 2015-05-18
2015-05-18 2299
2299АВТОКОРРЕЛЯЦИОННАЯ ФУНКЦИЯ ВРЕМЕННОГО РЯДА – последовательность коэффициентов автокорреляции уровней временного ряда.
АВТОКОРРЕЛЯЦИЯ – отражает зависимость значения одного элемента динамического ряда от значений предшествующих элементов (или ошибки в очередном наблюдении от ее значений в других наблюдениях).
АДДИТИВНАЯ МОДЕЛЬ – модель вида: Y=T+S+E,
где Т - трендовая компонента;
S – циклическая компонента;
Е – случайная компонента.
АЛГОРИТМ ДВУХШАГОВОГО МЕТОДА НАИМЕНЬШИХ КВАДРАТОВ:
• Определяется приведенная форма модели, и находятся на ее основе оценки теоретических значений эндогенных переменных.
• Определяются структурные коэффициенты модели по данным теоретических (расчетных) значений эндогенных переменных.
АЛГОРИТМ КОСВЕННОГО МЕТОДА НАИМЕНЬШИХ КВАДРАТОВ:
• Структурная модель преобразовывается в приведенную форму модели.
• Для каждого уравнения приведенной формы модели обычным МНК оцениваются приведенные коэффициенты.
• Коэффициенты приведенной формы модели трансформируются в параметры структурной формы модели.
АНАЛИЗ СТРУКТУРЫ ВРЕМЕННОГО РЯДА:
• Если r1 наиболее высокий, то исследуемый ряд содержит только
тенденцию;
• Если rt наиболее высокий, то ряд содержит циклические колебания с периодичностью в t моментов времени;
• Если ни один из коэффициентов автокорреляции не является значимым,
то либо ряд не содержит тенденции и циклических колебаний, либо ряд содержит сильную нелинейную тенденцию.
АНАЛИТИЧЕСКОЕ ВЫРАВНИВАНИЕ ВРЕМЕННОГО РЯДА – способ моделирования тенденции временного ряда: построение аналитической функции, характеризующей зависимость уровней ряда от времени, или тренда.
ВРЕМЕННОЙ РЯД – это последовательность наблюдений, упорядоченных во времени (или пространстве). Если какое-нибудь явление наблюдают на протяжении некоторого времени, имеет смысл представить данные в том порядке, в котором они возникали, из-за того, в частности, что последовательные наблюдения могут быть зависимыми. В. р. хорошо представлять на диаграмме рассеяния. Значение ряда Х откладывают по вертикальной оси, а время t – по горизонтальной. Время называют независимой переменной. Существует два типа временных рядов:
1. Непрерывные, в которых мы имеем наблюдения в каждый момент времени, например, показатели детектора лжи, электрокардиограммы. Их обозначают как наблюдение Х в момент t, X(t).
2. Дискретные, в которых наблюдения делаются через некоторые (обычно одинаковые) интервалы времени. Их обозначают Xi.
Примеры
1. Экономические: недельные цены на акции; месячные прибыли.
2. Метеорологические: дневные осадки; скорость ветра; температура.
3. Социологические, показатели преступности (например, число арестов), показатели безработицы.
Функции, используемые при анализе временных рядов для построения трендов:
Линейный тренд: yt = at + b;
Нелинейные функции:
yt= a/t+b - гипербола;
yt=bta – степенная функция;
yt=bat - экспоненциальная функция;
yt=a 0 +a 1t +a 2t2 +,..., + amt m – параболы разных порядков.
ГЕНЕРАЛЬНАЯ СОВОКУПНОСТЬ – это (как правило, лишь воображаемое) полное собрание объектов (людей, животных, растений или вещей), являющееся источником данных. Она представляет все множество статистических единиц (группу интересующих нас предметов). Информацию о генеральной совокупности мы получаем, изучая выборки из нее; из каждой совокупности можно сделать много разных выборок. По выборке мы получаем информацию об интересующих нас параметрах совокупности. Например, выборочное среднее дает информацию о среднем всей совокупности. Важно, чтобы перед формированием выборки исследователь тщательно и полно определил генеральную совокупность, а также способ извлечения выборки. Выборка должна быть репрезентативной.
ГЕТЕРОСКЕДАСТИЧНОСТЬ – условие, когда дисперсии регрессионных остатков не отвечают условию гомоскедастичности. См. гомоскедастичность дисперсии.
ГИСТОГРАММА – это способ представления данных, измеренных в интервальной шкале (как дискретных, так и непрерывных). Часто используется в разведочном анализе данных для иллюстрации основных характеристик распределения. Гистограмма делит диапазон возможных значений множества данных на классы, или группы. Каждой группе соответствует прямоугольник, длина которого равна диапазону значений в заданной группе, а площадь пропорциональна числу наблюдений в этой группе. Это означает, что прямоугольники скорее всего будут различаться по высоте. Гистограмма годится только для числовых переменных, измеренных в номинальной шкале. Как правило, она используется для больших множеств данных (>100 наблюдений), когда не хотят строить диаграммы ствол-лист. Гистограммы помогают выявить необычные наблюдения (выбросы) и пропуски в множестве данных.
ГОМОСКЕДАСТИЧНОСТЬ – условие постоянства дисперсий регрессионных остатков.
ДИСПЕРСИЯ НА ОДНУ СТЕПЕНЬ СВОБОДЫ:
Dобщ = Sобщ /(n-1); Dфак= Sфак / 1; Dост = Sост/ (n-2).
b+t∙mb и b-t∙mb; a+t∙ ma и a-t∙ma.
ИДЕНТИФИКАЦИЯ – это единственность соответствия между приведенной и структурной формами модели.
ИДЕНТИФИЦИРУЕМОСТИ МОДЕЛИ НЕОБХОДИМОЕ УСЛОВИЕ:
Чтобы уравнение было идентифицируемо, необходимо, чтобы число
экзогенных переменных (D), отсутствующих в данном уравнении, но
присутствующих в системе, было равно числу эндогенных переменных в данном уравнении (H) без одного.
D+1=H – уравнение идентифицируемо;
D+1<H – уравнение неидентифицируемо;
D+1>H – уравнение сверхидентифицируемо.
ИДЕНТИФИЦИРУЕМОСТИ МОДЕЛИ ДОСТАТОЧНОЕ УСЛОВИЕ:
Уравнение идентифицируемо, если по отсутствующим в нем экзогенным
и эндогенным переменным можно из коэффициентов при них в других уравнениях системы получить матрицу, определитель которой не равен нулю, а ранг матрицы не меньше, чем число эндогенных переменных в системе без одного.
ИНДЕКС МНОЖЕСТВЕННОЙ КОРРЕЛЯЦИИ:
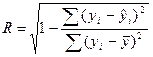 , R Î[0;1].
, R Î[0;1].
Чем ближе R к 1, тем теснее связь рассматриваемых признаков.
КОВАРИАЦИЯ указывает на наличие и вид взаимосвязи между двумя переменными
КОЛЛИНЕАРНОСТЬ ПЕРЕМЕННЫХ - нахождение переменных между собой в линейной зависимости (их парный коэффициент корелляции ≥ 0,7).
КОРРЕЛОГРАММА – график зависимости значений автокорреляционной функции от величины лага.
КОРРЕЛЯЦИЯ – когда говорят, что две случайные переменные коррелированны, имеют в виду, как правило, что они друг с другом как-то связаны. Стандартной мерой связи переменных является коэффициент корреляции. Следует, однако, помнить, что он измеряет лишь силу линейной связи.
КОРРЕЛЯЦИЯ ДЛЯ НЕЛИНЕЙНОЙ РЕГРЕССИИ:
; R Î[0;1].
Чем ближе R к 1, тем теснее связь рассматриваемых признаков.
КОЭФФИЦИЕНТ АВТОКОРРЕЛЯЦИИ уровней ряда первого порядка:
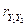 , где Y 1=(y 1, y 2,…, yn -1), Y 2=(y 2, y 3,…, yn).
, где Y 1=(y 1, y 2,…, yn -1), Y 2=(y 2, y 3,…, yn).
КОЭФФИЦИЕНТ ВАРИАЦИИ СЛУЧАЙНОЙ ВЕЛИЧИНЫ x (Vx) – мера относительного разброса случайной величины. Показывает, какую долю среднего значения случайной величины составляет ее средний разброс.
Vx = 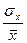 .
.
КОЭФФИЦИЕНТ ДЕТЕРМИНАЦИИ R – характеризует долю дисперсии результативного признака y, объясняемую дисперсией, в общей дисперсии результативного признака. Чем ближе коэффициент детерминации к 1, тем качественнее регрессионная модель, то есть исходная модель хорошо аппроксимирует исходные данные.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ величин x и y (r xy)– свидетельствует о наличии или отсутствии линейной связи между переменными:
r yx =(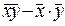 )/(s х s y), r xy Î[-1;1].
)/(s х s y), r xy Î[-1;1].
Если: r xy = -1, то наблюдается строгая отрицательная связь;
r xy = 1, то наблюдается строгая положительная связь;
r xy = 0, то линейная связь отсутствует.
Положительное значение коэффициента корреляции означает, что с ростом одной из переменных другая также растет, с убыванием одной из них убывает и другая. Отрицательное значение означает, что с ростом одной из переменных другая убывает, с убыванием одной из них другая растет. Коэффициент корреляции, равный нулю, означает, что между переменными отсутствует линейная связь. Обратите внимание: даже если коэффициент корреляции равен 1 по абсолютной величине и, следовательно, переменные функционально связаны (линейно), ничего нельзя сказать о причинно-следственной связи между ними. В статистической практике в ходу два коэффициента корреляции: для числовых переменных используется коэффициент корреляции Пирсона, для ранговых – коэффициент корреляции Спирмена.
КОЭФФИЦИЕНТ КОРРЕЛЯЦИИ РАНГОВ Ч.СПИРМЕНА:
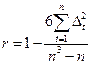 ,
,
где n – число уровней временного ряда;
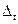 - разность рангов уровней и номеров периодов времени
- разность рангов уровней и номеров периодов времени
КОЭФФИЦИЕНТ ЧАСТНОЙ КОРРЕЛЯЦИИ – измеряет влияние на результат фактора xi при неизменном уровне других факторов:
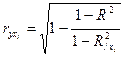 ,
,
где: R 2 – множественный коэффициент детерминации всего комплекса m факторов с результатом;
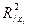 – тот же показатель детерминации, но без введения в модель фактора xi.
– тот же показатель детерминации, но без введения в модель фактора xi.
КРИТЕРИЙ АКАИКЕ (Akaike’s information criterion – AIC). Линейной модели с 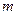 объясняющими переменными, оцененной по
объясняющими переменными, оцененной по 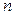 наблюдениям, сопоставляется значение
наблюдениям, сопоставляется значение
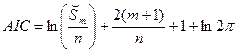
где 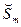 - остаточная сумма квадратов, полученная при оценивании коэффициентов модели методом наименьших квадратов. Предпочтение отдается модели с наименьшим значением
- остаточная сумма квадратов, полученная при оценивании коэффициентов модели методом наименьших квадратов. Предпочтение отдается модели с наименьшим значением 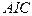 .
.
КРИТЕРИЙ ШВАРЦА (Schwarz’s information criterion – SC, SIC). Линейной модели с объясняющими переменными, оцененной по наблюдениям, сопоставляется значение
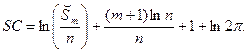
Предпочтение отдается модели с наименьшим значением 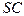 .
.
КРИТЕРИЙ СОГЛАСИЯ – проверяют гипотезу о совпадении наблюденной эмпирической функции распределения с теоретической функцией постулируемого распределения. Критерий согласия хи-квадрат делает это путем сравнения наблюденных и ожидаемых частот. Критерий Колмогорова – Смирнова основывается на максимальной разности между эмпирической и постулируемой функциями распределения.
t- КРИТЕРИЙ СТЬЮДЕНТА ДЛЯ КОЭФФИЦИЕНТА РЕГРЕССИИ при i –м факторе:
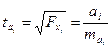 ;
;
F – КРИТЕРИЙ ФИШЕРА:
Fвыч= Dфак / Dост.
Если Fвыч > Fтаб, то уравнение регрессии значимо.
F- КРИТЕРИЙ ФИШЕРА ДЛЯ МНОЖЕСТВЕННОЙ РЕГРЕССИИ:
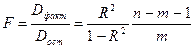 ;
;
где: n – число наблюдений, а m – число параметров при переменных x (в линейной регрессии совпадает с числом включенных в модель факторов).
ЛАГ – число периодов, по которым рассчитывается коэффициент автокорреляции.
ЛИНЕАРИЗАЦИЯ – процессперевода нелинейного уравнения регрессии в линейный вид.
ЛИНЕЙНАЯ РЕГРЕССИЯ – в линейной регрессии модельное (теоретическое, предсказанное) значение Y является линейной комбинацией значений одного или более факторов:
У = а 0 + а 1Х1 + а 2Х2 +...+ а kXk.
МЕДИАНА выборки – это точка, по обе стороны которой располагается одинаковое количество элементов выборки. Если объем выборки нечетен и равен 2n + 1, то медиана равна элементу вариационного ряда с номером n + 1. Если объем выборки четен и равен 2n, то медиана равна полусумме элементов вариационного ряда с номерами n и n + 1.
Пример:
Для нечетного количества данных, скажем, 21, имеем:
Данные 96 48 27 72 39 70 7 68 99 36 95 4 6 13 34 74 65 42 28 54 69
Вариационный ряд: 4 6 7 13 27 28 34 36 39 42 48 54 65 68 69 70 72 74 95 96 99
Медиана равна 48, 10 значений ляжет выше нее, и 10 – ниже.
Для четного количества данных, скажем, 20, мы имеем:
Данные: 57 55 85 24 33 49 94 2 8 51 71 30 91 6 47 50 65 43 41 7
Вариационный ряд 2 6 7 8 24 30 33 41 43 47 49 50 51 55 57 65 71 85 91 94
Медианой в данном случае является среднее двух «серединных» точек, в данном случае среднее между 47 и 49 = 48.
Медиана распределения – это точка m, определяемая аналогичным условием: вероятность того, что случайная величина примет значение, не превосходящее m, равна 1/2.
Медиана выборки является оценкой медианы распределения.
Медиана является робастной оценкой центральной тенденции.
МАТЕМАТИЧЕСКОЕ ОЖИДАНИЕ СЛУЧАЙНОЙ ВЕЛИЧИНЫ –взвешенное среднее всех её фактических значений, причём в качестве весового коэффициента выступает вероятность того или иного значения. МЕТОД ГЛАВНЫХ КОМПОНЕНТ – переход к новым объясняющим переменным, линейным комбинациям старых.
МЕТОД НАИМЕНЬШИХ КВАДРАТОВ – метод оценивания параметров линейной регрессии, минимизирующий сумму квадратов отклонений наблюдений зависимой переменной от искомой линейной функции.
Q=åiei2= åi(у i – aх i - b)2 → min.
где: yi – статистические значения зависимой переменной.
МЕТОД МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ – это общий метод вычисления оценок параметров. Ищутся такие оценки, чтобы функция правдоподобия выборки, равная произведению значений функции распределения для каждого наблюденного значения данных, была как можно большей. М. м. п. лучше работает на больших выборках, где он, как правило, дает оценки с минимальной дисперсией. На маленьких выборках оценки максимального правдоподобия часто оказываются смещенными.
МНОЖЕСТВЕННАЯ РЕГРЕССИЯ – регрессия между переменными y и x 1, x 2,..., х m, то-есть модель вида: y =f(x 1, x 2,..., х m)+ε, где:
y - зависимая переменная (результативный признак),
x 1, x 2,..., х m – независимые, объясняющие, переменные (признак-факторы),
ε - возмущение или стохастическая переменная, включающая влияние
неучтенных в модели факторов.
Основные типы функций, используемые при построении множественной регрессии:
Линейная функция: y = a 0+ а 1 x 1 + а 2 x 2 +,..., + а m х m;
Параметры а 1, а 2,…, а m называются коэффициентами регрессии и характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
Нелинейные функции:
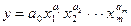 –степенная функция;
–степенная функция;
а 1, а 2,…, а m - коэффициенты эластичности; показывают на сколько % изменится в среднем результат при изменении соответствующего фактора на 1% и при неизменности действия других факторов.
y = 1/(a 0+ а 1 x 1 + а 2 x 2 +,..., + аm хm) – гипербола;
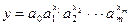 – показательная (экспонента).
– показательная (экспонента).
МНОЖЕСТВЕННОЙ КОРРЕЛЯЦИИ СКОРРЕКТИРОВАННЫЙ ИНДЕКС:
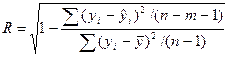 .
.
МОДЕЛИРОВАНИЕ - процесс построения, изучения и применения моделей.
МОДЕЛЬ – объект любой природы, который создается исследователем с целью получения новых знаний об объекте-оригинале и отражает только существенные (с точки зрения разработчика) свойства оригинала.
МОДЕЛЬ ИДЕНТИФИЦИРУЕМА – если все ее структурные коэффициенты определяются однозначно, единственным образом по коэффициентам приведенной формы модели, то есть если число параметров структурной формы модели равно числу параметров приведенной формы модели.
МОДЕЛЬ НЕИДЕНТИФИЦИРУЕМА – если число структурных коэффициентов больше числа приведенных коэффициентов и следовательно, структурные коэффициенты не могут быть оценены через коэффициенты приведенной формы модели.
МОДЕЛЬ СВЕРХИДЕНТИФИЦИРУЕМА – если число структурных коэффициентов меньше числа приведенных коэффициентов и следовательно, на основе приведенных коэффициентов можно получить два или более значений одного структурного коэффициента.
МУЛЬТИКОЛЛИНЕАРНОСТЬ – два или более предиктора коллинеарны, если сильна линейная связь между ними; их можно представить в виде линейной комбинации друг друга. Мультиколлинеарность может сделать проводимые для линейной регрессии вычисления неустойчивыми, а то и невозможными, поскольку в этом случае матрицы плохо обусловлены. Кроме того, она может вызвать завышенные оценки стандартных ошибок для коэффициентов при предсказывающих переменных.
МУЛЬТИПЛИКАТИВНАЯ МОДЕЛЬ – модель вида: Y=T∙S∙E.
НЕЗАВИСИМОСТЬ – две случайные переменные независимы, если их совместная плотность распределения равна произведению отдельных (маргинальных) плотностей. Менее формально: две случайные переменные А и В независимы, если информация о значении В не влияет на распределение вероятностей значений А, и наоборот. Выборка взаимно независимых случайных переменных называется независимой выборкой.
НЕЗАВИСИМАЯ ПЕРЕМЕННАЯ – переменная, используемая для объяснения зависимой переменной.
Синонимы: предиктор, объясняющая переменная.
Смотрите также зависимую переменную.
НЕЛИНЕЙНАЯ РЕГРЕССИЯ – предполагается, что зависимость отклика от предикторов является нелинейной функцией предикторов.
ОБЩАЯ СУММА КВАДРАТОВ ОТКЛОНЕНИЙ (Sобщ):
Sобщ = S2=åi(y i– 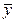 )2.
)2.
ОДНОРОДНОСТЬ – равенство дисперсий переменной, подсчитанных в пределах разных групп. Является стандартным требованием в таких, например, методах, как регрессионный и дисперсионный анализы.
Синоним: гомоскедастичность.
Антоним: гетероскедастичность.
ОСТАТОЧНАЯ СУММА КВАДРАТОВ ОТКЛОНЕНИЙ (Sост):
Sост= Sобщ - Sфакт.
ПАРНАЯ РЕГРЕССИЯ – регрессия между двумя переменными y и x, то есть модель вида: y =f(x)+ε, где:
y - зависимая переменная (результативный признак),
x – независимая, объясняющая, переменная (признак-фактор),
ε - возмущение или стохастическая переменная, включающая влияние
неучтенных в модели факторов.
Основные типы функций, используемые при построении парной регрессии:
Линейная функция: y = ax + b;
Нелинейные функции:
y= a/x+b - гипербола;
y=c+bx+ax 2 – парабола;
y=d+cx+bx 2 +ax 3 - кубический многочлен;
y=bxa –степенная функция;
y=bax -показательная функция;
y=algx+b -логарифмическая функция;
y= 1 /(ax+b);
y=c+bx+a(1/x);
y= 1 /(c+bx+ax 2 );
y=a/( 1 +be-cx).
ПОКАЗАТЕЛЬ КОЛЕБЛЕМОСТИ – отношение среднеквадратического отклонения от тренда к среднему значению показателя
ПОКАЗАТЕЛЬ УСТОЙЧИВОСТИ – разность между единицей и относительным показателем колеблемости.
ПОЛНАЯ МУЛЬТИКОЛЛИНЕАРНОСТЬ – линейная функциональная связь между объясняющими переменными, хотя бы одна из них линейно выражается через остальные
ПРЕДОПРЕДЕЛЕННЫЕ ПЕРЕМЕННЫЕ МОДЕЛИ – все экзогенные переменные модели и лаговые эндогенные переменные.
ПРЕДСКАЗАНИЕ – дает исследователю возможность получить перспективное значение зависимой переменной y по имеющемуся значению независимой переменной x и сравнить его с фактическим значением y. При этом исследователь может определить ошибку предсказания.
ПРЕОБРАЗОВАНИЕ значений данных – производится путем применения одной и той же функции ко всем значениям переменной; важно то, что аргументами такой функции могут являться только значения переменных текущего наблюдения. Распространенными примерами таких операций являются: добавление константы, умножение на константу, взятие логарифма.
ПРИВЕДЕННАЯ ФОРМА МОДЕЛИ – система линейных функций эндогенных переменных от экзогенных.
ПРОГНОЗ – обеспечивает получение перспективного значения зависимой переменой y при неизвестном или известном значении независимой переменной x.
ПРОИЗВОДСТВЕННАЯ ФУНКЦИЯ (production function) – отражает зависимость между количеством применяемых ресурсов и максимально возможным объемом выпускаемой продукции в единицу времени; описывает всю совокупность технически эффективных способов производства (технологий).
РЕГРЕССИОННЫЙ АНАЛИЗ – обеспечивает выбор вида теоретического уравнения регрессии и определяет его параметры
СЕЗОННАЯ КОМПОНЕНТА – один из способов описания временного ряда – разложение его на компоненты: тренд, периодическую и случайную. Когда временная ось связана с датами, а период – с месяцами или кварталами, периодическую компоненту называют сезонной.
СГЛАЖИВАНИЕ, ФИЛЬТРАЦИЯ – сглаживание применяется для уменьшения иррегулярности (случайных изменений) временных рядов. Распространенным методом сглаживания является сглаживание простым скользящим средним (хотя существуют и другие способы). Способ сглаживания определяется свойствами ряда и целями его обработки.
СИСТЕМА ВЗАИМОЗАВИСИМЫХ УРАВНЕНИЙ (система совместных одновременных уравнений) – система в которой одни и те же зависимые переменные в одних уравнениях входят в левую часть, а в других уравнениях – в правую.
СИСТЕМА НЕЗАВИСИМЫХ УРАВНЕНИЙ – система, в которой каждая зависимая переменная y рассматривается как функция одного и того же набора факторов x.
СИСТЕМА РЕКУРСИВНЫХ УРАВНЕНИЙ – система, в которой зависимая переменная одного уравнения выступает в виде фактора в другом уравнении.
СЛУЧАЙНАЯ ВЕЛИЧИНА – любой экономический параметр или показатель, значение которого в перспективе не может быть точно предсказано.
СРЕДНЯЯ КВАДРАТИЧЕСКАЯ ОШИБКА КОЭФФИЦИЕНТА РЕГРЕССИИ:
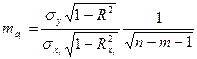 ;
;
где: σy –среднее кавдратическое отклонение для признака y;
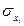 – среднее квадратическое отклонение для признака xi;
– среднее квадратическое отклонение для признака xi;
R 2 – коэффициент детерминации для уравнения множественной регрессии;
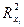 – коэффициент детерминации для зависимости фактора xi со всеми другими факторами уравнения множественной регрессии;
– коэффициент детерминации для зависимости фактора xi со всеми другими факторами уравнения множественной регрессии;
n-m -1 – число степеней свободы для остаточной суммы квадратов отклонений.
СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ:
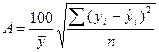 .
.
СТАНДАРТНОЕ ОТКЛОНЕНИЕ СЛУЧАЙНОЙ ВЕЛИЧИНЫ x (σx) - мера разброса случайной величины вокруг среднего значения.
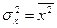 – (
– (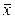 )2.
)2.
СТАНДАРТНЫЕ ОШИБКИ КОЭФФИЦИЕНТОВ РЕГРЕССИИ:
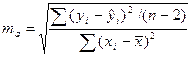 ;
; 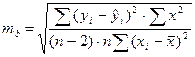 .
.
СТАТИСТИКА – это функция элементов выборки. Дает информацию о неизвестных значениях параметров генеральной совокупности. Например, среднее выборки является, как правило, оценкой среднего совокупности, из которой была взята выборка.
СТАТИСТИЧЕСКАЯ НЕЗАВИСИМОСТЬ – отсутствие связи между переменными. Независимость двух непрерывных переменных часто ошибочно отождествляют с равенством нулю их корреляции (ковариации), однако это верно, только если они подчиняются двумерному нормальному распределению.
СТАТИСТИЧЕСКИЙ КРИТЕРИЙ – статистический критерий состоит из следующих компонент: пара гипотез – нулевая и альтернативная, статистика критерия и уровень значимости; по ним находится критическая область. Проверка гипотезы начинается с вычисления статистики. Если значение попадает в критическую область, мы отвергаем нулевую гипотезу и считаем истинной ее альтернативу. В противном случае у нас нет оснований отвергнуть нулевую гипотезу. Из генеральной совокупности можно сделать много разных выборок, причем значение статистики в общем случае будет меняться от выборки к выборке; другими словами, выборка является случайной, а значит, случайной величиной является и статистика.
Например, выборочные средние для разных выборок из одной и той же совокупности могут различаться между собой. Статистики обычно обозначают латинскими буквами, а оцениваемые ими параметры – греческими.
СТАЦИОНАРНЫЕ показатели – показатели, среднее которых можно считать неизменным; нестационарными – называются показатели, среднее которых изменяется со временем. Системы одновременных эконометрических уравнений являются третьим основным классом моделей, которые применяются для анализа и (или) прогноза. Эти модели описываются системами уравнений, которые могут состоять из тождеств и регрессионных уравнений, каждое из которых может, кроме объясняющих переменных, включать в себя также объясняемые переменные из других уравнений системы. Т.е. набор объясняемых переменных связан через уравнения системы.
ТАБЛИЦА СОПРЯЖЕННОСТИ – таблица (ТС), каждый элемент (клетка) которой соответствует клетке кросс-табуляции. В случае двух факторов клетки ТС располагают так, чтобы элементы одной строки соответствовали одному и тому же значению одного фактора, а элементы одного столбца – одному и тому же значению другого фактора; говорят, что уровни одного фактора расположены по строкам, а другого – по столбцам. Такие таблицы часто обозначают rхc, где r – количество уровней фактора, соответствующего строкам, с – столбцам. В случае трех факторов считают, что ТС состоит из совокупности ТС, каждая из которых соответствует значению третьего фактора, являясь при этом (условной) ТС первых двух факторов. Можно, конечно, построить ТС и для большего числа факторов. В каждой клетке ТС стоит количество элементов соответствующей клетки кросс-табуляции. ТС – не слишком удобный способ представления данных для их визуального анализа, если велико количество уровней факторов, тем более, если велико количество факторов. Для проверки гипотезы о независимости факторов, по которым построена кросс-табуляция, используется критерий независимости хи-квадрат Пирсона. Для таблиц 2х2 (два фактора, по два уровня у каждого) используется также точный критерий Фишера. Общий метод анализа таблиц сопряженности – логлинейный анализ.
ТРЕНД – это долговременное изменение временного ряда. Это направление (тенденция к повышению или снижению) и скорость изменения временного ряда, при сделанных допущениях о других компонентах.
ФАКТИЧЕСКОЕ ЗНАЧЕНИЕ t-КРИТЕРИЯ СТЬЮДЕНТА:
tb=b/mb; ta=a/ma.
ФАКТОРНАЯ СУММА КВАДРАТОВ ОТКЛОНЕНИЙ (Sфакт):
Sфакт = Ŝ2= åi (ŷ i – )2.
ФИКТИВНЫЕ ПЕРЕМЕННЫЕ – это факторы, которые желательно ввести в состав регрессионного уравнения, но они не поддаются количественной оценке.
ЧАСТНЫЙ F-КРИТЕРИЙ ФИШЕРА МОДЕЛИ МНОЖЕСТВЕННОЙ РЕГРЕССИИ для фактора xi:
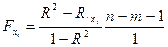 ;
;
где в числителе показан прирост доли объясненной вариации y за счет дополнительного включения в модель соответствующего фактора. А в знаменателе – доля остаточной вариации по регрессионной модели, включающей полный набор факторов.
ЧАСТИЧНАЯ МУЛЬТИКОЛЛИНЕАРНОСТЬ – тесная, но не функциональная связь между объясняющими переменными.
ЧАСТНОЕ УРАВНЕНИЕ МНОЖЕСТВЕННОЙ РЕГРЕССИИ - уравнение регрессии, которое связывает результативный признак с соответствующими факторами x при закреплении других учитываемых в уравнении регрессии факторов на среднем уровне.
ЦИКЛИЧЕСКАЯ КОМПОНЕНТА – чтобы лучше понять поведение временного ряда, выделяют его основные характеристики. Одной из таких характеристик является циклическая компонента. В недельных или месячных данных циклическая компонента описывает любые регулярные колебания. Это не сезонная компонента, изменение которой подчиняются некоторому распознаваемому циклу.
ЭКОНОМЕТРИКА – научная дисциплина, разрабатывающая и использующая методыматематического и статистического анализа, позволяющие придавать конкретное количественное выражение общим (качественным) закономерностям экономической теории.
ЭКОНОМЕТРИЧЕСКАЯ МОДЕЛЬ – вероятностно-статистическая модель, описывающая механизм функционирования экономической или социально-экономической системы. Модель адекватна объекту-оригиналу – если она с достаточной степенью точности приближения отражает закономерности процесса функционирования реального объекта.
ЭКЗОГЕННАЯ ПЕРЕМЕННАЯ – переменная, значение которой определяется вне пределов модели (уравнения) и принимается как заданное.
ЭКСПОНЕНЦИАЛЬНОЕ СГЛАЖИВАНИЕ – метод сглаживания временного ряда, используемый для уменьшения иррегулярности (случайных колебаний) временного ряда, что позволяет получить более ясное представление о лежащих в основе этого ряда закономерностях. Используется также для прогнозирования значения ряда (для 1-2 шагов) прогноза.
ЭКСТРАПОЛЯЦИЯ – предсказание значения переменной за пределами интервала анализа. Термин применяется, как правило, при анализе временных рядов. Для коротких промежутков времени применяются количественные предсказания, интерполяции. Количественное предсказание далекого будущего, как правило, менее полезно и применяется для указания на необходимость изменения построенной модели.
ЭНДОГЕННАЯ ПЕРЕМЕННАЯ – её значение определяется внутри модели в существенной мере под воздействием экзогенных переменных и во взаимодействии друг с другом. В эконометрическом моделировании являtтся предметом объяснения.
СПИСОК РЕКОМЕНДУЕМОЙ ЛИТЕРАТУРЫ
Основная
1. Новиков, А. И. Эконометрика: учеб. пособие по направлению 521600 "Экономика" и экон. специальностям / А. И. Новиков. -М.: ИНФРА-М, 2008. -143с.
2. Кремер, Н. Ш. Эконометрика: Учеб. для вузов / Н. Ш. Кремер, Б. А. Путко.-М.: ЮНИТИ, 2007. -310с.
3. Бывшев, В. А. Эконометрика: учеб. пособие / В. А. Бывшев. -М.: Финансы и статистика, 2008. -477с.
Дополнительная
4. Гладилин, А. В. Эконометрика: Учеб. пособие для вузов / А. В. Гладилин, А. Н. Герасимов, Е. И. Громов. -М.: КноРус, 2006. -226с.
5. Салманов, О. Н. Эконометрика: учеб. пособие для вузов / О. Н. Салманов -М.: Экономистъ, 2006. -317с.
6. Эконометрика: учебник / К. В. Балдин, В. Н. Башлыков, Н. А. Брызгалов и др.; под ред. В. Б. Уткина. -М.: Дашков и К, 2008. -304 с.
7. Кочетыгов, А. А. Основы эконометрики: учебное пособие для вузов / А.А.Кочетыгов, Л.А.Толоконников.-М.; Ростов н/Д: Март, 2007.-343 с.
8. Афанасьев, В. Н. Эконометрика: учеб. для вузов / В. Н. Афанасьев, М. М. Юзбашев, Т. И. Гуляева; под ред. В. Н. Афанасьева. -М.: Финансы и статистика, 2006. -255 с.
9. Суслов В.И., Ибрагимов Н.М., Талышева Л.П., Цыплаков А.А. Эконометрия. Новосибирск, 2003.
10. Эконометрика: Учебник./ Под ред. И.И. Елисеевой. – 2-е изд.– М.: Финансы и статистика, 2005. – 276 с.
11. Практикум по эконометрике. Под ред. И.И.Елисеевой. – М.: Финансы и статистика, 2005.
12. Мхитарян В.С., Архипова М.Ю., Сиротин В.П. Эконометрика: Учебно-методический комплекс. – М.: Изд. центр ЕАОИ. 2008. – 144 с.
13. Доугерти Кр. Введение в эконометрику/ Пер. с англ. – М.: МГУ; ИНФРА-М, 2003.
14. Дубров А.М., Мхитарян В.С., Трошин Л.И. Математическая статистика для бизнесменов и менеджеров. – М.: МЭСИ, 2004. – 140 с.
15. Магнус Я.Р., Катышев П.К., Пересецкий А.А. Эконометрика. Начальный курс, 3-е изд. – М.: Дело, 2005. – 503 с.
16. Мхитарян В.С., Трошин Л.И. Исследование зависимостей методами корреляции и регрессии. – М.: МЭСИ, 2004. – 51 с.
17. Айвазян С.А., Мхитарян В.С. Практикум по прикладной статистике и эконометрике. – М.: МЭСИ, 2003.
INTERNET-ресурсы
1. http://upereslavl.botik.ru/UP/ECON/econometrics/top1/tsld006.htm
2. http://www.nsu.ru/ef/tsy/ecmr/study.htm
3. http://www.nsu.ru/ef/tsy/ecmr/index.htm
4. http://www.statsoft.ru/home/textbook/def ault.htm
5. http://www.nsu.ru/ef/tsy/ecmr/study.htm
6. http://www.dataforce.net/~antl/article/econometric
7. http://www.nsu.ru/ef/tsy/ecmr/study.htm
8. http://www.tvp.ru/vnizd/mathem4.htm
9. http://www.kgtu.runnet.ru/WD/TUTOR/textbook/modules/stmulreg.html
10. http://www.shpargalka.ru/statis.ru/doc/shpr_e31.htm
11. http://www3.unicor.ac.ru/d024/p011993.htm
12. http://www.gauss.ru/educat/systemat/butenkov/.asp
13. http://crow.academy.ru/econometrics/seminars_/sem_08_/sem_08.htm
14. http://crow.academy.ru/econometrics/lectures_/lect_03_/index.htm
15. http://u-pereslavl.botik.ru/UP/ECON/econometrics/
16. http://crow.academy.ru/econometrics
17. http://www.econ.msu.ru/kaf/DEI/books/prognoz.html
18. http://socgw.univ.kiev.ua/EDUCAT/BASIC/MMPS/LABS/LOGREG.HTM
19. http://www.nsu.ru/ef/tsy/ecmr/some_mle/contents.htm
20. http://www.doktor.ru/doctor/biometr/sp/contents4.htm
21. http://www.kgtu.runnet.ru/WD/TUTOR/textbook/modules/stnonlin.html
22. http://dsmu.donetsk.ua/~statbook/modules/stnonlin.html
23. http://softline.perm.ru/statistica/wwwpage_STATISTICA_for_Windows.html
24. http://eco.rea.ru/LSpace/EconTh.nsf/136acc8cc4a429f5c325654d004b4fc2
25. http://lanserv2.kemsu.ru/departs/matekon/Chapter4/par4_4.html
26. http://www.dvgu.ru/pin/math/for_students/eco/node4.html
27. http://www.hse.ru/rectorat/grebnev/economics/glava13.htm
28. http://ecfor.rssi.ru/0497_r_k.htm
29. http://www.mstu.edu.ru/publish/conf/section5/section5_7.html
30. http://www.econ.msu.ru/kaf/DEI/books/prognoz/lec13.html
31. http://www.bsu.unibel.by/fpmi/bsa/ppp.htm
32. http://vega.math.spbu.ru/caterpillar/en/intro.html
33. http://iai.dn.ua/general/ai_annot.php
34. http://www.biophys.msu.ru/scripts/trans.pl/rus/cyrillic/awse/CONFER
35. http://ecfor.rssi.ru/0497_r_k.htm
36. http://www.codenet.al.ru/progr/packing/arithm/arithm10.htm
37. http://vm.fesma.ru/Gloss/Ag.htm
38. http://bytic.ttk.ru/cue99M/cz586tufhu.html
39. http://www.econ.msu.ru/kaf/DEI/books/prognoz/lec 13.html
40. http://www.bsu.unibel.by/fpmi/bsa/ppp.htm
41. http://www.tvp.ru/ourizd/oppm1996.htm
42. http://vega.math.spbu.ru/caterpillar/en/intro.html
43. http://www.tstu.ru/koi/tgtu/publ/1996/w96_35.htm
44. http://comsci.dsu.dp.ua/russian/curriculums/content/T_chos27.htm
45. http://www.nes.ru/~sanatoly/CV2000rus.htm
46. http://www.cemi.rssi.ru/rus/publicat/e-pubs/ep97001/1.htm
47. http://www.freeware32.ru/download.php3?id=1335 – 17К
48. http://www.nes.ru/Acad_year_2001/Prob_Stat.htm
49. http://comsci.dsu.dp.ua/bgv/articles/statistd.htm
50. http://www.eu.spb.ru/econ/courses/s8-00.htm
51. http://www.math.dcn-asu.ru/md/k5/material/f3-3_ru.html
52. http://www.book.ru/cgi/expo.cgi?book=13141 – 2К
53. http://infovisor.ivanovo.ru:8000/rus/press/paper04.htm

