. Вследствие перечисленных обстоятельств, прогнозные качества модели ухудшаются.
При анализе временных рядов вместо индекса i часто будем использовать время t, а вместо числа наблюдений n будем писать 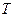 – продолжительность интервала наблюдения временного ряда.
– продолжительность интервала наблюдения временного ряда.
Мы будем рассматривать автокорреляцию первого порядка, так как в большинстве практических случаев автокорреляционная функция быстро убывает.
Коэффициент автокорреляции 1-го порядка в остатках:
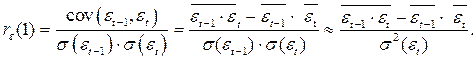
Если этот коэффициент корреляции существенно отличен от 0, то можно говорить о наличии автокорреляции.
Обнаружение автокорреляции в остатках
1. Графический метод – при использовании этого метода строится график: εt есть функция от εt– 1. Если в графике прослеживается отчетливая положительная или отрицательная тенденция, то, скорее всего, имеет место соответствующая автокорреляция в остатках.
2. Метод рядов
В моменты времени 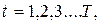 определяются знаки отклонений, например:
определяются знаки отклонений, например:
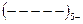
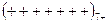
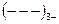
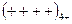
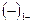 – для 20-ти наблюдений.
– для 20-ти наблюдений.
Рядом называют непрерывную последовательность одинаковых знаков (ряд ограничен скобками, в примере приведено 5 рядов). Количество знаков называют длиной ряда. Если рядов мало по сравнению с числом наблюдений, то вполне вероятна положительная автокорреляция, если рядов много, – то отрицательная.
Для более детального анализа используется следующая процедура:
Пусть 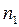 - число знаков «+»,
- число знаков «+»,
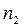 - число знаков «–»,
- число знаков «–»,
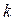 - количество рядов.
- количество рядов.
При достаточном количестве наблюдений 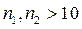 и при отсутствии автокорреляции в остатках случайная величина имеет асимптотически нормальное распределение со следующими параметрами:
и при отсутствии автокорреляции в остатках случайная величина имеет асимптотически нормальное распределение со следующими параметрами:
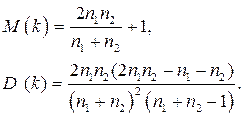
Тогда, если k лежит внутри интервала
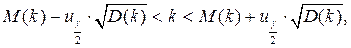 то гипотеза
то гипотеза 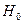 об отсутствии автокорреляции не отклоняется; если лежит левее данного интервала, то есть положительная автокорреляция, а если правее – то отрицательная автокорреляция. Здесь γ – уровень значимости гипотезы об отсутствии автокорреляции. Для небольших и
об отсутствии автокорреляции не отклоняется; если лежит левее данного интервала, то есть положительная автокорреляция, а если правее – то отрицательная автокорреляция. Здесь γ – уровень значимости гипотезы об отсутствии автокорреляции. Для небольших и 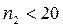 существует таблица Сведа–Эйзенхарта, в которой по значениям и
существует таблица Сведа–Эйзенхарта, в которой по значениям и 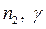 находятся
находятся 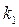 и
и 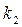 .
.
Если k 1 < k < k 2 , то автокорреляция отсутствует, если k < k 1 – есть положительная автокорреляция, если k > k 2 – есть отрицательная автокорреляция.
3. Тест Дарбина-Уотсона (DW). Это – самый популярный тест: 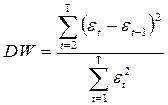 - критерий Дарбина – Уотсона.
- критерий Дарбина – Уотсона.
Установим связь между этим критерием и коэффициентом корреляции:
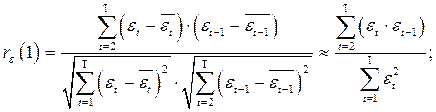 учитывая, что
учитывая, что 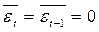 и
и 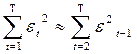 , получим:
, получим:
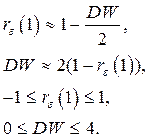
Процедура обнаружения автокорреляции по критерию DW такова:
1. Вычисляется критерий DW, для чего должна быть выполнена регрессия y на x и определены остатки. Затем выдвигается гипотеза 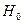 об отсутствии автокорреляции в остатках.
об отсутствии автокорреляции в остатках.
2. По таблице критических значений теста Дарбина–Уотсона для назначенного уровня значимости γ, числа наблюдений n и числа факторов p определяются верхняя du и нижняя dl критические точки 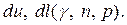
3. Строятся области: I–от 0 до dl; II–от dl до du; III–от du до 4– du; IV– от 4– ul до 4– dl и V–от 4– dl до 4.
Это поясняется табл. 9.1.
таблица 9.1
| I (+) автокорреляция | II неопределенность | III нет автокорреляции | IV неопределенность | V (–) автокорреляция |
| 0 … dl | dl … du | du …(4 – du) | 4– du …4– dl | 4– dl … 4 |
При использовании критерия 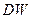 следует учитывать следующие ограничения:
следует учитывать следующие ограничения:
а) он применим лишь для модели с ненулевым свободным членом,
б) остатки должны описываться авторегрессионной моделью первого порядка 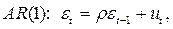
в) временной ряд должен иметь одинаковую периодичность, то есть не должно быть пропусков наблюдений,
г) нельзя применять для моделей авторегрессионных относительно объясняемой переменной yt, так как в этом случае окажется, что регрессор будет коррелировать с остатком.
Поясним это:
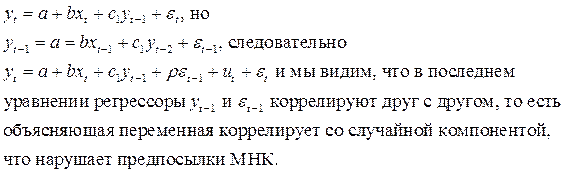
Для авторегрессионных моделей существует следующая h– статистика Дарбина:
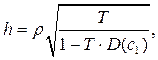 где
где 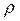 - коэффициент авторегрессии, - количество наблюдений,
- коэффициент авторегрессии, - количество наблюдений, 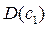 – дисперсия коэффициента c 1 в уравнении авторегрессии yt = a + bxt + c 1 y t - 1 +…+ εt, c 1 – коэффициент при
– дисперсия коэффициента c 1 в уравнении авторегрессии yt = a + bxt + c 1 y t - 1 +…+ εt, c 1 – коэффициент при 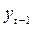 в упомянутом уравнении.
в упомянутом уравнении.
Как использовать h- статистику?
Для назначенного уровня значимости γ выдвигают гипотезу об отсутствии автокорреляции в остатках, т.е. полагают, что 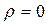 в модели AR(1) остатков и статистика h имеет стандартное нормальное распределение:
в модели AR(1) остатков и статистика h имеет стандартное нормальное распределение: 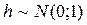 .
.
По таблице функции Лапласа 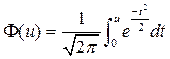 определяют критическую точку
определяют критическую точку 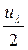 такую, что
такую, что 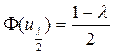 . Если
. Если 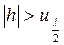 , то
, то 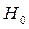 отклоняется. В противном случае не отклоняется и автокорреляция не признается.
отклоняется. В противном случае не отклоняется и автокорреляция не признается.
Методы устранения автокорреляции
1. Обобщенный МНК (ОМНК)
Рассмотрим исходную модель в моменты времени t и t –1: 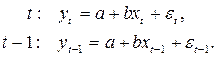
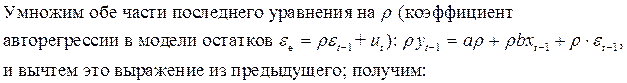
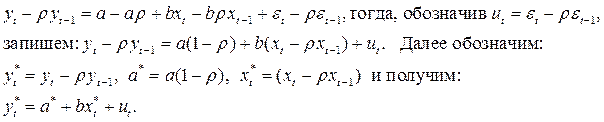
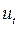 – есть случайная величина, так как
– есть случайная величина, так как 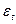 и
и 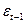 – случайные величины,
– случайные величины,
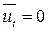 , так как
, так как 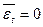 и
и 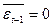 .
.
Остаток не коррелирует ни с одним регрессором, следовательно, можно применить классический МНК. Оценка параметра b вычисляется непосредственно, а оценка параметра a вычисляется так: 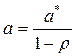 .
.
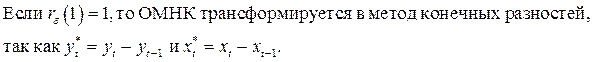
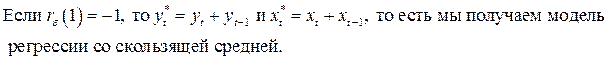
ОМНК может применяться для данных, начиная с момента 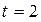 , т.е. первое наблюдение теряется; его можно восстановить для
, т.е. первое наблюдение теряется; его можно восстановить для 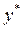 и
и 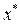 , используя поправку Прайса–Уинстена:
, используя поправку Прайса–Уинстена:
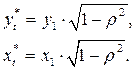
Если наше предположение о том, что остатки описанные 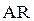 – моделью первого порядка соответствуют действительности, то можно показать, что
– моделью первого порядка соответствуют действительности, то можно показать, что 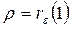 .
.
При большой протяженности временного ряда значенияи 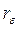 действительно оказываются близки друг к другу. В матричной форме отыскание столбца B с помощью ОМНК выражается так:
действительно оказываются близки друг к другу. В матричной форме отыскание столбца B с помощью ОМНК выражается так:
B = (X T Ω ρ X) -1 X T Ω ρ Y, где
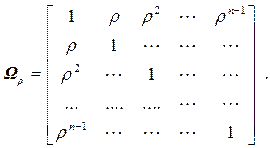
2. Метод Кохрана – Оркатта (итерационный)
Первая итерация: вначале по МНК оценивается регрессия 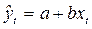 . Определяются столбец остатков
. Определяются столбец остатков 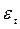 и столбец
и столбец 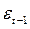 . Далее оценивается авторегрессия остатков по схеме
. Далее оценивается авторегрессия остатков по схеме 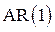 :
:
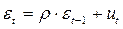 , отсюда находится оценка .
, отсюда находится оценка .
Вторая итерация: Введем новые переменные: wt = yt – ρyt- 1, zt = xt – ρxt- 1.
Построим регрессию 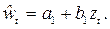 По ней определим (ε 1) t и (ε 1) t- 1. Далее опять построим авторегрессию остатков
По ней определим (ε 1) t и (ε 1) t- 1. Далее опять построим авторегрессию остатков 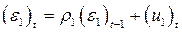 , отсюда находим оценку ρ 1.
, отсюда находим оценку ρ 1.
Третья итерация: Опять введем новые переменные (w 1) t = wt – ρ 1 wt– 1,
(z 1) t = zt – ρ 1 zt –1 и построим регрессию 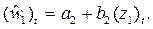 По ней определим
По ней определим
остатки (ε 2) t и (ε 2) t- 1. Построим авторегрессию остатков 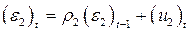 и по ней найдем оценку ρ 2.
и по ней найдем оценку ρ 2.
Итерационный процесс продолжается до тех пор, пока разность между предыдущей и последующей оценками ρ не станет по модулю меньше любого наперед заданного числа. После того, как определено значение ρ, строится регрессия по уже знакомой модели:
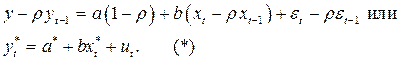
Применяя к этому уравнению классический МНК находим 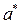 и
и 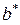 , рассчитываем значение
, рассчитываем значение 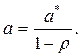
3. Метод Хилдрета-Лу
Этот метод предполагает перебор значений 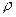 с достаточно малым шагом, например, 0,01 и подстановку его в уравнение (*). Та величина , при которой стандартная ошибка регрессии в данной модели будет наименьшей, принимается в качестве наилучшей оценки
с достаточно малым шагом, например, 0,01 и подстановку его в уравнение (*). Та величина , при которой стандартная ошибка регрессии в данной модели будет наименьшей, принимается в качестве наилучшей оценки