 2015-04-08
2015-04-08 14242
142421. Ранжируем вариационный ряд с помощью команды Сортировка на вкладке Главная в группе Редактирование и определяем максимальное 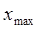 и минимальное
и минимальное 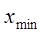 значения жирности молока.
значения жирности молока.
2. Определяем размах выборки по формуле 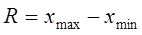 и число интервалов
и число интервалов  по объему выборки (количество всех значений выборки) в соответствующей таблице.
по объему выборки (количество всех значений выборки) в соответствующей таблице.
Таб.2 Количество интервалов по объему выборки
| n | 15-20 | 25-30 | 35-60 | 65-100 |
| k |
3. Так как интервалы значений должны быть приблизительно одинаковые, то длина каждого интервала (шаг) вычисляется по формуле 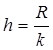 . В результате операции деления может получиться величина с большим разрядом точности, в этом случае округляем значение до разряда точности величин задачи (в нашем случае до сотых долей).
. В результате операции деления может получиться величина с большим разрядом точности, в этом случае округляем значение до разряда точности величин задачи (в нашем случае до сотых долей).
4. Вычисляем границы интервалов по схеме:
| № п/п | Границы интервала |
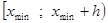 | |
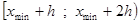 | |
| …. | ………….. |
| k | 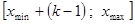 |
5. Высоту прямоугольников определяет накопленная частота 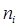 интервала – это количество значений выборки, которые попадают в данный промежуток. Необходимо заметить, что значение правой границы не включается в рассматриваемый интервал. Из-за округления величины шага последняя граница может получиться больше или меньше максимального значения, поэтому в любом случае правая граница последнего интервала – это максимальное значение выборки.
интервала – это количество значений выборки, которые попадают в данный промежуток. Необходимо заметить, что значение правой границы не включается в рассматриваемый интервал. Из-за округления величины шага последняя граница может получиться больше или меньше максимального значения, поэтому в любом случае правая граница последнего интервала – это максимальное значение выборки.
6. Далее вычисляется относительная накопленная частота (частость) для каждого промежутка по формуле 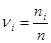 , где
, где 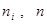 - накопленная частота интервала и объем выборки соответственно.
- накопленная частота интервала и объем выборки соответственно.
| № п/п | Границы интервала | | |
| 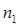 | 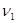 | |
| 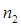 | 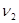 | |
| …. | ………….. | ….. | ….. |
| k | | 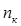 | 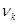 |
7. Последним шагом будет построение гистограммы наблюдения с помощью Гистограммы в группе Гистограммы на вкладке Вставка.
Применим описанный алгоритм к решению нашей задачи.
a) Ранжируем ряд и находим размах выборки 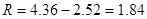
b) Вычисляем количество интервалов при объеме равном 50 и величину шага 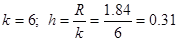
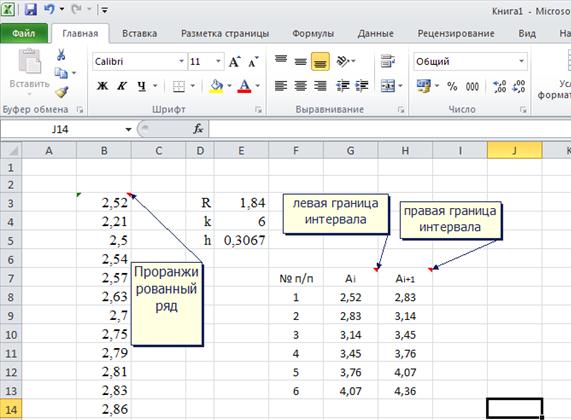
c) Определяем границы интервалов согласно схеме п.4 алгоритма построения гистограммы
Рис. 8 Определение границ интервалов
d) Следующим этапом будет определение накопленной и относительной частот
Рис.9 Значения накопленных и относительных частот

e) Выделяем столбец относительной частоты, строим гистограмму (рис.10а, 10б)
Рис.10а Выбор типа диаграммы
Рис.10б Выбор данных осей координат
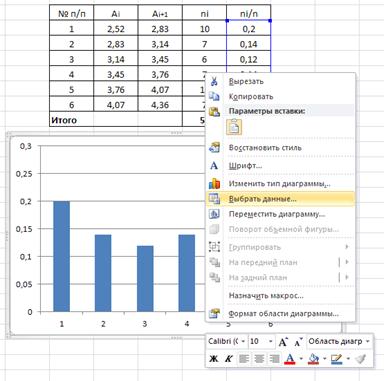
По оси ординат откладываются значения относительных частот, а по оси абсцисс – границы интервалов. Для отоброжения значений границ интервала на гистограмме необходимо активизировать диаграмму щелкнув по ней курсором, правой кнопкой мыши вызвать контекстное меню (см. рис.10б) и выбрать раздел Выбрать данные… В открывшемся диалоговом окне Выбор источника данных изменить подписи горизонтальной оси.
Рис. 11а Определение подписи осей
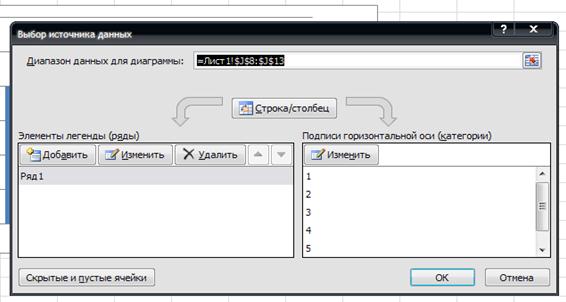
С помощью кнопки Изменить вводим данные границ интервалов (см.рис.11а)
Рис. 11а Определение подписей осей гистограммы


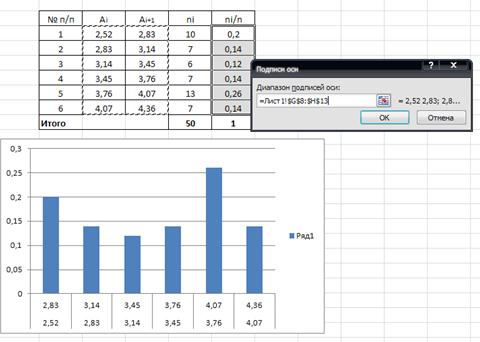
Примерный итоговый результат представлен на рис.11б
Рис.11б Гистограмма результатов проверки жирности молока коров.
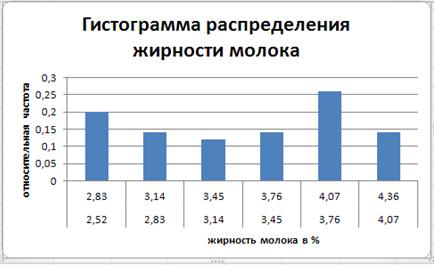
Наибольшую высоту имеет интервал номер 5, который является в данном случае модой распределения. Само значение моды в случае непрерывного типа исследуемого признака определяется по формуле 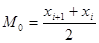 , где
, где 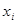 - левая граница,
- левая граница, 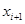 - правая граница рассматриваемого промежутка. Для нашего случая
- правая граница рассматриваемого промежутка. Для нашего случая 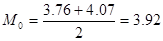 , т.е. среднее значение величин, которые чаще встречаются в выборке. Еще одной числовой характеристикой распределения жирности молока является медиана (
, т.е. среднее значение величин, которые чаще встречаются в выборке. Еще одной числовой характеристикой распределения жирности молока является медиана (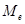 ) – значение варианты, которое делит выборку на две равные части. Т.к. середина находится между 3 и 4 интервалами, то берется среднее значение этих интервалов – в нашем случае оно равно 3,45. Если медиана приходится на интервал, то ее значение равно середине этого промежутка. Условно величину медианы можно принять за среднее выборочное.
) – значение варианты, которое делит выборку на две равные части. Т.к. середина находится между 3 и 4 интервалами, то берется среднее значение этих интервалов – в нашем случае оно равно 3,45. Если медиана приходится на интервал, то ее значение равно середине этого промежутка. Условно величину медианы можно принять за среднее выборочное.
Среднее выборочное определяется по формуле
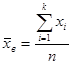 или
или 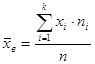 (1)
(1)
Где - значения вариант, 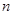 - объем выборки,
- объем выборки, 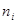 - накопленная частота варианты (интервала), к – количество элементов совокупности (интервалов).
- накопленная частота варианты (интервала), к – количество элементов совокупности (интервалов).
Рассмотрим вычисление среднего выборочного в условиях предыдущей задачи. Разложим формулу 1 по действиям и поместим результат в таблицу.
Рис. 12 Разложение формулы по столбцам
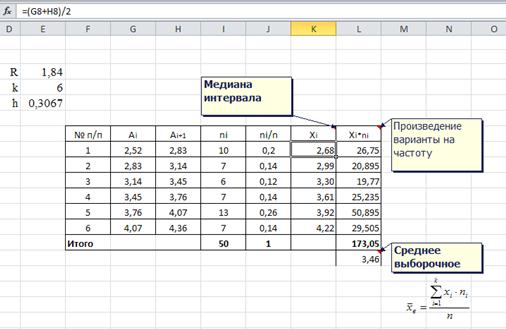
В случае с дискретным признаком берется конкретное значение варианты.
Кроме среднего выборочного еще одной числовой характеристикой вариационного ряда является выборочная дисперсия. Она показывает средний квадрат отклонения данных вариационного ряда от его среднего значения (мера рассеяния).
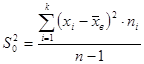 (2)
(2)
Где - значения вариант, - объем выборки, - накопленная частота варианты (интервала), к – количество элементов совокупности (интервалов), 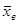 . – среднее выборочное вариационного ряда.
. – среднее выборочное вариационного ряда.
Для удобства поместим все вычисления в таблицу
| № п/п | Ai | Ai+1 | ni | Xi | Xi*ni | Xi-Xв | (Xi-Xв)^2 | (Xi-Xв)^2*ni |
| 2,52 | 2,83 | 2,68 | 26,75 | -0,79 | 0,62 | 6,18 | ||
| 2,83 | 3,14 | 2,99 | 20,895 | -0,48 | 0,23 | 1,59 | ||
| 3,14 | 3,45 | 3,30 | 19,77 | -0,17 | 0,03 | 0,17 | ||
| 3,45 | 3,76 | 3,61 | 25,235 | 0,14 | 0,02 | 0,15 | ||
| 3,76 | 4,07 | 3,92 | 50,895 | 0,45 | 0,21 | 2,68 | ||
| 4,07 | 4,36 | 4,22 | 29,505 | 0,75 | 0,57 | 3,98 | ||
| Итого | 173,05 | 14,73 |
Подставим полученные данные в формулу для выборочной дисперсии (2)

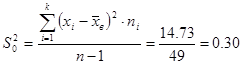
Ещё одной характеристикой меры рассеяния является среднеквадратичное отклонение, которое находится по формуле (3)
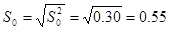 (3)
(3)
Данная величина показывает, что наибольшее количество значений лежит в интервале от 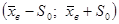 . Т.е. оптимальный показатель жирности молока находится в интервале (2,95; 4,01).
. Т.е. оптимальный показатель жирности молока находится в интервале (2,95; 4,01).
Рассмотренные ранее числовые характеристики – выборочное среднее, выборочная дисперсия, среднее квадратичное отклонение - относятся к точечным оценкам истинного параметра ранжированного ряда, т.к. характеризуются числом (точка на числовой оси).
Кроме точечных оценок существуют интервальные оценки истинного параметра распределения.
Интервальная оценка – доверительный интервал 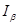 , который накрывает истинное значение параметра с заданной доверительной вероятность
, который накрывает истинное значение параметра с заданной доверительной вероятность 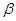 . С помощью него можно оценивать различные параметры генеральной совокупности.
. С помощью него можно оценивать различные параметры генеральной совокупности.
Построение доверительного интервала осуществляется по следующей схеме: точечная оценка параметра - / + квантиль распределения * стандартная ошибка.
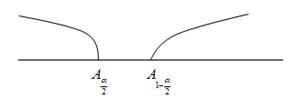
Где 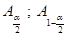 значения вкантилей соответствующих распределений
значения вкантилей соответствующих распределений
(см. табл.3).
Ниже приводится таблица для построения интервальной оценки параметра распределения.
Табл. 3 Построение интервальной оценки
| Параметр | Интервальная оценка | |
| Математическое ожидание | (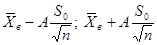 ) ) | Среднее выборочное 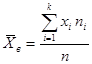 ; Распределение Стьюдента А= ; Распределение Стьюдента А= 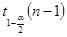 - если - если 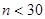 Стандартное нормальное распределение А= Стандартное нормальное распределение А= 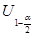 - если - если 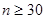 ; ; 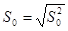 - среднеквадратическое отклонение - среднеквадратическое отклонение |
| Дисперсия | (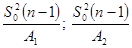 ) ) | Выборочная дисперсия 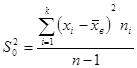 ; Распределение Хи-квадрат ; Распределение Хи-квадрат 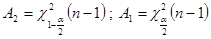 |
| Доля признака | 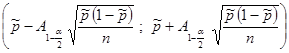 | Стандартное нормальное распределение А= ; 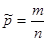 - выборочная доля признака; - выборочная доля признака; 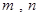 - число благоприятных и всевозможных исходов соответственно - число благоприятных и всевозможных исходов соответственно |
5. По заданному значению среднего квадратичного отклонения нормально распределенной случайной величины равным 9, с выборочным средним 18,31 и объемом выборки в 49 элементов построить доверительный интервал для математического ожидания с заданной надежностью 0,95.
Запишем данные задачи математическим языком
Дано: 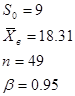 | Решение 1). Т.к. интервал необходимо построить для математического ожидания и выборка малого объема , то воспользуемся следующей формулой (), где А= - квантиль распределения Стьюдента. |
2). Значения квантилей зависит от уровня значимости 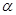 и числа степеней свободы
и числа степеней свободы 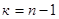 , определяется по специальным статистическим таблицам или с помощью статистических функций Microsoft Excel. Надежность и уровень значимости связаны между собой соотношением
, определяется по специальным статистическим таблицам или с помощью статистических функций Microsoft Excel. Надежность и уровень значимости связаны между собой соотношением 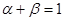 . Используя его определим значение уровня значимости
. Используя его определим значение уровня значимости 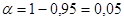 и вероятность квантиля
и вероятность квантиля 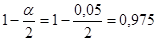 . Число степеней свободы равно
. Число степеней свободы равно 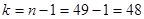 . По таблице Приложения 1 находим квантиль
. По таблице Приложения 1 находим квантиль 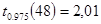 . Аналогичный результат получим вычисляя квантиль через функцию СТЬЮДЕНТ.ОБР Microsoft Excel.
. Аналогичный результат получим вычисляя квантиль через функцию СТЬЮДЕНТ.ОБР Microsoft Excel.
3). Подставляем числовые значения в формулу доверительного интервала для математического ожидания
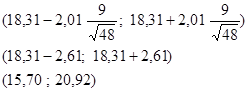
4). Полученный результат означает, что с вероятность 97,5 % истинное значение параметра будет лежать в этом интервале. Изменяя уровень значимости интервальная оценка будет меняться.
6. Результаты 10 независимых измерений длины стержня (мм): 32, 35, 33, 34, 33, 32, 36, 36, 32, 35. Построить доверительный интервал для дисперсии с доверительной вероятностью 0,95.
Дано: 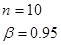 | Решение 1). Доверительный интервал для дисперсии строится по формуле (), где 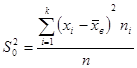 - выборочная дисперсия; -квантили распределение Хи-квадрат. - выборочная дисперсия; -квантили распределение Хи-квадрат. |
2). Так же как квантили распределения Стьюдента значения квантилей Хи-квадрат зависят от уровня значимости и числа степеней свободы . Используя соотношение надежности и уровня значимости , определим вероятности квантилей
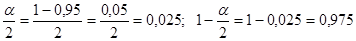 .
.
Число степеней свободы равно 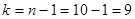 . По таблице Приложения 4 находим квантили
. По таблице Приложения 4 находим квантили 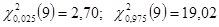 либо через функцию ХИ2.ОБР Microsoft Excel.
либо через функцию ХИ2.ОБР Microsoft Excel.
3). В условии задания нет значения выборочной дисперсии, но есть результаты измерений длины стержня, которые образуют выборку малого объема. Определим точечную оценку дисперсии, результат вычислений представим в виде таблицы
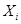 | | 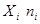 | 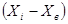 | 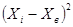 | 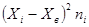 |
| -1,8 | 3,24 | 9,72 | |||
| -0,8 | 0,64 | 1,28 | |||
| 0,2 | 0,04 | 0,04 | |||
| 1,2 | 1,44 | 2,88 | |||
| 2,2 | 4,84 | 9,68 | |||
| Итого | 23,6 |
Итоговый результат: среднее выборочное 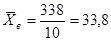 ; выборочная дисперсия
; выборочная дисперсия 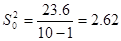 . Доверительный интервал для дисперсии будет выглядеть следующим образом
. Доверительный интервал для дисперсии будет выглядеть следующим образом
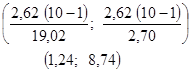
4). С вероятность 97,5 % интервал накрывает истинное значение параметра.
Доверительный интервал характеризуется точностью 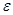 - длина интервала и надежностью - вероятность накрыть истинное значение параметра. Интервал может быть надежным или точным, т.к. с увеличением надежности точность уменьшается и, наоборот, с увеличением точности - надежность уменьшается. Для определения объема выборки с заданной точностью используют результаты наблюдений по пробной выборке. Рассмотрим более конкретно на примере.
- длина интервала и надежностью - вероятность накрыть истинное значение параметра. Интервал может быть надежным или точным, т.к. с увеличением надежности точность уменьшается и, наоборот, с увеличением точности - надежность уменьшается. Для определения объема выборки с заданной точностью используют результаты наблюдений по пробной выборке. Рассмотрим более конкретно на примере.
7. Специалист ОТК производил измерения 25 пакетов некоторого стандартно расфасованного продукта. В результате получил следующие данные: средний вес оказался 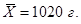 , стандартное отклонение
, стандартное отклонение 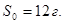 каким должен быть объем выборки, чтобы установить 95 % - ный интервал с точностью 5 гр.
каким должен быть объем выборки, чтобы установить 95 % - ный интервал с точностью 5 гр.
Дано: 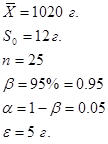 | Решение: Выборка, произведенная специалистом, маленькая (), поэтому определим квантиль распределения Стьюдента с вероятностью 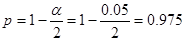 и числом степеней свободы и числом степеней свободы 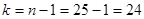 , по таблице квантилей t-распределения (приложение 1) определяем , по таблице квантилей t-распределения (приложение 1) определяем |
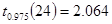 Поскольку
Поскольку 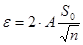 , подставив известные значения, получаем
, подставив известные значения, получаем 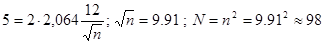 . И так, для построения интервала с точностью
. И так, для построения интервала с точностью 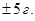 и вероятностью 5 % необходимо отобрать 98 пакетов стандартно расфасованного продукта.
и вероятностью 5 % необходимо отобрать 98 пакетов стандартно расфасованного продукта.
Примечание. Если выборка большая, объем , то квантиль t – распределения заменяется на квантиль стандартного нормального распределения . В случае оценки объема выборки для доли признака используется формула 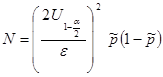 , где
, где 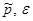 - оценка доли признака и точность интервала соответственно.
- оценка доли признака и точность интервала соответственно.
8. Требуется составить эмпирическую функцию распределения группированной выборки (см. условие задачи 4) и построить ее график.
Значения эмпирической функции распределения для статистики определяются следующим образом
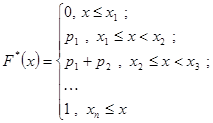
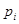 - относительная накопленная частота интервала (варианты), - значение варианты или медианы интервала, - число интервалов или количество всех значений варианты. Эмпирическая функция распределения служит приближенным значением функции распределения генеральной совокупности
- относительная накопленная частота интервала (варианты), - значение варианты или медианы интервала, - число интервалов или количество всех значений варианты. Эмпирическая функция распределения служит приближенным значением функции распределения генеральной совокупности 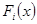 в каждой точке
в каждой точке 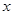 .
.
Воспользуемся группировкой произведенной в задаче 4
| № п/п | 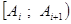 | 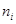 | | 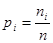 | 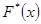 | |
| 2,52 | 2,83 | 2,68 | 0,20 | |||
| 2,83 | 3,14 | 2,99 | 0,14 | 0,20 | ||
| 3,14 | 3,45 | 3,30 | 0,12 | 0,34 | ||
| 3,45 | 3,76 | 3,61 | 0,14 | 0,46 | ||
| 3,76 | 4,07 | 3,92 | 0,26 | 0,60 | ||
| 4,07 | 4,36 | 4,22 | 0,14 | 0,86 | ||
| Итого |
По оси ординат откладываем значения эмпирической функции распределения, по оси абсцисс - середины интервалов, график имеет ступенчатый вид. Если соединить плавной линией точки графика, соответствующие концам интервалов, то получим кривую, которая доопределяет значения эмпирической функции распределения исследуемого признака, т.к. в таблице указаны не все ее значения.
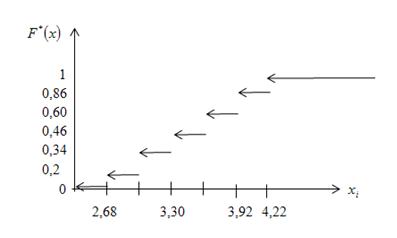
Рис. 13 График эмпирической функции распределения
9. Компания, выпускающая в продажу новый сорт кофе, провела проверку вкусов покупателей по случайной выборке из 400 человек и выяснила, что 220 из них предпочли новый сорт всем остальным. Проверьте на уровне значимости
α = 0,01 гипотезу о том, что, по крайней мере, 52% потребителей предпочтут новый сорт кофе.
Статистическая гипотеза – предположение о генеральной совокупности, которое проверяют по выборочной совокупности (по результатам наблюдений).
Проверка гипотезы – с помощью определенных правил высказанную гипотезу сопоставляют с выборочными данными и делают вывод о том, можно принять гипотезу или нет.
Рассмотрим этапы проверки гипотезы.
1 этап. По выборочным данным и руководствуясь конкретными условиями задачи, формулируем гипотезы 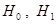 .
. 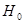 является основной или нулевой гипотезой,
является основной или нулевой гипотезой, 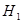 - конкурирующая гипотеза по отношению к основной. Конкурирующую гипотезу также называют альтернативной, это означает, что два события являются взаимоисключающими:
- конкурирующая гипотеза по отношению к основной. Конкурирующую гипотезу также называют альтернативной, это означает, что два события являются взаимоисключающими:
- по выборке принимается решение о справедливости для генеральной совокупности гипотезы 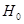 ;
;
- по выборке принимается решение о справедливости для генеральной совокупности гипотезы .
2 этап. Задается вероятность , которую называют уровнем значимости. Решение о том, можно ли считать верным высказывание принимается по выборочным данным, т.е. по ограниченному объему информации. Следовательно, принятое решение может быть ошибочным, здесь имеет место ошибка двух родов:
| Верная гипотеза | Принимается | |
| | |
| - | Ошибка первого рода; - вероятность ошибки |
| Ошибка второго рода; - вероятность ошибки | - |
Поскольку проверка осуществляется относительно основной гипотезы, то ее вероятность задается малым числом, обычно используются стандартные значения: 0,05; 0,01; 0,005. Например, если 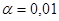 , то проверяя каждую выборку из 100 элементов на предмет одинакового объема, в среднем в одном случае из 100 совершим ошибку первого рода.
, то проверяя каждую выборку из 100 элементов на предмет одинакового объема, в среднем в одном случае из 100 совершим ошибку первого рода.
3 этап. Определяют величину К – статистику такую, что
- ее значения зависят от выборочных данных;
- величина К подчиняется некоторому известному закону распределения при выполнении основной гипотезы ;
- ее значения позволяют судить о расхождении гипотезы с выборочными данными.
В зависимости от формулировки основной гипотезы используют следующие статистики и законы распределения (см. табл.)
| Величина | Статистика (К) | Закон |
Математическое ожидание 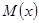 | 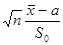 | Распределение Стьюдента 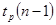 - если Стандартное нормальное распределение - если Стандартное нормальное распределение 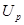 - если - если |
| Доля признака p | 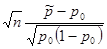 | Стандартное нормальное распределение - если |
Дисперсия 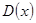 | 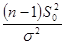 | Распределение Хи-квадрат 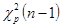 |
Разность долей признака 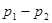 | 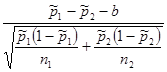 | Стандартное нормальное распределение |
Где n – объем выборки, 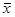 - выборочное среднее,
- выборочное среднее, 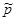 - оценка доли признака,
- оценка доли признака, 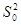 - несмещенная оценка дисперсии,
- несмещенная оценка дисперсии, 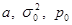 - предполагаемые значения параметров,
- предполагаемые значения параметров, 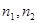 - объемы выборок,
- объемы выборок, 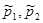 - оценки доли признака, b – предполагаемое значение разности.
- оценки доли признака, b – предполагаемое значение разности.
4 этап. В области всевозможных значений статистики К выделяют критическую область. Значения критерия, попавшие в эту подобласть, свидетельствуют о существенном расхождении выборки с гипотезой . Т.е. если вычисленное по выборке значение статистики попадает в критическую область, то основная гипотеза отвергается и принимается альтернативная . Но не следует забывать, что принятое решение может быть ошибочным – основная гипотеза верная, но принимают альтернативную. В этом случае, чтобы избежать ошибок первого и второго рода их минимизируют.
Данному требованию удовлетворяют три случая расположения критической области (в зависимости от вида нулевой и альтернативной гипотез, формы и распределения статистики).
| Вид критической области | Характерные черты | ||||||||
Правосторонняя 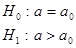 | Состоит из интервала 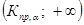  область допустимых значений () () критическая область область допустимых значений () () критическая область  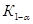 | ||||||||
Левосторонняя 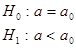 | 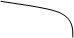 Состоит из интервала Состоит из интервала 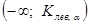  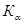 | ||||||||
Двухсторонняя 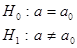 | Состоит из двух интервалов 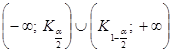
|



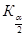
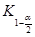
5 этап. Согласно формуле статистики, которая вычисляется в зависимости от формулировки основной гипотезы, находят числовое значение критерия 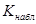 по выборочным данным.
по выборочным данным.
Если попадает в критическую область, то основную гипотезу отвергают и принимают гипотезу . Если вычисленное значение попадает в область принятия основной гипотезы, то основная гипотеза принимается, а конкурирующая отклоняется. Однако это не означает, что является единственно подходящей гипотезой: просто не противоречит результатам наблюдений, возможно, таким же свойством наряду с могут обладать и другие утверждения.
Дано: 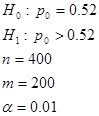 | Решение 1). Для проверки гипотезы о доле признака необходимо вычислить статистику 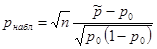 , где , где 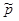 - оценка доли признака, - оценка доли признака, 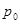 - предполагаемое значение параметра. (см. табл.). Оценка доли признака равна отношению числа благоприятных исходов - предполагаемое значение параметра. (см. табл.). Оценка доли признака равна отношению числа благоприятных исходов 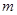 к числу всевозможных исходов . Для нашего случая получаем к числу всевозможных исходов . Для нашего случая получаем 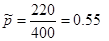 , отсюда , отсюда 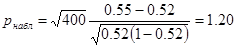 |
2). Альтернативная гипотеза правосторонняя, квантиль, определяющий границу критической области, находится из таблицы квантилей нормального стандартного распределения с вероятностью 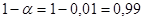 . По таблице Приложения 3 или через функцию НОРМ.СТ.ОБР Microsoft Excel находим
. По таблице Приложения 3 или через функцию НОРМ.СТ.ОБР Microsoft Excel находим 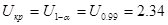
3). Сравниваем табличное значение с найденной статистикой получаем 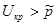 , т.е. нет оснований отклонять основную гипотезу.
, т.е. нет оснований отклонять основную гипотезу.
4). Предположение о том, что, по крайней мере, 52 % потребителей предпочтут новый сорт кофе на уровне значимости 1 % подтверждается.
10. Для данной выборки с помощью критерия Пирсона проверить гипотезу о нормальном виде распределения генеральной совокупности на уровне значимости 5 %.
| 4,36 | 2,11 | 1,95 | 1,64 | 3,67 |
| 3,77 | 5,57 | 3,93 | 1,85 | 2,98 |
| 1,78 | 3,30 | 1,53 | 4,86 | 4,63 |
| 2,17 | 1,06 | 2,81 | 3,42 | 1,97 |
| 1,40 | 1,63 | 3,50 | 3,18 | 5,50 |
| 2,88 | 5,00 | 2,47 | 5,53 | 5,72 |
| 4,49 | 2,04 | 4,11 | 3,44 | 3,20 |
| 5,15 | 1,72 | 1,53 | 3,44 | 5,44 |
| 6,00 | 1,68 | 2,62 | 4,28 | 1,68 |
| 5,47 | 3,63 | 1,52 | 4,47 | 3,69 |
Решение
1. Рассматриваемые величины относятся к непрерывному типу выборки, для ее графического представления необходимо произвести группировку данных (см. зад.4). После необходимых операций результат выглядит следующим образом
| № п/п | | | | 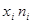 | 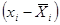 | 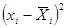 | 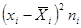 | |
| 1,06 | 1,88 | 1,47 | 17,66 | -1,82 | 3,32 | 39,82 | ||
| 1,88 | 2,70 | 2,29 | 16,04 | -1,00 | 1,00 | 7,02 | ||
| 2,70 | 3,52 | 3,11 | 31,12 | -0,18 | 0,03 | 0,33 | ||
| 3,52 | 4,34 | 3,93 | 27,52 | 0,64 | 0,41 | 2,85 | ||
| 4,34 | 5,16 | 4,75 | 33,26 | 1,46 | 2,13 | 14,89 | ||
| 5,16 | 6,00 | 5,58 | 39,06 | 2,29 | 5,23 | 36,61 | ||
| Итого | 164,66 | 101,52 |
При этом в качестве варианты берется значение медианы каждого промежутка 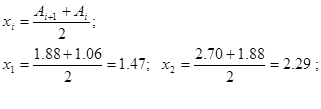 и т.д. Среднее выборочное значение получается из суммы значений 5 столбца деленной на объем выборки (итог третьей колонки)
и т.д. Среднее выборочное значение получается из суммы значений 5 столбца деленной на объем выборки (итог третьей колонки) 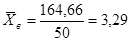 . Среднеквадратическое отклонение равно
. Среднеквадратическое отклонение равно 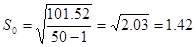 .
.
По условию задачи необходимо проверить гипотезу о нормальном распределении 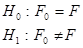 , т.е. основная гипотеза – распределения похожи, альтернативная – сходства между распределениями нет. Статистика критерия определяется по формуле
, т.е. основная гипотеза – распределения похожи, альтернативная – сходства между распределениями нет. Статистика критерия определяется по формуле 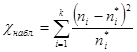 , где - наблюдаемая частота,
, где - наблюдаемая частота,
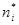 - теоретическая частота, - количество интервалов. Значение границы правосторонней критической области соответствует квантилю Хи2 распределения
- теоретическая частота, - количество интервалов. Значение границы правосторонней критической области соответствует квантилю Хи2 распределения 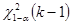 .
.


Для определения близости найдем теоретические частоты наших интервалов при нормальном распределении.
| № п/п | | | 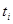 | 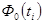 | 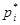 | 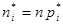 |
| 1,47 | -1,28 | 0,10 | 0,10 | |||
| 2,29 | -0,70 | 0,24 | 0,14 | |||
| 3,11 | -0,13 | 0,45 | 0,21 | |||
| 3,93 | 0,45 | 0,67 | 0,22 | |||
| 4,75 | 1,03 | 0,85 | 0,17 | |||
| 5,58 | 1,61 | 0,95 | 0,10 | |||
| Итого |
Значения 5 колонки определяется по таблице Приложения 2, где 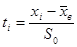 , либо с помощью функции НОРМРАСП Microsoft Excel
, либо с помощью функции НОРМРАСП Microsoft Excel
Рис.14 Аргументы функции НОРМРАСП
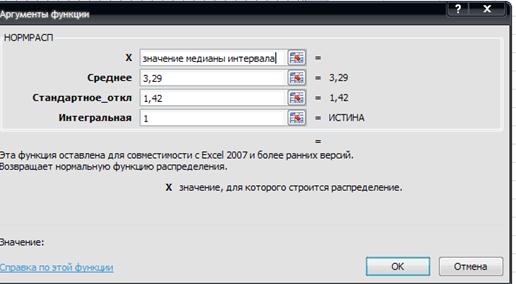
Теоретическая частота это разность последующего и предыдущего значений функции стандартного нормального распределения интервалов 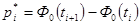 . Условие применения критерия Пирсона
. Условие применения критерия Пирсона 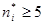 , т.е. значения теоретических частот должно быть больше либо равное 5. В противном случае, группы с меньшими частотами объединяем с соседними, до тех пор пока не получим необходимое значение, при этом не забываем о наблюдаемой частоте объединяемых интервалов. Представим в виде таблицы вычисления статистики критерия
, т.е. значения теоретических частот должно быть больше либо равное 5. В противном случае, группы с меньшими частотами объединяем с соседними, до тех пор пока не получим необходимое значение, при этом не забываем о наблюдаемой частоте объединяемых интервалов. Представим в виде таблицы вычисления статистики критерия
| № п/п | | | 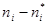 | 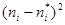 | 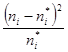 |
| 48,75 | 9,71 | ||||
| 0,00 | 0,00 | ||||
| 0,17 | 0,02 | ||||
| -4 | 17,50 | 1,57 | |||
| -2 | 2,92 | 0,34 | |||
| 4,19 | 0,85 | ||||
| Итого | 12,48 |
Итак, статистика критерия равна 12,48. Определяем значение границы критической области: число степеней свободы 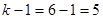 ; вероятность
; вероятность 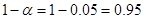 , по таблице Приложения 4 или с помощью функции ХИ2.ОБР находим его значение
, по таблице Приложения 4 или с помощью функции ХИ2.ОБР находим его значение 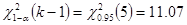 . Сравнивая данный показатель со значением статистики видим, что 11,07<12,48, следовательно, основную гипотезу о сходстве наблюдаемого распределения с нормальным на уровне значимости 5 % отклоняем.
. Сравнивая данный показатель со значением статистики видим, что 11,07<12,48, следовательно, основную гипотезу о сходстве наблюдаемого распределения с нормальным на уровне значимости 5 % отклоняем.
Примечание. Если необходимо сравнить наблюдаемое распределение с распределением Пуассона, для этого вычисляют значение параметра Пуассона 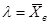 , в соответствии с ним по таблице Приложения 5 находят значение теоретической частоты для соответствующей варианты.
, в соответствии с ним по таблице Приложения 5 находят значение теоретической частоты для соответствующей варианты.
11. В результате опроса тысячи покупателей прохладительных напитков. Каждого покупателя просили выбрать из двух типов прохладительных напитков («Кока-Кола» и минеральная вода) один. Результаты опроса с разбивкой по возрастным группам были представлены в виде таблицы сопряженности.
| Покупатели | «Кока-Кола» | Минеральная вода |
| Дети | ||
| Взрослые | ||
| Пенсионеры |
Было выдвинуто следующее предположение (гипотеза): предпочтение «Кока-Колы» или минеральной воды не зависит от возраста опрашиваемого. Если бы это предположение было справедливо, то ожидаемые частоты в таблице сопряженности совпали бы с частотами, вычисленными в следующей таблице.
| Покупатели | «Кока-Кола» | Минеральная вода | Всего |
| Дети | 378*544/1 000 | 378*456/1 000 | |
| Взрослые | 297*544/1 000 | 297*456/1 000 | |
| Пенсионеры | 325*544/1 000 | 325*456/1 000 | |
| Всего | 1 000 |
Для проверки выдвинутой гипотезы рассчитывается статистика 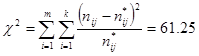 , где
, где 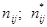 - наблюдаемые и теоретические частоты соответственно. Число степеней свободы
- наблюдаемые и теоретические частоты соответственно. Число степеней свободы 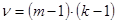 в этом случае ν = (2 – 1)(3 – 1) = 2. Тогда критическое значение при вероятности ошибки α = 0,05 в таблице Приложения 4 равно
в этом случае ν = (2 – 1)(3 – 1) = 2. Тогда критическое значение при вероятности ошибки α = 0,05 в таблице Приложения 4 равно 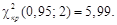 Поскольку
Поскольку 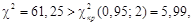 то выдвинутую гипотезу отвергаем. В этом случае можно сделать вывод о наличии зависимости между возрастом покупателя и его предпочтением к «Кока-Кола» или минеральной воде.
то выдвинутую гипотезу отвергаем. В этом случае можно сделать вывод о наличии зависимости между возрастом покупателя и его предпочтением к «Кока-Кола» или минеральной воде.
На практике очень часто приходится сталкиваться с величинами, значения которых зависит не от одной, а нескольких величин. Например, стоимость квартиры зависит не только от общей площади, но и от места расположения квартиры по линии метро, этажности, типа строения и т.д. Если статистическая зависимость проявляется в том, что изменение одной из них влечет изменение среднего значения другой, называется корреляционной. Мы рассмотрим парную корреляционную зависимость, когда учитываются две характеристики. Тесноту связи между ними определяется через коэффициент корреляции 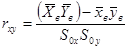 , где
, где 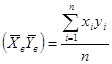 - среднее значение произведения признаков,
- среднее значение произведения признаков, 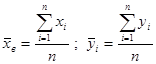 - выборочные средние каждой характеристики,
- выборочные средние каждой характеристики, 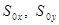 - среднеквадратичное отклонение параметра соответственно. Если
- среднеквадратичное отклонение параметра соответственно. Если 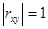 или близок к 1 (-1), то связь сильная, в противном случае слабая. При
или близок к 1 (-1), то связь сильная, в противном случае слабая. При 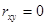 зависимость отсутствует, т.е. изменение одной из величин не влияет на изменение другой.
зависимость отсутствует, т.е. изменение одной из величин не влияет на изменение другой.
12. В таблице приведены результаты эксперимента двух случайных величин 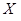 и
и 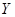
| № п/п | | 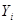 |
| 4,08 | 2,14 | |
| 6,91 | 3,00 | |
| 7,42 | 1,73 | |
| 3,58 | 4,24 | |
| 5,16 | 3,27 | |
| 5,19 | 2,83 | |
| 4,10 | 4,22 | |
| 5,37 | 4,40 | |
| 5,02 | 2,19 | |
| 6,19 | 3,20 |
Табличное представление операции вычисления коэффициента корреляции представлено в таблице
| № п/п | | | 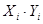 | 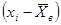 | 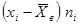 | 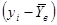 | 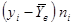 |
| 4,08 | 2,14 | 8,73 | -1,22 | 1,49 | -0,98 | 0,96 | |
| 6,91 | 3,00 | 20,73 | 1,61 | 2,59 | -0,12 | 0,01 | |
| 7,42 | 1,73 | 12,84 | 2,12 | 4,49 | -1,39 | 1,94 | |
| 3,58 | 4,24 | 15,18 | -1,72 | 2,97 | 1,12 | 1,25 | |
| 5,16 | 3,27 | 16,87 | -0,14 | 0,02 | 0,15 | 0,02 | |
| 5,19 | 2,83 | 14,69 | -0,11 | 0,01 | -0,29 | 0,09 | |
| 4,10 | 4,22 | 17,30 | -1,20 | 1,44 | 1,10 | 1,21 | |
| 5,37 | 4,40 | 23,63 | 0,07 | 0,00 | 1,28 | 1,63 | |
| 5,02 | 2,19 | 10,99 | -0,28 | 0,08 | -0,93 | 0,87 | |
| 6,19 | 3,20 | 19,81 | 0,89 | 0,79 | 0,08 | 0,01 | |
| Итого | 53,02 | 31,22 | 160,77 | 13,88 | 7,99 |
Выборочные средние равны
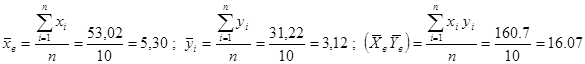 Используя формулу (3) нахом среднеквадратичное отклонение x и y
Используя формулу (3) нахом среднеквадратичное отклонение x и y 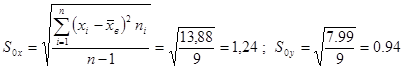 . Подставляем результат в формулу нахождения коэффициента корреляции
. Подставляем результат в формулу нахождения коэффициента корреляции 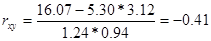 , аналогичный результат получается с использованием формулы КОРРЕЛ Microsoft Excel. Анализ полученного выборочного коэффициента корреляции позволяет судить о слабой связи между величинами. Поскольку коэффициент отрицателен, то при возрастании одного признака второй имеет тенденцию в среднем убывать.
, аналогичный результат получается с использованием формулы КОРРЕЛ Microsoft Excel. Анализ полученного выборочного коэффициента корреляции позволяет судить о слабой связи между величинами. Поскольку коэффициент отрицателен, то при возрастании одного признака второй имеет тенденцию в среднем убывать.
Зависимость между величинами описывается уравнением линейной регрессии. Уравнение позволяет прогнозировать неизвестные значения зависимой величины по линейному закону 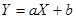 . Коэффициенты уравнения определяются с помощью метода наименьших квадратов
. Коэффициенты уравнения определяются с помощью метода наименьших квадратов
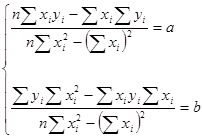 или
или 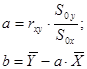
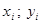 - соответствующие показания признаков, - число измерений (объем выборки). Кроме упомянутого метода наименьших квадратов коэффициенты линейной зависимости можно определить с помощью статистической функции ЛИНЕЙН пакета прикладных программ Excel. Рассмотрим построение уравнения линейной регрессии на примере.
- соответствующие показания признаков, - число измерений (объем выборки). Кроме упомянутого метода наименьших квадратов коэффициенты линейной зависимости можно определить с помощью статистической функции ЛИНЕЙН пакета прикладных программ Excel. Рассмотрим построение уравнения линейной регрессии на примере.
13. В следующей таблице представлены данные о рентах и свободных площадях для десяти городов.
| Город | ||||||||||
| Доля площадей | ||||||||||
| Месячная рента за квадратный метр (руб.) | 8,0 | 5,5 | 7,75 | 7,5 | 6,0 | 7,5 | 7,0 | 6,0 | 6,25 | 5,75 |
Построить линейное уравнение регрессии. Выполните прогноз доли свободной площади для города с месячной рентой за квадратный метр 3,50 тыс. рублей.
| № п/п | | | 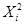 | 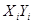 |
| 5,5 | 30,25 | |||
| 7,75 | 60,06 | 69,75 | ||
| 7,5 | 56,25 | |||
| 7,5 | 56,25 | |||
| 6,25 | 39,06 | 68,75 | ||
| 5,75 | 33,06 | |||
| Итого | 619,5 |
По данным таблицы коэффициенты равны 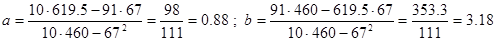
И так уравнение линейной регрессии имеет вид 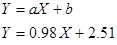 . Чтобы спрогнозировать долю свободной площади для города с месячной рентой за квадратный метр 3,50 тыс. рублей, достаточно в линейную зависимость подставить
. Чтобы спрогнозировать долю свободной площади для города с месячной рентой за квадратный метр 3,50 тыс. рублей, достаточно в линейную зависимость подставить 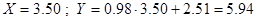 . В случае, если месячная рента будет равна 3,50 тыс. рублей, то доля свободных площадей будет составлять 5,94 метра квадратных.
. В случае, если месячная рента будет равна 3,50 тыс. рублей, то доля свободных площадей будет составлять 5,94 метра квадратных.
В случае если используем функцию ЛИНЕЙН пакета прикладных программ Excel. Выделяем две соседние ячейки в строке, вставляем функцию ЛИНЕЙН, где КОНСТАНТА и СТАТИСТИКА равны по 1. В соответствии с правилом работы с массивами нажимает Ctrl+Shift+Enter, в первой ячейке отобразится параметр a, во второй b. Графическое представление зависимости определяется точечным графиком, после его построения активируют точки и правой кнопкой мыши выбирают в контекстном меню Добавить линию тренда.
Рис.15 Добавление линии тренда
В качестве Формата линии тренда указываем Линейчатая и включаем условие показывать уравнение на диаграмме.
Рис. 16 Параметры линии тренда

