 2015-05-18
2015-05-18 3831
3831Сложность и многообразие реальных процессов обуславливают необходимость их упрощения, схематизации и идеализации, т.е. абстрагирования от несущественных второстепенных деталей. Такое абстрагирование позволяет получить модель процесса. В последние десятилетия математическое моделирование широко проникло в теоретическую и прикладную экономику.
Термин «модель» широко используется в различных областях человеческой деятельности. Модель – материально или мысленно представляемый объект, который в процессе исследования замещает объект – оригинал так, что его непосредственное изучение дает новые знания об объекте-оригинале.
Под моделированием понимается процесс построения, исследования и применения моделей. Главная особенность моделирования в том, что это метод опосредованного познания с помощью объектов-заменителей.
Необходимость использования метода моделирования определяется тем, что многие объекты непосредственно исследовать невозможно (например, ядро Земли), опасно (ядерный реактор, эпидемический процесс) или весьма трудоемко.
Математические модели описывают взаимосвязи между переменными, характеризующими объект, на языке математики (в виде формул и математических операций). Полезность математических моделей состоит в том, что с их помощью удается выразить зависимости между различными величинами, в частности в виде функций.
Математические модели - мощный инструмент познания реального мира, так как позволяют просчитывать на ЭВМ большое число различных вариантов. Они должны учитывать основные стороны и взаимосвязи объекта и пренебрегать несущественными. Разработка моделей – большое искусство.
Математические модели можно классифицировать по различным признакам:
- по цели моделирования (проведение расчетов, проектирование систем, исследование объекта, открытие закономерностей, прогнозирование развития объекта, управление процессами, в том числе принятие решений, диагностика (распознавание) объектов или их классификация);
- детерминистические и стохастические;
- статические и динамические.
Динамические модели, учитывающие в явном виде фактор времени, могут использоваться для прогнозирования различных процессов.
Задача построения модели какого-либо объекта состоит в нахождении соотношений между величинами, характеризующими объект. Если эти соотношения позволяют по данным значениям одних величин однозначно определить значения других, то описываемая ими модель называется детерминистической. Если же эти соотношения по данным значениям одних величин определяют другие как случайные величины, то описываемая ими модель называется стохастической.
Построение детерминистических моделей основано на выводе математической зависимости исследуемого показателя от основных определяющих факторов, носящих неслучайный характер. Стохастические модели учитывают вероятностный характер изменения показателей и, в отличие от детерминистических моделей, представляют результат в виде набора вероятностей различных значений показателя или плотности распределения вероятностей.
Cложность процессов функционирования реальных систем не позволяет достичь абсолютного соответствия модели реальному объекту. Математические модели в состоянии учесть только основные закономерности процесса, оставляя в стороне второстепенные факторы. Основной принцип разработки моделей - компромисс между ожидаемой точностью результатов (детализацией модели) и ее сложностью.
Можно выделить два способа построения математических моделей:
- на основе статистической обработки результатов исследований;
- на основе известных законов физики или логических соображений.
Для эконометрики характерен первый способ построения моделей.
2. КОРРЕЛЯЦИОННЫЙ И РЕГРЕССИОННЫЙ АНАЛИЗ
2.1. ФУНКЦИОНАЛЬНАЯ И СТАТИСТИЧЕСКАЯ ЗАВИСИМОСТЬ
Во многих науках (физика, экономика и т. д.) используются модели, в которых некоторые переменные (не случайные) связаны функциональной зависимостью. Примером таких зависимостей является закон Бойля-Мариотта или формула Ф. Котлера.
При статистической зависимости переменные (случайные величины) не связаны функционально. Однако закон распределения одной из них зависит от того, какое значение приняла другая случайная величина. Поэтому речь идет об условном распределении Y при заданном х.
В частности, можно рассматривать условное математическое ожидание M(Y/ x) как некоторую функцию х. Такая зависимость называется регрессией.
При исследовании статистической зависимости между переменными пытаются ответить на следующие вопросы:
- существует ли статистическая связь между переменными;
- какова степень этой связи;
- какова форма связи.
Первые два вопроса решаются на основании корреляционного анализа.
2.2. КОРРЕЛЯЦИОННЫЙ АНАЛИЗ
В качестве меры тесноты связи между двумя случайными величинами обычно используется коэффициент корреляции - r
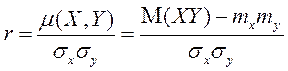 , (2.2.1)
, (2.2.1)
где 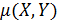 - ковариация случайных величин X и Y;
- ковариация случайных величин X и Y;
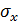 - среднее квадратичное отклонение случайной величины X;
- среднее квадратичное отклонение случайной величины X;
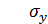 - среднее квадратичное отклонение случайной величины Y;
- среднее квадратичное отклонение случайной величины Y;
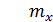 – математическое ожидание случайной величины X;
– математическое ожидание случайной величины X;
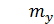 – математическое ожидание случайной величины Y;
– математическое ожидание случайной величины Y;
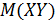 - математическое ожидание XY.
- математическое ожидание XY.
При этом 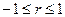 . При
. При 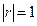 связь становится функциональной.
связь становится функциональной.
Выборочный коэффициент корреляции 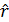 рассчитывается по формуле
рассчитывается по формуле
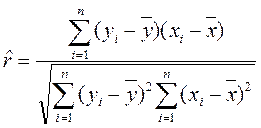 , (2.2.2)
, (2.2.2)
где 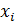 - значение случайной величины X для i -го наблюдения (объекта);
- значение случайной величины X для i -го наблюдения (объекта);
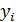 - значение случайной величины Y для i -го наблюдения (объекта);
- значение случайной величины Y для i -го наблюдения (объекта);
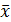 ,
, 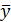 - выборочные средние значения случайных величин X и Y;
- выборочные средние значения случайных величин X и Y;
n – число наблюдений (объем выборки).
На практике используются следующие формулы для «ручных» вычислений
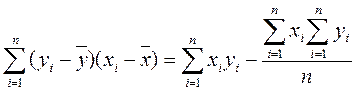 ;
;
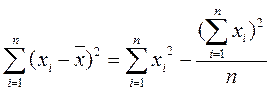 ; (2.2.3)
; (2.2.3)
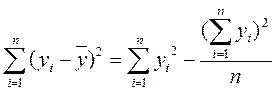 .
.
Если в системе имеется несколько переменных, которые коррелируют друг с другом, то на значение коэффициента корреляции между двумя переменными сказывается влияние других переменных. В связи с этим возникает необходимость исследовать частную корреляцию между переменными при исключении влияния остальных переменных системы.
Частный коэффициент корреляции – это мера линейной зависимости между двумя случайными величинами из некоторой совокупности случайных величин X1, X2, …,Xk, когда исключено влияние всех остальных величин.
По сути частный коэффициент корреляции между переменными Xi и Xj – 𝛒ij представляет собой обычный парный коэффициент корреляции между остатками Zi и Zj от линейных приближений этих переменных всеми остальными k-2 переменными - 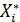 и
и 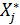 .
.
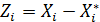 ;
; 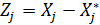 ;
; 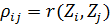 .
.
Можно показать, что частный коэффициент корреляции выражается через элементы корреляционной матрицы 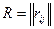 , составленной из коэффициентов парной корреляции.
, составленной из коэффициентов парной корреляции.
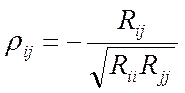 , (
, (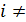 j) (2.2.4)
j) (2.2.4)
где Rij – алгебраическое дополнение элемента rij в корреляционной матрице.
Если случайные величины попарно не коррелированны, т. е. 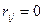 при
при 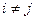 , то и все частные коэффициенты корреляции равны нулю.
, то и все частные коэффициенты корреляции равны нулю.
В этом легко убедиться, рассмотрев матрицу R, представляющую из себя в этом случае единичную матрицу
R = 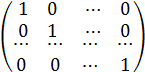
Выборочную оценку коэффициента частной корреляции можно получить следующим образом
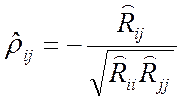 , (2.2.5)
, (2.2.5)
где 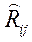 - алгебраическое дополнение элемента
- алгебраическое дополнение элемента 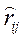 в выборочной корреляционной матрице
в выборочной корреляционной матрице 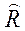 .
.
При системе из трех случайных величин из общей формулы (2.2.5) следует, что
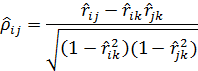
(2.2.6)
Сравнивая выборочные обычный и частный коэффициенты корреляции, можно делать вывод о том, насколько взаимосвязь между Xi и Xj обусловлена их зависимостью от других случайных величин.
Пример. В Англии исследовали влияние погоды на урожай. При этом рассматривали три переменные:
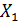 – урожай сена;
– урожай сена;
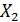 – количество осадков;
– количество осадков;
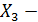 количество дней с высокой температурой.
количество дней с высокой температурой.
Корреляционная матрица, полученная по данным за 20 лет, имела вид
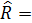
Отрицательная зависимость между урожаем сена () и числом дней с высокой температурой (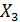 ) (
) (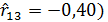 представляется весьма странной.
представляется весьма странной.
Рассчитаем значение частного коэффициента корреляции между и , исключая влияние переменной (количество осадков).
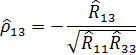
При этом
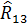 = (-1)4
= (-1)4 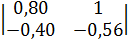 = - 0,048;
= - 0,048;
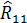 =(-1)2
=(-1)2 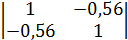 = 0,6864;
= 0,6864;
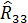 = (-1)6
= (-1)6  =0,36.
=0,36.
Таким образом,
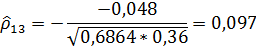
и связь не является отрицательной.
2.3. ПРОВЕРКА ЗНАЧИМОСТИ КОЭФФИЦИЕНТА КОРРЕЛЯЦИИ
После того, как вычислен выборочный коэффициент корреляции 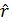 следует проверить гипотезу об отсутствии корреляционной связи для генеральной совокупности Н0:
следует проверить гипотезу об отсутствии корреляционной связи для генеральной совокупности Н0: 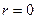 .
.
Для этого вычисляется критерий
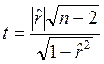 (2.3.1)
(2.3.1)
и сравнивается с табличным значением 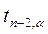 критерия Стьюдента с
критерия Стьюдента с 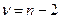 степенями свободы уровня значимости
степенями свободы уровня значимости 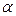 .
.
Если 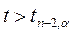 , то с надежностью
, то с надежностью 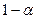 можно отвергнуть гипотезу Н0 и считать, что корреляция имеется.
можно отвергнуть гипотезу Н0 и считать, что корреляция имеется.
Частный коэффициент корреляции 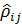 , вычисленный на основе выборки объема n, имеет такое же распределение, как и
, вычисленный на основе выборки объема n, имеет такое же распределение, как и 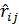 , вычисленный по
, вычисленный по 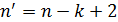 наблюдениям. Поэтому значимость частного коэффициента корреляции проверяют так же, как и обычного коэффициента корреляции, но при этом полагают, что .
наблюдениям. Поэтому значимость частного коэффициента корреляции проверяют так же, как и обычного коэффициента корреляции, но при этом полагают, что .
Для измерения тесноты связи между двумя случайными величинами используется не только коэффициент корреляции, но и корреляционное отношение.
Рассмотрим аналитическую группировку. Имеет место следующее соотношение
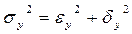 , (2.4.1)
, (2.4.1)
где 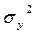 − полная дисперсия признака-результата;
− полная дисперсия признака-результата;
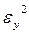 − внутригрупповая дисперсия;
− внутригрупповая дисперсия;
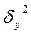 −
− Внутригрупповая дисперсия характеризует ту часть дисперсии признака-результата, которая не зависит от признака-фактора. Ее оценка определяется по формуле
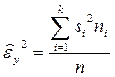 , (2.4.2)
, (2.4.2)
где 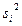 - оценка дисперсии признака – результата в пределах отдельной
- оценка дисперсии признака – результата в пределах отдельной
(i- ой) группы по признаку-фактору;
ni – численность i- й группы;
k- количество групп;
n - общий объем выборки.
Межгрупповая дисперсия отражает ту часть общей дисперсии признака-результата, которая объясняется влиянием признака-фактора. Ее оценка определяется по формуле
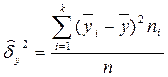 , (2.4.3)
, (2.4.3)
где 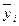 − групповое среднее i-й группы;
− групповое среднее i-й группы;
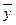 - общее среднее значение признака – результата.
- общее среднее значение признака – результата.
Коэффициент детерминации определяет долю объясненной дисперсии в общей дисперсии признака-результата
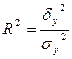 . (2.4.4)
. (2.4.4)
Корреляционное отношение определяется как
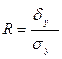 . (2.4.5)
. (2.4.5)
В литературе по эконометрике корреляционное отношение принято называть индексом корреляции.
Оно является мерой тесноты связи при любой форме зависимости, а не только линейной, как коэффициент корреляции.
2.5. ПАРНАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
Следующий этап исследования корреляционной связи заключается в том, чтобы описать зависимость признака-результата от признака-фактора некоторым аналитическим выражением.
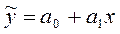 ;
; 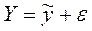 ,
,
где 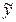 − средний уровень показателя Y при данном значении x;
− средний уровень показателя Y при данном значении x;
ε – случайная компонента.
Модель парной линейной регрессии может быть записана и в следующем виде
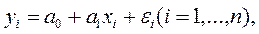
где xi – значение переменной X в i -ом наблюдении;
yi – значение переменной Y в i -ом наблюдении;
εi – значение случайной компоненты ε в i -ом наблюдении;
n – число наблюдений (объем выборки).
Основные предположения регрессионного анализа относятся к случайной компоненте 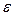 и имеют решающее значение для правильного и обоснованного применения регрессионного анализа на практике.
и имеют решающее значение для правильного и обоснованного применения регрессионного анализа на практике.
В классической модели регрессионного анализа имеют место следующие предположения:
1) Величины 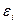 (а также зависимые переменные
(а также зависимые переменные 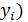 являются случайными, а объясняющая переменная – величина неслучайная.
являются случайными, а объясняющая переменная – величина неслучайная.
2) Математическое ожидание случайной компоненты 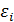 равно нулю
равно нулю
(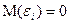 ).
).
3) Случайные величины имеют одинаковую дисперсию (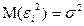 ). Данное условие называется условием гомоскедастичности.
). Данное условие называется условием гомоскедастичности.
4) Случайные компоненты и 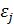 являются некоррелированными между собой (
являются некоррелированными между собой (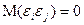 при ).
при ).
Эти четыре предположения являются необходимыми для проведения регрессионного анализа в рамках классической модели.
Пятое предположение дает достаточные условия для обоснованного проведения проверки статистической значимости полученных регрессий и заключается в нормальности закона распределения .
В общем случае задача оценки параметров регрессии может решаться с помощью метода наименьших квадратов (МНК).
Рассмотрим использование метода наименьших квадратов для оценки параметров регрессии
. (2.5.1)
На практике имеется серия наблюдений (xi;yi) (i=1,..,n).
При этом
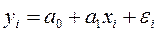 .
.
Тогда
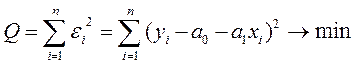 . (2.5.2)
. (2.5.2)
Возьмем частные производные Q по параметрам 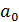 и
и 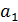 и приравняем их нулю
и приравняем их нулю
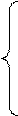
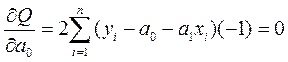 , (2.5.3)
, (2.5.3)
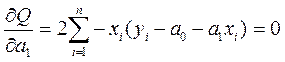 .
.

