 2018-02-14
2018-02-14 2570
2570Во многих задачах требуется установить и оценить зависимость некоторого экономического показателя от одного или нескольких других показателей. Любые экономические показатели, как правило, находятся под влиянием случайных факторов, а потому с математической точки зрения интерпретируются как случайные величины.
Из теории вероятностей известно, что случайные величины могут быть связаны функциональной или статистической зависимостью или вообще быть независимыми. Соотношение между независимыми переменными здесь не рассматриваются, так как строгая функциональная зависимость реализуется в экономике редко. Чаще наблюдается так называемая статистическая зависимость.
Напомним, что статистическая зависимость - это когда с изменением одной случайной величины меняется закон распределения вероятностей другой. Статистическая зависимость проявляется в том, что с изменением одной величины меняется среднее значение другой. Такая зависимость называется корреляционной.
Например, у авиакомпаний с одинаковым количеством и видов самолетов существует разный доход. Конечно, нет строгой функциональной зависимости между количеством и видами самолетов. Это объясняется влиянием других факторов (качество обслуживания, безопасность полетов, квалификация работников, расположение авиакомпании и касс приобретения билетов и т.д.). В то же время, среднее количества самолетов и их видов, наверное, связаны корреляционной зависимостью.
В земледелии из одинаковых по площади участков земли при равных количествах внесенных удобрений собирают разный урожай. Конечно, нет строгой функциональной зависимости между урожайностью земли и количеством внесенных удобрений. Это объясняется влиянием случайных факторов (осадки, t воздуха, расположение участка и т.п.). Хотя, как показывает опыт, средний урожай зависит от количества внесенных удобрений, то есть эти показатели, наверное, связаны корреляционной зависимостью.
Два типа взаимосвязи переменных. В одном случае неизвестно, какая из переменных независимая, а какая - зависимая, то есть они равноправны и связь можно рассматривать как в одну, так и в другую сторону. Во втором случае переменные неравноправные, т.е. изменения только одной из них влияет на изменения другой, а не наоборот. При рассмотрении связи между двумя переменными величинами важно установить на основе логического рассуждения, что из признаков является причиной, а что - следствием. Например, урожайность зависит от плодородия земли, а не наоборот, т.е. экономическая оценка земли является независимой переменной, а урожайность - зависимой.
Необходимо помнить, что статистический анализ зависимостей сам по себе не раскрывает сущности причинных связей между явлениями, то есть он не решает вопрос, по каким причинам одна переменная влияет на другую. Решение такой задачи является результатом качественного (содержательного) изучения связей, что обязательно должно или предшествовать статистическому анализу, или сопровождать его.
Пусть по определенным экономическим соображениям установлено, что некоторый экономический показатель х является причиной изменения иного показателя у. Статистические данные по каждому из показателей интерпретируются как некоторые реализации случайных величин X и У. Из теории вероятностей: математическим ожиданием случайной величины называется ее среднее (арифметическое или взвешенное) значение. А зависимость среднего значения от другой случайной величины изображается с помощью условного математического ожидания.
Корреляционная зависимость между ними или зависимость в среднем в общем случае можно представить в виде соотношения
М( У | х) = f(х), (1.1)
где М(У | х) - условное математическое ожидание.
Функция f (x) называется функцией регрессии У на X. При этом X называется независимой (объясняющей) переменной (регрессором), У - зависимой (объясняемое) переменной (регресандом). Рассматривая зависимость двух случайных величин, говорят о парной регрессии.
Зависимость У от нескольких переменных, описывается функцией
М(У\хі,х2,...,хт) = F(хі,х2,..., хт), (1.2)
называют множественной регрессией.
Термин "регрессия" (движение назад, возвращение к прежнему состоянию) ввел Фрэнсис Галтон конце XIX в., Проанализировав зависимость между ростом родителей и ростом детей. Он заметил, что рост детей у очень высоких родителей в среднем меньше, чем средний рост родителей. У очень низких родителей, наоборот, средний рост детей выше. В обоих случаях средний рост детей стремится (возвращается) к среднему росту людей в данном регионе. Отсюда и выбор термина, отражает такую зависимость,
Однако реальные значения зависимой переменной не всегда совпадает с ее условным математическим ожиданием, поэтому аналитическая зависимость (в виде функции у = f(х)) должна быть дополнена случайной составляющей и, что, собственно, и указывает на стохастическую сущность зависимости.
Определение 1.1. Связи между зависимой и независимой (независимыми) переменными, описываются соотношениями
у = f(х) + и, (1.3) у = F(хі,х2,...,хт) + и, (1.4)
называют регрессионными уравнениями (моделями).
Причины обязательного присутствия в регрессионных моделях случайного фактора (отклонение). Среди таких причин выделим существенные.
1. Введение в модель не всех объясняющих переменных. Любая регрессионная (в частности, эконометрическая) модель - это упрощение реальной ситуации, которая приводит к отклонению реальных значений зависимой переменной от ее модельных значений. Например, спрос на товар определяется его ценой, ценами на товары - заменители, на товары, которые его дополняют, прибылью потребителей, их вкусами, предпочтениями и т.п. Безусловно, перечислить все объясняющие переменные практически невозможно. В частности, невозможно учесть такие факторы, как традиции, национальные или религиозные особенности, географическое положение района, погоду и многие другие, влияние которых приводит к некоторым отклонениям реальных наблюдений от модельных. Эти отклонения могут быть описаны как случайная составляющая модели.
В некоторых случаях заранее неизвестно, какие факторы, в сложившихся условиях, в действительности являются определяющими, а какими можно пренебречь. Кроме того, иногда непосредственно учесть какой-то фактор невозможно из-за отсутствия статистических данных. Например, объем сбережений домохозяйств может определяться не только доходами их членов, но и состоянием здоровья, информация о котором в цивилизованных странах составляет врачебную тайну. В некоторых ситуациях ряд факторов имеет принципиально случайный характер, что придает неоднозначности определенным моделям, например погода в моделях, прогнозирующих объем урожая.
2. Неправильный выбор функциональной формы модели. Из-за слабой изученности исследуемого процесса, или через его изменчивость, может быть неправильно подобрана моделирующая его функция. Это, безусловно, повлечет отклонение модели от реальности, что скажется на величине случайной составляющей. Например, производственная функция (У) одного фактора (X) может моделироваться функцией У = а + ЬХ, хотя должна использоваться другая модель, У = аХь(0<Ь< 1), учитывающая закон убывающей эффективности. Кроме того, неправильным может быть отбор объясняющих переменных.
3. Агрегирования переменных. Во многих моделях рассматриваются зависимости между факторами, которые сами являются сложной комбинацией других, простых переменных. Например, при изучении совокупного спроса анализируется зависимость, в которой объяснимая переменная (совокупный спрос) является сложной композицией индивидуальных спросов, что также может оказаться причиной отклонения реальных значений от модельных.
4. Ошибки измерений. Какой бы качественной ни была модель, ошибки измерения переменных влиять на расхождения между модельными и эмпирическими данными, также скажется на величине случайного члена.
5. Ограниченность статистических данных. Чаще строятся модели, описываемые непрерывными функциями. Для оценки параметров модели используется набор данных, который имеет дискретную структуру. Это несоответствие находит отражение в случайном отклонении,
6. Непредсказуемость человеческого фактора. Эта причина может "испортить" качественную модель. Действительно, при правильном выборе формы модели. Скрупулезном отборе объясняющих переменных невозможно спрогнозировать поведение каждого индивидуума.
Совокупность методов, с помощью которых исследуются и обобщаются взаимосвязи корреляционно связанных переменных, называется корреляционно-регрессионным анализом.
Указанными методами решают две основные задачи:
1) нахождение общей закономерности, которая характеризует зависимость двух (или более) корреляционно связанных переменных - разработка математической модели связи (задача регрессионного анализа);
2) определение тесноты связи (корреляционного анализа).
В основном процедура анализа связи между переменными позволяет установить его природу, то есть определить форму зависимости между переменными.
Построение качественного уравнения регрессии, соответствует эмпирическим данным и целям исследований, является достаточно сложным процессом. Его можно разделить на три этапа:
1) выбор формы уравнения регрессии;
2) определение параметров выбранного уравнения;
3) анализ качества уравнения и проверка адекватности уравнения эмпирическим данным, совершенствование уравнения.
Выбор формы связи переменных называется спецификацией модели регрессии.
В случае парной регрессии выбор формулы обычно осуществляется графическим изображением реальных статистических данных в виде точек в декартовой системе координат, называется корреляционным полем (диаграммой рассеяния) (рис. 1.1).
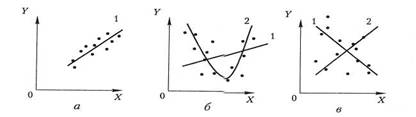
Рис. 1.1
На рис. 1.1 проиллюстрировано три ситуации.
На графике 1.1, а взаимосвязь между X и Y близка к линейной, и прямая 1 достаточно хорошо согласуется с эмпирическими точками. Поэтому чтобы описать зависимость между X и Y, целесообразно выбрать линейную функцию У= Ьо + Ь1Х.
На графике 1,1, б реальная взаимосвязь между X и Y, вероятнее всего, описывается квадратичной функцией У = аХ2 + ЬХ + с (линия 2).
На графике 1.1, в явная взаимосвязь между X и Y отсутствует. Поэтому чтобы лучше выбрать форму связи, необходимо, возможно, увеличить количество наблюдений - точек корреляционного поля или воспользоваться другими способами измерения показателей.
В случае множественной регрессии определить формы зависимости еще сложнее.
Если природа связи неизвестна, то соотношение между показателями описывают с помощью приближенных упрощенных форм зависимостей, прежде всего, линейных.
Например, Кейнс предложил линейную формулу зависимости индивидуального потребления С от дохода У: С = с0 + ЬУ, де с0 > 0 - величина автономного потребления; Ь - предельная склонность к потреблению, 0 < Ь < 1.
Однако пока не вычислены количественные значения коэффициентов с0 і Ь и не проверена надежность полученных результатов, указанная формула остается лишь гипотезой.

