 2014-02-24
2014-02-24 12528
12528Общее понятие о данных
Процесс непосредственного исследования предполагает контакт исследователя с объектом, в результате чего получают совокупность характеристик этого объекта. Полученные характеристики являются главным материалом для проверки рабочей гипотезы и решения проблемы. В зависимости от предмета и цели исследования эти характеристики могут представать в виде различных параметров объекта (пространственных, временных, энергетических, информационных, интеграционных), в виде соотношений между частями объекта или его самого с другими объектами, в виде различных зависимостей его состояний от всевозможных факторов и т. д. Всю совокупность подобных сведений называют данными об объекте, а точнее, первичными данными, чтобы подчеркнуть непосредственный характер этих сведений и необходимость их дальнейшего анализа, обработки, осмысления. На первый взгляд забавное, но по существу верное мнение высказывает Ж. Годфруа, считающий, что данные – это элементы подлежащие анализу, это любая информация, которая может быть классифицирована с целью обработки. В теоретическом исследовании под сбором данных подразумевается поиск и отбор уже известных фактов, их систематизация, описание под новым углом зрения. В эмпирическом исследовании подданными понимается отражение предметов, явлений, признаков или связей объективной действительности. Таким образом, это не сами объекты, а их чувственно-языковые отображения. Реальные объекты – это фрагменты мира, а данные о них – это фундамент науки. Эти данные есть «сырье» научного исследования при индуктивных гипотезах и цель при дедуктивных гипотезах.
Данные можно классифицировать по различным основаниям (критериям), среди которых в науке наиболее популярны следующие:
I. По научному обоснованию
1. Научные.
2. Ненаучные.
II. По вкладу в проверку гипотезы и решение проблемы
1. Решающие.
2. Значительные.
3. Незначительные.
III. По области и характеру источников информации
1. Социологические.
2. Психологические.
3. Педагогические.
4. Физиологические и т. д.
IV. По методам исследования
1. Данные наблюдения.
2. Данные опроса.
3. Экспериментальные данные и т. д.
V. По методам в сочетании с источниками (классификацияР. Б. Кеттелла)
1. L-данные.
2. Q-данные.
3. Т-данные.
VI. По информативности
1. Неметрические
а) качественные (классификаторные, номинативные).
б) порядковые (компаративные).
2. Метрические:
а) интервальные.
б) пропорциональные;
Научные данные – это сведения, полученные в результате научных изысканий и характеризующиеся высокой степенью достоверности (доказанности и надежности), возможностью проверки, теоретической обоснованностью, включенностью в широкую систему научных знаний. Характерной особенностью научных данных, как и вообще научных знаний, является их относительная истинность, т. е. потенциальная возможность их опровержения в результате научной критики.
Ненаучные данные – сведения, полученные ненаучными путями. Например, из житейского опыта, из религиозных источников, из традиций, от авторитетов и т. д. Эти данные не доказываются, зачастую считаются самоочевидными. Не имеют теоретических обоснований. Многие из них претендуют на абсолютную истинность, их принятие субъектом познания базируется на некритическом усвоении, доверии (своему опыту, догматам, авторитетам).
Решающие данные – это сведения, позволяющие однозначно принять или отвергнуть выдвинутую гипотезу.
Значительные данные – это данные, вносящие весомый вклад в решение проблемы, но недостаточные для ее решения без привлечения других сведений.
Незначительные – данные малой информативности по решаемому вопросу.
Социологические, психологические и т. д. – данные, полученные в соответствующих сферах бытия, в первую очередь – общественного бытия. В узком смысле – это данные соответствующих наук:
Данные наблюдения, опроса и т. д. – сведения, полученные с помощью того или иного эмпирического метода.
Пятая группировка предложена американским психологом Р. Б. Кеттеллом в середине XX столетия и обычно относится к данным по проблемам личности и социально-психологическим вопросам.
L-данные (life data) – сведения, получаемые путем регистрации фактов реальной жизни. Обычно это данные наблюдения за повседневной жизнью человека или группы. С них рекомендуется начинать предварительное исследование проблемы.
Q-данные (questionnaire data) – сведения, получаемые с помощью опросников, тестов интересов, самоотчетов и других методов самооценок, а также путем свободного обследования психиатров, учителей и т. п. Благодаря простоте инструментария и легкости получения информации Q-данные занимают ведущее место в исследованиях личности. Число методик огромно. Наиболее известные: опросники Айзенка (EPI, EPQ), Миннесотский многопрофильный личностный перечень (MMPI), Калифорнийский психологический тест (CPI), 16-факторный личностный опросник Кеттелла (16PF), тест Гилфорда – Циммермана для исследования темперамента (GZIS).
Т-данные (test data) – сведения, получаемые с помощью объективных тестов, а также физиологических измерений. Эти данные «объективны», поскольку их получают в результате объективного измерения реакций и поведения человека без обращения к самооценке или оценке экспертов. Количество методик для получения Т-данных также очень велико. Это тесты способностей, тесты интеллекта, тесты достижений. Кеттелл сюда же относит антропометрические и физиологические измерения, ситуативные и проективные тесты (всего более 400 методик, разбитых на 12 групп). Наиболее, известны: тест «пятна Роршаха», тест Ро-зенцвейга, тест тематической апперцепции (ТАТ), тесты интеллекта Стенфорд-Бине, Векслера, Амтхауэра.
Деление данных по информативности базируется на качественно-количественной нагрузке их содержания, позволяющей эти сведения соотносить друг с другом или с уже имеющимися сведениями в данной области на том или ином уровне точности. Эта группировка данных согласуется с классификацией измерительных шкал по С. Стивенсу.
Неметрические данные – это те, которые не имеют метрики, т. е. единиц измерения.
Метрические – количественные данные, имеющие единицы измерения.
Качественные данные (классификаторные, номинативные) – сведения, на основании которых изучаемый объект (или его состояние) можно отнести к какому-либо множеству (классу) сходных объектов. В этих данных отражаются сугубо качественные характеристики объекта, не позволяющие выяснить степень выраженности признака объекта, а следовательно, и его соотношение с подобными объектами, входящими в тот же класс. Эти данные указывают только на наличие или отсутствие какого-либо признака, по которому объект можно отнести к тому или иному классу. Каждый класс сходных объектов имеет определенное наименование, поэтому система классов носит название шкалы наименований (номинальной шкалы), а сами данные называются номинативными. Психологическая основа получения таких данных и построения таких шкал – процессы опознания (идентификации), т. е. установление отношений равенства или неравенства. Примеры: 1) синий – красный – желтый и т. д.; 2) мужчина – женщина; 3) холерик – сангвиник – флегматик – меланхолик.
Порядковые, или компаративные (лат. comparativus – сравнительный) – это данные, на основании которых объекты можно сравнивать по степени выраженности их признаков в системе оценок «больше – меньше». Это дает возможность упорядочивать объекты по определенному изучаемому признаку в возрастающем (убывающем) порядке, т. е. ранжировать. Соответствующие шкалы называются порядковыми или ранговыми. Но далее субординации здесь не продвинуться. Указать, насколько различаются между собой объекты, невозможно. Психологическая основа выявления этих данных и построения порядковых шкал – процессы различения и предпочтения, т. е. установление отношений «равно – неравно» и «больше – меньше». Примеры: любые шкалы оценок, шкала твердости минералов Мооса, итоговая турнирная таблица без указания результатов, ранжирование популярных артистов, приятность звуков, запахов, цветов и т. п.
Интервальные данные – это те, которые позволяют метрически оценить выраженность признака и ответить на вопрос, «на сколько» у одного объекта этот признак выражен больше или меньше, чем у другого. Эта разница на континууме значений измеряемого признака (на шкале) представляется как некоторая сумма субъективно равных интервалов, поэтому и данные называются интервальными. А шкалы – шкалами интервалов, расстояний или разностей, где интервалы являются единицами измерения. Психологическая основа – способность к уравниванию субъективных (в первую очередь, сенсорных и эмоциональных) расстояний. Примеры: шкалы температур по Цельсию, Реомюру и Фаренгейту; календарные даты; шкалы, основанные на прямом измерении сенсорных расстояний.
Пропорциональные данные – это те, которые дополнительно к интервальной информации дают ответ на вопрос, «во сколько раз» признаку одного объекта выражен сильнее или слабее, чем у другого. Для этого на шкале данных должна иметься опорная точка, соответствующая естественному нулевому значению измеряемого признака. Такие шкалы называются пропорциональными, или шкалами отношений. Точка отсчета, называемая абсолютным нулем, указывает на отсутствие данного качества. Абсолютный нуль нельзя путать с относительным, или условным. Последний вводится искусственно, по договоренности. Например, на шкале температур по Цельсию, Фаренгейту и Реомюру за нулевую точку условно принята температура плавления льда. И в этих координатах бессмысленно говорить, во сколько раз что-то теплее или холоднее чего-то другого. Только шкала Кельвина имеет абсолютный нуль (-273,16° по Цельсию). К сожалению, для психологических характеристик обычно очень трудно указать нулевое значение, а значит, и получить пропорциональные данные. Тем не менее ряд специальных приемов, объединенных под наименованием процедур прямого (субъективного) шкалирования, открывает возможность получения пропорциональных данных и построения шкал отношений. Психологическая основа этих процедур – способность человека к определению субъективных отношений. Обычно это отношения, фиксирующие двойное или тройное превосходство (2:1, 3:1). Примеры: физические данные и соответствующие шкалы длин, весов, плотностей и т, д.; прямые психофизические шкалы громкости (сонов), яркости (брилов), тяжести (вегов) и т. п.
Процедура сбора данных
Сбор данных в целом должен соответствовать намеченному на предыдущем этапе алгоритму действий, чтобы избежать как пробелов в искомых знаниях, так и лишних трудозатрат. Очень важно при этом точно и четко фиксировать все действия и получаемые сведения. Для этого обычно ведется протокол исследования, используются специальные средства фиксации (видео, аудио и т. п.). Осуществляемый на этом этапе контакт исследователя с изучаемым объектом не должен наносить последнему вреда, процедура сбора данных должна быть предельно гуманизирована. Процесс сбора данных конкретизируется в зависимости от выбранного метода и задач исследования.
ОБРАБОТКА ДАННЫХ
Общее представление об обработке
Собрав совокупность данных, исследователь приступает к их обработке, получая сведения более высокого уровня, называемые результатами. Он уподобляется портному, который снял мерку (данные) и теперь все зафиксированные размеры соотносит между собой, приводит в целостную систему в виде выкройки и в конечном итоге – в виде той или иной одежды. Параметры фигуры заказчика – это данные, а готовое платье – это результат. На этом этапе могут обнаружиться ошибки в замерах, неясности в согласовании отдельных деталей одежды, что требует новых сведений, и клиент приглашается на примерку, где вносятся необходимые коррективы. Так и в научном исследовании: полученные на предыдущем этапе «сырые» данные путем их обработки приводят в определенную сбалансированную систему, которая становится базой для дальнейшего содержательного анализа, интерпретации и научных выводов и практических рекомендаций. Если по обработке данных выявляются какие-либо ошибки, пробелы, несоответствия, препятствующие построению такой системы, то их можно ликвидировать и восполнить, проведя повторные замеры.
Обработка данных направлена на решение следующих задач: 1) упорядочивание исходного материала, преобразование множества данных в целостную систему сведений, на основе которой возможно дальнейшее описание и объяснение изучаемых объекта и предмета; 2) обнаружение и ликвидация ошибок, недочетов, пробелов в сведениях; 3) выявление скрытых от непосредственного восприятия тенденций, закономерностей и связей; 4) обнаружение новых фактов, которые не ожидались и не были замечены в ходе эмпирического процесса; 5) выяснение уровня достоверности, надежности и точности собранных данных и получение на их базе научно обоснованных результатов.
Если на предыдущих этапах происходит процесс увеличения разнообразия сведений (числа параметров, единичных измерений, источников и т. п.), то теперь наблюдается обратный процесс – ограничение разнообразия, приведение данных к общим знаменателям, позволяющим делать обобщения и прогнозировать развитие тех или иных психических явлений.
Рассматриваемый этап обычно связывается с обработкой количественного характера. Качественная сторона обработки эмпирического материала, как правило, только подразумевается либо вовсе опускается. Обусловлено это, видимо, тем, что качественный анализ часто ассоциируется с теоретическим уровнем исследования, который присущ последующим стадиям изучения объекта – обсуждению и интерпретации результатов. Представляется, однако, что исследование качественного характера имеет два уровня: уровень обработки данных, где проводится организационно-подготовительная работа по первичному выявлению и упорядочиванию качественных характеристик изучаемого объекта, и уровень теоретического проникновения в сущность этого объекта. Работа первого типа характерна для стадии обработки данных, а второго – для этапа интерпретации результатов. Результат в данном случае понимается как итог и количественного, и качественного преобразования первичных данных. Тогда количественная обработка есть манипуляция с измеренными характеристиками изучаемого объекта (объектов), с его «объективизированными» во внешнем проявлении свойствами. Качественная обработка – это способ предварительного проникновения в сущность объекта путем выявления его неизмеряемых свойств на базе количественных данных.
Количественная обработка направлена в основном на формальное, внешнее изучение объекта, качественная – преимущественно, на содержательное, внутреннее его изучение. В количественном исследовании доминирует аналитическая составляющая познания, что отражено и в названиях количественных методов обработки эмпирического материала, включающих в себя категорию «анализ» корреляционный анализ, факторный анализ и т. д. Основным этапом количественной обработки является упорядоченная совокупность «внешних» показателей объекта (объектов). Реализуется количественная обработка с помощью математико-статистических методов.
В качественной обработке доминирует синтетическая составляющая познания, причем в этом синтезе превалирует компонент, объединения и в меньшей степени присутствует компонент обобщения. Обобщение – прерогатива последующего этапа исследовательского процесса – интерпретационного. В фазе качественной обработки данных главное заключается не в раскрытии сущности изучаемого явления, а пока лишь в соответствующем представлении сведений о нем, обеспечивающем дальнейшее его теоретическое изучение. Обычно результатом качественной обработки является интегрированное представление о множестве свойств объекта или множестве объектов в форме классификаций и типологий. Качественная обработка в значительной мере апеллирует к методам логики.
Противопоставление друг другу качественной и количествен ной обработок (а следовательно, и соответствующих методов) довольно условно. Они составляют органичное целое. Количественный анализ без последующей качественной обработки бессмыслен, так как сам по себе он не в состоянии превратить эмпирические данные в систему знаний. А качественное изучение: объекта без базовых количественных данных – немыслимо. В научном познании. Без количественных данных качественное познание – это чисто умозрительная процедура, не свойственная современной науке. В философии категории «качество» и «количество», как известно, объединяются в категории «мера».
Единство количественного и качественного осмысления эмпирического материала наглядно проступает во многих методах обработки данных: факторный и таксономический анализы, шкалирование, классификация и др. Но поскольку традиционно в науке принято деление на количественные и качественные характеристики, количественные и качественные методы, количественные и качественные описания, не будем «святее папы Римского» и примем количественные и качественные аспекты обработки данных за самостоятельные фазы одного исследовательского этапа, которым соответствуют определенные количественные и качественные методы.
Качественная обработка естественным образом выливается в описание и объяснение изучаемых явлений, что составляет уже следующий уровень их изучения, осуществляемый на стадии интерпретации результатов. Количественная же обработка полностью относится к рассматриваемому этапу исследовательского процесса, что в совокупности с ее особой спецификой побуждает к ее более подробному изложению. Процесс количественной обработки данных имеет две фазы: первичную и вторичную. Последовательно рассмотрим их.
На первой стадии «сырые» сведения группируются по тем или иным критериям, заносятся в сводные таблицы, а для наглядного представления данных строятся различные диаграммы и графики. Все эти манипуляции позволяют, во-первых, обнаружить и ликвидировать ошибки, совершенные при фиксации данных, и, во-вторых, выявить и изъять из общего массива нелепые данные, полученные в результате нарушения процедуры обследования, несоблюдения испытуемыми инструкции и т. п. Кроме того, первично обработанные данные, представая в удобной для обозрения форме, дают исследователю в первом приближении представление о характере всей совокупности данных в целом: об их однородности–неоднородности, компактности-разбросанности, четкости–размытости и т. д. Эта информация хорошо читается на наглядных формах представления данных и связана с понятием «распределение данных».
Под распределением данных понимается их разнесенность по категориям выраженности исследуемого качества (признака). Разнесенность по категориям показывает, как часто (или редко) в определенном массиве данных встречаются те или иные показатели изучаемого признака. Поэтому такой вид представления данных называют «распределением частот». Выраженность признака, как видели выше, может быть представлена в оценках: «есть – нет» или «равно – неравно» (номинативные данные), «больше – меньше» (порядковые данные), «настолько-то больше или меньше» (интервальные данные), «во столько-то раз больше или меньше» (пропорциональные данные). Первая категория оценок предполагает явную дискретность выраженности изучаемого признака, остальные – непрерывность (хотя бы теоретически). Проиллюстрируем это примерами.
Пример для дискретных данных
В трехтысячном трудовом коллективе были выбраны сто человек, которые давали ответ на вопрос: «какой цвет вы предпочитаете?». Предлагалось 6 вариантов: белый (Б), черный (Ч), красный (К), синий (С), зеленый (3), желтый (Ж). В данном случае каждый цвет – это самостоятельная категория выраженности признака «окраска». Допустим, цель – выбор дизайнером окраски рабочих помещений, где трудятся эти люди. Итоги опроса, зафиксированные в протоколе, подсчитали и занесли в таблицу 1 (табулировали).
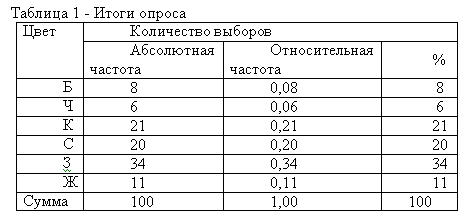
Частота (абсолютная частота) – это число ответов данной категории в выборке, частность (относительная частота) – это отношение частоты ко всей выборке. Под выборкой понимается все множество полученных в исследовании значений изучаемого признака (свойства, качества, состояния) объекта. В нашем примере выборка равна 100. Понятие выборки связано с понятием генеральной совокупности (или популяции), которая представляет собой все возможное множество значений изучаемого признака. В нашем примере она равна 3000. Поскольку даже ограниченные популяции обычно весьма велики, то опыты проводятся только на выборках. Поэтому встает вопрос о репрезентативности выборки, т. е. о том, можно ли результаты, полученные на выборке, переносить на всю совокупность. Для этого привлекают статистические методы доказательства репрезентативности. Таким образом, выборка есть часть генеральной совокупности. Краткое описание этих множеств производится с помощью так называемых описательных мер (мер центральной тенденции, разброса и связи), вычисление которых производится при вторичной обработке данных. Значения мер, вычисленные для генеральных совокупностей, называются параметрами, для выборок – статистиками. Параметр описывает генеральную совокупность также, как статистика – выборку. Принято обозначать статистики латинскими буквами, а параметры – греческими. Правда, в психологических исследованиях этих правил не всегда строго придерживаются.
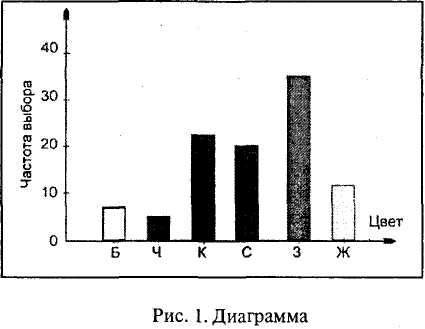
На основании табличных данных можно построить диаграмму, где распределение представлено нагляднее:
Пример для непрерывных данных
Данные непрерывного характера можно представить в еще более наглядной форме: в виде гистограмм, полигонов и кривых.
В опытах В. К. Гайды, описанных в учебном пособии для студентов-психологов, участвовало 96 испытуемых. Определялся цвет последовательного образа восприятия насыщенного красного цвета. С этой целью каждый испытуемый в течение одной минуты рассматривал окрашенный в красный цвет образец, а затем переносил взгляд на белый экран, где видел круг в дополнительных цветах. Рядом с ним находился цветовой круг с разноокрашенными секторами, на котором испытуемый должен был выбрать тот цвет, который соответствовал цвету возникшего у него последовательного образа. При этом испытуемый не называл цвет, а лишь его номер в цветовом круге. Цветовой круг нормирован таким образом, что соседние цвета отличаются в нем друг от друга на одинаково замечаемую величину. Следовательно, цветовой круг можно рассматривать как интервальную шкалу. Наряду с этим цветовой круг характеризуется и еще одним свойством. В частности, можно себе представить, что между двумя соседними цветами, например между зеленовато-голубым и голубовато-зеленым, имеется еще множество не замечаемых человеческим глазом цветовых переходов. В этом смысле цветовой круг представляет собой пример непрерывной переменной. Фактически же испытуемые всегда выделяют конечное число цветовых оттенков и поэтому свой выбор останавливают на конкретном номере (или названии) цвета. В рассматриваемом эксперименте испытуемые определяли свой последовательный образ в диапазоне от № 16 – зеленовато-голубой цвет до № 23 – желтовато-зеленый. Полученные данные можно табулировать, что и сделано в таблице 2.
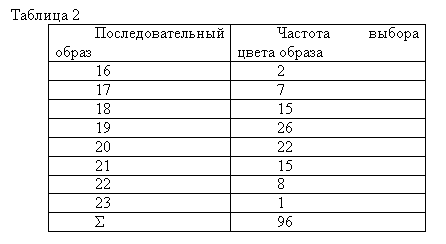
Как видно, в построении таблиц 1 и 2 нет принципиального различия. Но разница в характере первичных данных, отображенных в обеих таблицах, все же есть, и она обнаруживается при их графическом изображении. В самом деле, рис. 2 представляет собой уже не столбиковую, а ступенчатую диаграмму, называемую гистограммой. Следует обратить внимание на то, что все участки (столбики) ступенчатой диаграммы расположены вплотную друг к другу (числовые переменные на оси абсцисс гистограммы пишут против центральной оси каждого участка).
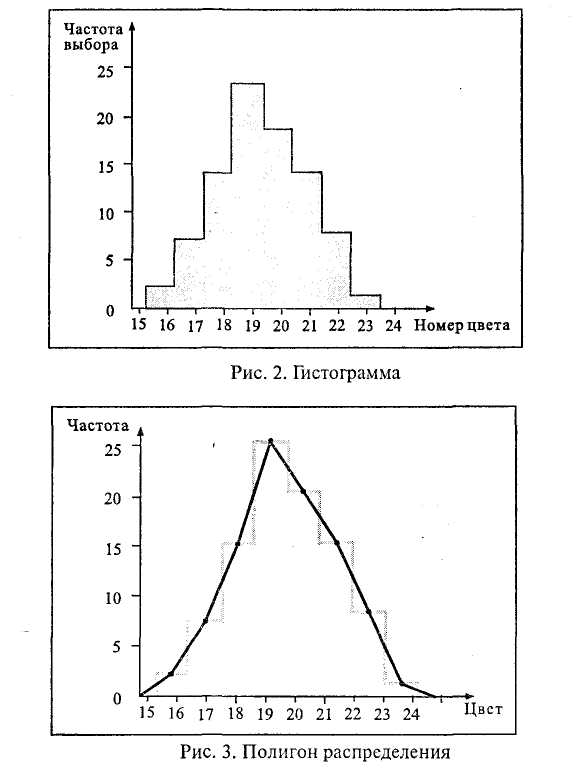
От гистограммы легко перейти к построению частотного полигона распределения, а от последнего – к кривой распределения. Частотный полигон строят, соединяя прямыми отрезками верхние точки центральных осей всех участков ступенчатой диаграммы (рис. 3). Если же вершины участков соединить с помощью плавных кривых линий, то получится кривая распределения первичных результатов (рис. 4).
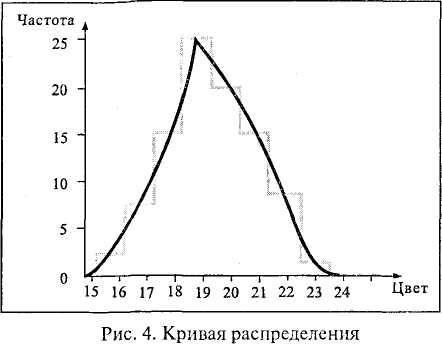
Переход от гистограммы к кривой распределения позволяет путем интерполяции находить те величины исследуемой переменной, которые в опыте не были получены.
Общее представление о вторичной обработке
Вторичная обработка завершает анализ данных и подготавливает их к синтезированию знаний на стадиях объяснения и выводов. Даже если эти последние этапы по каким-либо причинам не могут быть выполнены, исследование может считаться состоявшимся, поскольку завершилось получением результатов.
В основном вторичная обработка заключается в статистическом анализе итогов первичной обработки. Как специфический вид вторичной обработки, по нашему мнению, выступает шкалирование, совмещающее математический, логический и эмпирический анализы данных, но в этом параграфе остановимся лишь на статистической обработке данных. Уже табулирование и построение графиков, строго говоря, тоже есть статистическая обработка, которая в совокупности с вычислением мер центральной тенденции и разброса включается в один из разделов статистики, а именно в описательную статистику. Другой раздел статистики – индуктивная статистика – осуществляет проверку соответствия данных выборки всей популяции, т. е. решает проблему репрезентативности результатов и возможности перехода от частного знания к общему. Третий большой раздел – корреляционная статистика – выявляет связи между явлениями.
Статистика имеет мощный и подчас труднодоступный для неподготовленного исследователя аппарат. Поэтому надо сделать два замечания. Первое – статистическая обработка является неотъемлемой частью современного психологического исследования. Избежать ее практически невозможно (особенно в эмпирических исследованиях). Отсюда вытекает необходимость специалисту-психологу хорошо знать основы математики и статистики и важнейшие методы математико-статистического анализа психологической информации. Неизбежность статистики в психологии обусловлена массовостью психологического материала, поскольку все время приходится один и тот же эффект регистрировать по многу раз. Причина же необходимости многократных замеров кроется в самой природе психических явлений, устойчивость которых относительна, а изменчивость абсолютна. Классическим примером тому может служить непрерывная флуктуация сенсорных порогов, породившая знаменитую «пороговую проблему». Поэтому вероятностный подход – неизбежный путь к познанию психического. А статистические методы – способ реализации этого подхода.
Кстати, надо заметить, что формирующаяся с начала XX столетия новая картина мира, постепенно вытесняющая ньютонов-ско-картезианскую модель мироздания, одним из своих важнейших компонентов имеет как раз представление о преобладании статистико-вероятностных закономерностей над причинно-следственными. По крайней мере, это достаточно убедительно продемонстрировано для микроскопического (субатомного) и мегаскопического (космического) уровней организации мира. Логично предположить, что это в какой-то степени справедливо и для среднего (макроскопического) уровня, в границах которого и возможно, по-видимому, говорить о психике, личности и тому подобных категориях. Надо полагать, что именно в этом ключе следует понимать замечание Б. Г. Ананьева о вероятностном характере психической деятельности и о необходимости единства детерминистического и вероятностного подходов к исследованию психических явлений.
В связи с этим вызывает, по меньшей мере, недоумение бытующее в психологических кругах мнение, что соединение психологической проблематики с ее математическим анализом – это «брак по принуждению или недоразумению», где психология – «невеста без приданого». Вынуждена же психология вступить в этот «брак» якобы потому, что «не смогла пока еще доказать, что строится на принципиально иных основах», нежели точные науки. Эти же «принципиально иные основы» вроде бы обусловлены тем, что предмет исследования психологии несопоставим по своей сложности с предметами других наук. Нам кажется, что подобный снобизм не только не уместен с точки зрения научной этики, но и не имеет оснований. Мир – един в своем бесконечном многообразии. А наука лишь попытка человечества репрезентировать этот мир в моделях (в том числе в образах), доступных пониманию человека. Причем эти модели отражают лишь отдельные фрагменты мира. Но любой из этих фрагментов так же сложен, как и мир в целом. Так что математические формулы, статистические выкладки, описания натуралиста или психологические представления – все суть более или менее адекватные формы отражения одной и той же реальности. И математика в психологии – это не инородное вкрапление, которое психологи вынуждены терпеть за отсутствием собственных точных формальных (а по возможности и «объективных») способов описания и репрезентации психологической реальности. Это – естественный код организации мира и, соответственно, естественный язык описания этой организации.
Надежды некоторых психологов на временный характер зависимости психологии от математики – утопия. Психология использует математику не потому, что «за неимением гербовой пишет на простой», т. е. «пока» не имеет своих точных и объективных приемов анализа и объяснения психических феноменов, а потому, что математический язык – это общенаучный язык отражения реальности. И в этом смысле математику действительно можно признать «царицей наук». Психологии этот язык присущ так же, как любой другой отрасли научного знания. Вопрос лишь в том, насколько психология этот язык освоила. Таким образом, психологии вовсе не требуется доказывать, что она «может существовать независимо от математики» и эмансипироваться вплоть до «развода» с нею. Симптоматично в этом отношении формирование в последние годы новой психологической дисциплины – математической психологии.
Итак, утверждения о временном мезальянсе психологии с математикой, на наш взгляд, не состоятельны, сколь бы образны и метафоричны они ни были. Это – естественное единство.
Второе замечание касательно применения статистики в психологии заключается в предостережении: нельзя позволить втянуть себя в так называемую «статистическую мясорубку», когда полагают, что, пропустив через математическую обработку любой материал, можно получить какие-то зависимости, выявить какие-нибудь закономерности и факты. Без гипотезы и без продуманного подбора исходных данных научного результата ожидать только за счет применения статистики нельзя. Необходимо знать, что мы хотим получить от применения статистики и какие методы обработки подходят к условиям и задачам исследования.
К тому же надо заметить, что психологу не всегда по силам понять, что происходит с исходным психологическим материалом в процессе его статистического «прокручивания». Для уяснения некоторых операций внутри того или иного статистического метода (например, «варимакс-вращений» в факторном анализе) требуется специальная углубленная подготовка. Некоторые из этих операций базируются на тех или иных постулатах, не всегда подходящих к рабочей гипотезе пользователя. Поэтому для оценки адекватности, валидности намеченного метода иногда требуются весьма специфические знания. Апелляция к частоте и привычности использования в психологической практике таких матметодов не всегда спасает дело. И тогда эти приемы обработки данных становятся действительно «черным ящиком» и «статистической мясорубкой». Поэтому не следует стремиться к излишне сложным методам в погоне за модой или с сомнительной целью повысить уровень «научности» своей работы. Непродуманная стрельба «из пушки по воробьям» только ведет к неоправданным затратам и запутыванию психологической идеи исследования. Следует согласиться с выводом Е. В. Сидоренко, что «чем проще методы математической обработки, чем ближе они к реально полученным эмпирическим данным, тем более надежными и осмысленными получаются результаты».
Кроме того, нельзя забывать, что статистические методы – это вспомогательное оружие психолога, призванное лишь усилить исследовательскую мысль. Это лишь «деревья», за которыми должен быть виден «лес» – основная психологическая идея. Тем более что, как только что было сказано, всеобщность детерминации (по крайней мере, причинной) вызывает большие сомнения. Следовательно, поиск с помощью лишь математической обработки психологических зависимостей, тем более зависимостей функциональных, дело не очевидное и чреватое заблуждениями. Психологам хорошо известно, что в реальности невозможно найти ни «чистых», ни «среднестатистических» психологических типов. Это заставляет даже некоторых исследователей отказаться от рассмотрения каждого отдельного психического явления как эманации какой-то общей закономерности и тем паче «отказаться от того, чтобы считать отдельную личность случайной величиной, случайным проявлением более закономерного средне группового индивида».
После этих замечаний с удовольствием повторим вслед за Мак-Коннелом: «Статистика – это не математика, а прежде всего способ мышления, и для ее применения нужно лишь иметь немного здравого смысла и знать основы математики».
В дальнейшем изложении ограничимся освещением необходимого Minimum minimori в этой области, а именно важнейших элементов описательной и корреляционной статистики. Более подробные сведения по этим разделам статистической науки и о приемах индуктивной статистики применительно к психологической специфике можно почерпнуть из работ.
Всю совокупность полученных данных можно охарактеризовать в сжатом виде, если удается ответить на три главных вопроса: 1) какое значение наиболее характерно для выборки?; 2) велик ли разброс данных относительно этого характерного значения, т. е. какова «размытость» данных?; 3) существует ли взаимосвязь между отдельными данными в имеющейся совокупности и каковы характер и сила этих связей? Ответами на эти вопросы служат некоторые статистические показатели исследуемой выборки. Для решения первого вопроса вычисляются меры центральной тенденции (или локализации), второго – меры изменчивости (или рассеивания), третьего – меры связи (или корреляции). Эти статистические показатели приложимы к количественным данным (порядковым, интервальным, пропорциональным). Данные качественные (номинативные) поддаются математическому анализу с помощью дополнительных ухищрений, которые позволяют использовать элементы корреляционной статистики.
Тема 6. Лекция

