 2015-01-30
2015-01-30 8785
8785Пакет MS Excel позволяет при построении уравнения линейной регрессии большую часть работы сделать очень быстро. Важно понять, как интерпретировать полученные результаты.
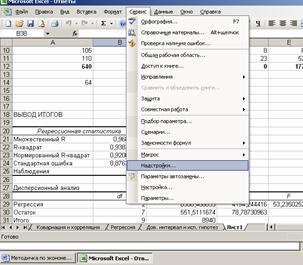
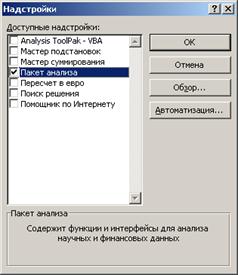
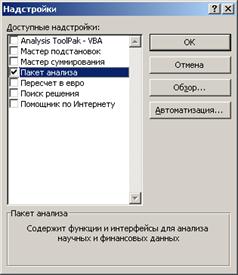
Для работы необходима надстройка Пакет анализа, которую необходимо включить в пункте меню Сервис\Надстройки
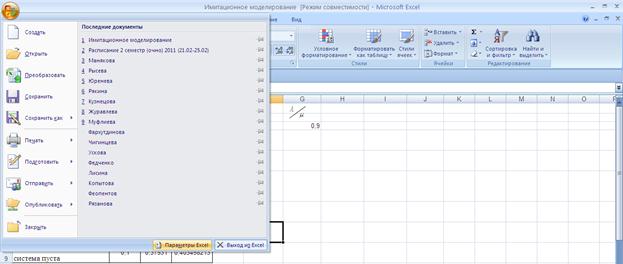
В Excel 2007 для включения пакета анализа надо нажать перейти в блок Параметры Excel, нажав кнопку в левом верхнем углу, а затем кнопку «Параметры Excel» внизу окна:



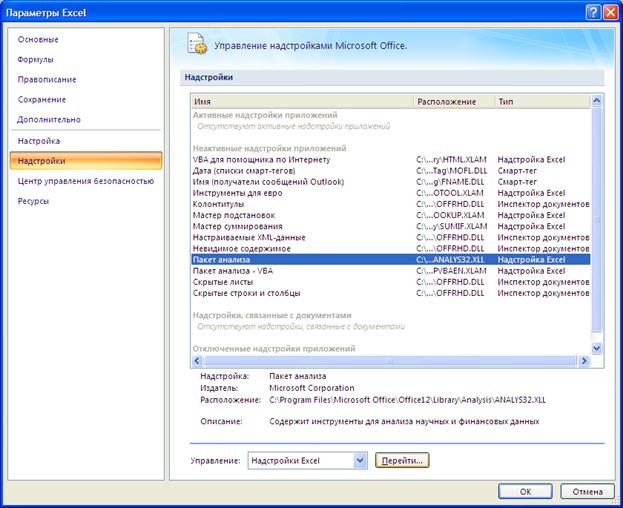
Далее в открывшемся списке нужно выбрать Надстройки, затем установить курсор на пункт Пакет анализа, нажать кнопку Перейти и в следующем окне включить пакет анализа.
Для построения модели регрессии необходимо выбрать пункт Сервис\Анализ данных\Регрессия. (В Excel 2007 этот режим находится в блоке Данные/Анализ данных/ Регрессия). Появится диалоговое окно, которое нужно заполнить:
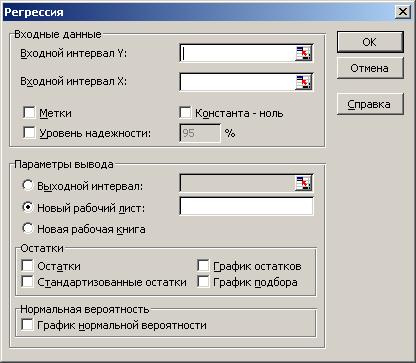
1) Входной интервал Y ¾ содержит ссылку на ячейки, которые содержат значения результативного признака y. Значения должны быть расположены в столбце;
2) Входной интервал X ¾ содержит ссылку на ячейки, которые содержат значения факторов 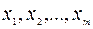
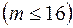 . Значения должны быть расположены в столбцах;
. Значения должны быть расположены в столбцах;
3) Признак Метки ставится, если первые ячейки содержат пояснительный текст (подписи данных);
4) Уровень надежности ¾ это доверительная вероятность, которая по умолчанию считается равной 95%. Если это значение не устраивает, то нужно включить этот признак и ввести требуемое значение;
5) Признак Константа-ноль включается, если необходимо построить уравнение, в котором свободная переменная 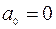 ;
;
6) Параметры вывода определяют, куда должны быть помещены результаты. По умолчанию строит режим Новый рабочий лист;
7) Блок Остатки позволяет включать вывод остатков и построение их графиков.
В результате выводится информация, содержащая все необходимые сведения и сгруппированная в три блока: Регрессионная статистика, Дисперсионный анализ, Вывод остатка. Рассмотрим их подробнее.
1. Регрессионная статистика:
множественный R определяется формулой 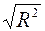 (коэффициент корреляции Пирсона);
(коэффициент корреляции Пирсона);
R -квадрат вычисляется по формуле 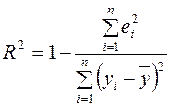 (коэффициент детерминации);
(коэффициент детерминации);
Нормированный R -квадрат вычисляется по формуле 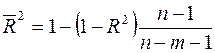 (используется для множественной регрессии);
(используется для множественной регрессии);
Стандартная ошибка S вычисляется по формуле 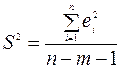 ;
;
Наблюдения ¾ это количество данных n.
2. Дисперсионный анализ, строка Регрессия:
Параметр df равен m (количество наборов факторов x);
Параметр SS определяется формулой 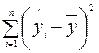 ;
;
Параметр MS определяется формулой 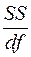 ;
;
Статистика F определяется формулой 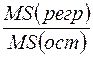 ;
;
Значимость F. Если полученное число превышает 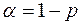 , то принимается гипотеза
, то принимается гипотеза 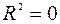 (нет линейной взаимосвязи), иначе принимается гипотеза
(нет линейной взаимосвязи), иначе принимается гипотеза 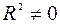 (есть линейная взаимосвязь).
(есть линейная взаимосвязь).
3. Дисперсионный анализ, строка Остаток:
Параметр df равен 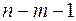 ;
;
Параметр SS определяется формулой 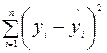 ;
;
Параметр MS определяется формулой .
4. Дисперсионный анализ, строка Итого содержит сумму первых двух столбцов.
5. Дисперсионный анализ, строка Y-пересечение содержит значение коэффициента 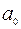 , стандартной ошибки
, стандартной ошибки 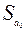 и t -статистики
и t -статистики 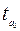 .
.
P -значение ¾ это значение уровней значимости, соответствующее вычисленным t -статистикам. Определяется функцией СТЬЮДРАСП(t -статистика; ). Если P -значение превышает , то соответствующая переменная статистически незначима и ее можно исключить из модели.
Нижние 95% и Верхние 95% ¾ это нижние и верхние границы 95-процентных доверительных интервалов для коэффициентов теоретического уравнения линейной регрессии. Если в блоке ввода данных значение доверительной вероятности было оставлено по умолчанию, то последние два столбца будут дублировать предыдущие. Если пользователь ввел свое значение доверительной вероятности, то последние два столбца содержат значения нижней и верхней границы для указанной доверительной вероятности.
6. Дисперсионный анализ, строки содержат значения коэффициентов, стандартных ошибок, t -статистик, P -значений и доверительных интервалов для соответствующих 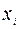 .
.
7. Блок Вывод остатка содержит значения предсказанного y (в наших обозначениях это 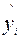 ) и остатки
) и остатки 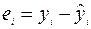 .
.

