 2015-05-18
2015-05-18 4026
4026Итак, при исследовании остатков ei должно проверяться наличие следующих пяти предпосылок МНК:
1) случайный характер остатков;
2) нулевая средняя величина остатков, не зависящая от х i;
3) гомоскедастичность – дисперсия каждого отклонения ei одинакова для всех значений х i;
4) отсутствие автокорреляции остатков – значения остатков ei распределены независимо друг от друга;
5) остатки подчиняются нормальному распределению.
Если распределение случайных остатков ei не соответствует некоторым предпосылкам МНК, то следует корректировать модель.
В случае нарушения первых двух предпосылок необходимо либо применять другую функцию, либо вводить дополнительную информацию и заново строить уравнение регрессии.
Пятая предпосылка о нормальном распределении остатков позволяет проводить проверку параметров регрессии и корреляции с помощью критериев t, F. Однако и при нарушении пятой предпосылки МНК оценки регрессии обладают достаточной состоятельностью.
Совершенно необходимым для получения по МНК состоятельных оценок параметров регрессии является соблюдение третьей и четвертой предпосылок.
Если не соблюдается гомоскедастичность, то имеет место гетероскедастичность. Наличие гетероскедастичности может привести к смещенности оценок коэффициентов регрессии, а также к уменьшению их эффективности. Вследствие вышесказанного все выводы, получаемые на основе соответствующих t- и F-статистик, а также интервальные оценки будут ненадежными. Следовательно, статистические выводы, получаемые при стандартных проверках качества оценок, могут быть ошибочными и приводить к неверным заключениям по построенной модели. Вполне вероятно, что стандартные ошибки коэффициентов будут занижены, а следовательно, t-статистики будут завышены. Это может привести к признанию статистически значимыми коэффициентов, таковыми на самом деле не являющихся. В этом случае рекомендуется применять обобщенный метод наименьших квадратов, который заключается в том, что при минимизации суммы квадратов отклонений (5) отдельные ее слагаемые взвешиваются: наблюдениям с большей дисперсией придается пропорционально меньший вес. Чтобы убедиться в гетероскедастичности остатков и, следовательно, в необходимости использования обобщенного МНК, обычно не ограничиваются визуальной проверкой гетероскедастичности, а проводят ее эмпирическое подтверждение, в частности, используют метод Гольдфельда – Квандта. Проиллюстрируем его на примере (табл.5.3).
Поступления налогов в бюджет (y i – млн.руб.) в зависимости
от численности работающих (х i – тыс.чел). Таблица 5.3
| № п/п | х i | y i | ŷ х | ei |
| 4,4 | -1,0 | 5,4 | ||
| 8,1 | 2,5 | 5,6 | ||
| 12,9 | 4,9 | 8,0 | ||
| 20,8 | 16,6 | 4,2 | ||
| 15,5 | 19,0 | -3,5 | ||
| 28,8 | 22,5 | 6,3 | ||
| 37,5 | 41,4 | -3,9 | ||
| 48,7 | 53,2 | -4,5 | ||
| 68,6 | 66,1 | 2,5 | ||
| 104,6 | 82,6 | 22,0 | ||
| 90,5 | 88,5 | 2,0 | ||
| 88,3 | 107,4 | -19,1 | ||
| 132,4 | 120,4 | 12,0 | ||
| 122,0 | 127,4 | -5,4 | ||
| 99,1 | 131,0 | -31,9 | ||
| 114,2 | 142,7 | -28,5 | ||
| 150,6 | 151,0 | -0,4 | ||
| 156,1 | 171,0 | -14,9 | ||
| 209,5 | 180,5 | 29,0 | ||
| 342,9 | 327,8 | 15,1 | ||
| итого | 1855,5 | 1855,5 | 0,0 |
По выборочным данным строим уравнение регрессии
ŷх = – 4,565 + 1,178 х.
Теоретические значения ŷх и отклонения от них фактических значений ei приведены в четвертой и пятой колонке табл.5.3. Очевидно, что остаточные величины ei обнаруживают тенденцию к росту по мере увеличения х и у. Этот вывод подтверждается и по критерию Гольдфельда – Квандта. Для его применения необходимо выполнить следующие шаги:
- упорядочить n наблюдений по мере возрастания переменной х (выполнено);
- исключить из рассмотрения k центральных наблюдений (рекомендовано при n=60 принимать k=16, при n=30 принимать k=8, при n=20 принимать k=4), в данном случае исключаем строки 9–12;
- разделить совокупность на две группы (по ń=(n – k):2=8 наблюдений соответственно с малыми и большими значениями фактора х) и определить по каждой из групп уравнения регрессии (результаты в табл.5.4.);
- определить остаточные суммы квадратов для первой (S1) и второй (S2) групп и найти их отношение R=S2:S1. Чем больше величина R превышает табличное значение F–критерия с ń –2 степенями свободы (приложение 2), тем более нарушена предпосылка о равенстве дисперсий остаточных величин, т.е. наблюдается гетероскедастичность остатков.
Таблица 5.4.
| № п/п | х i | y i | ŷх | ei | ei2 |
| 4,4 | 5,7 | –1,3 | 1,69 | ||
| 8,1 | 8,5 | –0,4 | 0,16 | ||
| 12,9 | 10,3 | 2,6 | 6,76 | ||
| 20,8 | 19,6 | 1,2 | 1,44 | ||
| 15,5 | 21,4 | –5,9 | 34,81 | ||
| 28,8 | 24,2 | 4,6 | 21,16 | ||
| 37,5 | 38,9 | –1,4 | 1,96 | ||
| 48,7 | 48,1 | 0,6 | 0,36 | ||
| Уравнение регрессии: ŷх = 2,978 + 0,921 х. Сумма S1=68,34 | |||||
| 132,4 | 110,7 | 21,7 | 470,89 | ||
| 122,0 | 118,7 | 3,3 | 10,89 | ||
| 99,1 | 122,7 | –23,6 | 556,96 | ||
| 114,2 | 136,1 | –21,9 | 479,61 | ||
| 150,6 | 145,4 | 5,2 | 27,04 | ||
| 156,1 | 168,2 | –12,1 | 146,41 | ||
| 209,5 | 178,9 | 30,6 | 936,36 | ||
| 342,9 | 346,1 | –3,2 | 10,24 | ||
| Уравнение регрессии: ŷх = 31,142 + 1,338 х. Сумма S2 =2638,4 |
Величина R=2638,4: 68,34=38.6 существенно превышает табличное значение F-критерия 4,28 при 5%-ном и 8,47 при 1%-ном уровне значимости для числа степеней свободы 8 – 2 = 6, подтверждая тем самым наличие гетероскедастичности.
Нарушение четвертой предпосылки МНК – автокорреляция остатков означает наличие корреляции между остатками текущих и предыдущих (последующих) наблюдений. Среди основных причин, вызывающих появление автокорреляции, можно выделить ошибки спецификации, инерцию в изменении экономических показателей, эффект паутины, сглаживание данных.
Ошибки спецификации. Неучет в модели какой-либо важной объясняющей переменной либо неправильный выбор формы зависимости обычно приводит к системным отклонениям точек наблюдений от линии регрессии, что может обусловить автокорреляцию.
Инерция. Многие экономические показатели (например, инфляция, безработица, ВНП и т.п.) обладают определенной цикличностью, связанной с волнообразностью деловой активности. Действительно, экономический подъем приводит к росту занятости, сокращению инфляции, увеличению ВНП и т.д. Этот рост продолжается до тех пор, пока изменение конъюнктуры рынка и ряда экономических характеристик не приведет к замедлению роста, затем остановке и движению вспять рассматриваемых показателей. В любом случае эта трансформация происходит не мгновенно, а обладает определенной инертностью.
Эффект паутины. Во многих производственных и других сферах экономические показатели реагируют на изменение экономических условий с запаздыванием (временным лагом). Например, предложение сельскохозяйственной продукции реагирует на изменение цены с запаздыванием (равным периоду созревания урожая). Большая цена сельскохозяйственной продукции в прошедшем году вызовет (скорее всего) ее перепроизводство в текущем году, а следовательно, цена на нее снизится и т.д.
Сглаживание данных. Зачастую данные по некоторому продолжительному временному периоду получают усреднением данных по составляющим его подинтервалам. Это может привести к определенному сглаживанию колебаний, которые имелись внутри рассматриваемого периода, что в свою очередь может послужить причиной автокорреляции.
Последствия автокорреляции во многом сходны с последствиями гетероскедастичности. Среди них при применении МНК обычно выделяются следующие.
1. Оценки параметров, оставаясь линейными и несмещенными, перестают быть эффективными. Следовательно, они перестают обладать свойствами наилучших линейных несмещенных оценок.
2. Дисперсии оценок являются смешенными. Часто дисперсии, вычисленные по стандартным формулам, являются заниженными, что влечет за собой увеличение t-статистик. Это может привести к признанию статистически значимыми объясняющие переменные, которые в действительности таковыми могут не являться.
3. Оценка дисперсии регрессии является смещенной оценкой истинного значения дисперсии, во многих случаях занижая его.
В силу вышесказанного выводы по t- и F-статистикам, определяющим значимость коэффициентов регрессии и коэффициента детерминации, возможно, будут неверными. Вследствие этого ухудшаются прогнозные качества модели.
Для обнаружения автокорреляции необходимо наблюдения упорядочить по значению фактора х (как в предыдущем примере) и составить ряды с текущими и предыдущими остатками. Коэффициент корреляции reiej между ei и ej, где ei – остатки текущих наблюдений, ej – остатки предыдущих наблюдений (например, j=i–1) определяется по обычной формуле линейного коэффициента корреляции (2.1).Рассмотрим расчет коэффициента корреляции между ei и ej, взяв в качестве примера данные из табл.5.3 и перенеся их в табл. 5.5 (n=19).
Таблица 5.5.
| № п/п | ei | ei-1 | eiei-1 |
| 5,6 | 5,4 | 30.24 | |
| 8,0 | 5,6 | 44.8 | |
| 4,2 | 8,0 | 33.6 | |
| –3,5 | 4,2 | –14.7 | |
| 6,3 | –3,5 | –22.05 | |
| –3,9 | 6,3 | –24.57 | |
| –4,5 | –3,9 | 17.55 | |
| 2,5 | –4,5 | –11.25 | |
| 22,0 | 2,5 | ||
| 2,0 | 22,0 | ||
| –19,1 | 2,0 | –38.2 | |
| 12,0 | –19,1 | –229.2 | |
| –5,4 | 12,0 | –64.8 | |
| –31,9 | –5,4 | 172.26 | |
| –28,5 | –31,9 | 909.15 | |
| –0,4 | –28,5 | 11.4 | |
| –14,9 | –0,4 | 5.96 | |
| 29,0 | –14,9 | –432.1 | |
| 15,1 | 29,0 | ||
| итого | –5.3998 | –15.1031 | 922.09 |
| среднее | –0,2842 | –0,7949 | 48.5311 |
σei =15.1347, σej =14,7663 и в соответствие с (2.1)
reiej =(48,5311 – (–0,2842)(–0,7949))/15,1347/14,7663=0,2161,
что при 17 степенях свободы явно незначимо и демонстрирует отсутствие автокорреляции остатков.
Автокорреляция остатков может быть вызвана несколькими причинами, имеющими различную природу. Во-первых, иногда она связана с исходными данными и вызвана наличием ошибок измерения в значениях результативного признака. Во-вторых, причину следует искать в формулировке модели, которая может не включать существенный фактор, влияние которого отражается в остатках, вследствие чего они оказываются автокоррелированными. Очень часто этим фактором является фактор времени, поэтому проблема автокорреляции остатков весьма актуальна при исследовании динамических рядов, что мы рассмотрим в соответствующем разделе.
5.6. Обобщенный метод наименьших квадратов. Метод Главных Компонент.
При нарушении гомоскедастичности и наличии автокорреляции ошибок рекомендуется традиционный метод наименьших квадратов (метод OLD – Ordinary Least Squares) заменять обобщенным методом GLS(Generalized Least Squares). Он применяется к преобразованным данным и позволяет получать оценки, которые обладают не только свойством несмещенности, но и имеют меньшие выборочные дисперсии.
Суть метода заключается в том, что подбираются коэффициенты Кi, такие, что σ2ei =σ2 ·Кi,
где σ2ei – дисперсия ошибки при конкретном i–ом значении фактора;
σ2 – постоянная дисперсия ошибки при соблюдении предпосылки о гомоскедастичности остатков;
Кi – коэффициент пропорциональности, меняющийся с изменением величины фактора.
Уравнение парной регрессии при этом принимает вид
у i/ 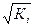 = a0/ + a1 х i/ +ei.
= a0/ + a1 х i/ +ei.
По отношению к обычной регрессии уравнение с новыми, преобразованными переменными представляют собой взвешенную регрессию, в которой переменные у и х взяты с весами 1/ . Аналогичный подход применяют и для множественной регрессии, уравнение с преобразованными переменными принимает вид
у / =a0/ +a1 х 1/ +a2 х 2/ +…+am х m/ +e. (5.1)
Параметры такой модели зависят от концепции, принятой для коэффициента пропорциональности К. В эконометрических исследованиях довольно часто выдвигается гипотеза, что остатки ei пропорциональны значениям фактора. Пусть, например, у – издержки производства, х 1 – объем продукции, х 2 – основные производственные фонды, х 3 – численность работников, тогда уравнение у =a0 +a1 х 1 +a2 х 2 + a3 х 3 +e является моделью издержек производства с объемными факторами. Предполагая, что σ2ei пропорциональна квадрату численности работников (т.е. 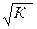 = х 3), получим в качестве результативного признака затраты на одного работника (у / х 3), а в качестве факторов производительность труда (х 1/ х 3) и фондовооруженность труда (х 2/ х 3). Соответственно трансформированная модель примет вид
= х 3), получим в качестве результативного признака затраты на одного работника (у / х 3), а в качестве факторов производительность труда (х 1/ х 3) и фондовооруженность труда (х 2/ х 3). Соответственно трансформированная модель примет вид
у / х 3 =a3 +a1 х 1/ х 3 +a2 х 2/ х 3 +e,
где вычисленные параметры a3, a1, a2 численно не совпадают с аналогичными параметрами предыдущей модели. Кроме того, коэффициенты регрессии меняют экономическое содержание: из показателей силы связи, характеризующих среднее изменение издержек производства с изменением абсолютного значения соответствующего фактора на единицу, они фиксируют теперь среднее изменение затрат на работника в зависимости от изменения производительности труда на единицу; и в зависимости от изменения фондовооруженности труда на единицу.
Если же предположить, что в первоначальной модели дисперсия остатков пропорциональна квадрату объема продукции, получаем уравнение регрессии
у / х 1 =a1 +a2 х 2/ х 1 +a3 х 3/ х 1 +e,
где у / х 1 – затраты на единицу продукции, х 2/ х 1 – фондоемкость продукции, х 3/ х 1 – трудоемкость продукции.
Переход к относительным величинам существенно снижает вариацию фактора и соответственно уменьшает дисперсию ошибки.
Метод Главных Компонент (Principal Components Analysis, PCA) – один из основных способов уменьшить размерность данных, потеряв наименьшее количество информации. Изобретен К. Пирсоном в 1901 г. Он применяется для:
1) наглядного представления данных;
2) обеспечения лаконизма моделей, упрощения счета и интерпретации;
3) сжатия объемов хранимой информации.
Метод обеспечивает максимальную информативность и минимальное искажение геометрической структуры исходных данных. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных. Иногда метод главных компонент называют преобразованием Кархунена-Лоэва или преобразованием Хотеллинга. Другие способы уменьшения размерности данных – это метод независимых компонент, многомерное шкалирование, а также многочисленные нелинейные обобщения: метод главных кривых и многообразий, поиск наилучшей проекции, нейросетевые методы «узкого горла», самоорганизующиеся карты Кохонена и др.
Задача анализа главных компонент, имеет, как минимум, четыре базовых версии:
- аппроксимировать данные линейными многообразиями меньшей размерности;
- найти подпространства меньшей размерности, в ортогональной проекции на которые разброс данных (т.е. среднеквадратичное уклонение от среднего значения) максимален;
- найти подпространства меньшей размерности, в ортогональной проекции на которые среднеквадратичное расстояние между точками максимально;
- для данной многомерной случайной величины построить такое ортогональное преобразование координат, что в результате корреляции между отдельными координатами обратятся в ноль. Подробнее о методе главных компонент см. [9,10].
5.7.Прогнозирование. Доверительный интервал прогноза.
Расчеты и проверка достоверности полученных оценок коэффициентов регрессии не являются самоцелью, это лишь необходимый промежуточный этап. Основное – это использование модели для анализа и прогноза поведения изучаемого экономического явления. Прогноз осуществляется подстановкой значения фактора х в полученную формулу регрессии.
Используем полученное в примере 2.1 уравнение регрессии для прогноза объема товарооборота. Пусть намечается открытие магазина с численностью работников х =140 чел., тогда достаточно обоснованный объем товарооборота следует установить по уравнению ŷ (х)= –0,974 + 0,01924×140=1,72 млрд. руб.
Доверительный интервал для прогностического значения у (х)= a0+a1 х определяется по формуле
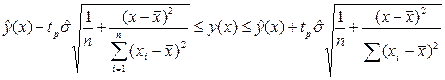 , (5.2)
, (5.2)
где tp – критическая граница распределения Стьюдента с n – 2 степенями свободы, соответствующая уровню значимости р. Для получения доверительного интервала воспользуемся выражением (5.2).
Выберем уровень значимости 5%. Число степеней свободы у нас 8 – 2 = 6, тогда по таблице распределения Стьюдента (приложение 1) находим 
t0.05(6)=2,447. s=Ö 0,008=0,089,
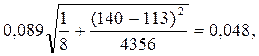
следовательно, с вероятностью 95% истинные значения объемов товарооборота будут лежать в пределах
1,72 – 2,447×0,048< y (x)<1,72+2,447×0,048, или 1,60< y (x)<1,84.
5.8. Практический блок
Пример. Построить модель связи между указанными факторами, проверить её адекватность, осуществить точечный и интервальный прогноз методом экстраполяции.
1. Построить диаграмму рассеяния в EXCEL и сделать предварительное заключение о наличии связи.
Таблица 5.6 Диаграмма 5.1
| x | Y |
| 2,1 | 29,5 |
| 2,9 | 34,2 |
| 3,3 | 30,6 |
| 3,8 | 35,2 |
| 4,2 | 40,7 |
| 3,9 | 44,5 |
| 5,0 | 47,2 |
| 4,9 | 55,2 |
| 6,3 | 51,8 |
| 5,8 | 56,7 |
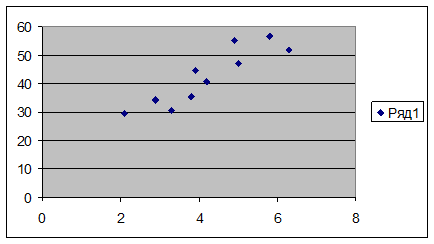
Вывод: Из диаграммы 5.1 видно, что связь между факторами x и y
прямая сильная линейная связь.
2. Рассчитайте линейный коэффициент корреляции. Используя t-критерий Стьюдента, проверьте значимость коэффициента корреляции. Сделайте вывод о тесноте связи между факторами х и у.
Таблица 5.7
| № | 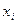 | 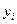 | 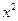 | 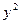 | xy | 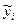 | 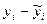 | 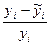 |
| 2,1 | 29,5 | 4,41 | 870,25 | 61,95 | 27,91 | 1,59 | 0,054 | |
| 2,9 | 34,2 | 8,41 | 1169,64 | 99,18 | 33,46 | 0,74 | 0,022 | |
| 3,3 | 30,6 | 10,89 | 936,36 | 100,98 | 36,23 | -5,63 | 0,184 | |
| 3,8 | 35,2 | 14,44 | 1239,04 | 133,76 | 39,69 | -4,49 | 0,128 | |
| 4,2 | 40,7 | 17,64 | 1656,49 | 170,94 | 42,47 | -1,77 | 0,043 | |
| 3,9 | 44,5 | 15,21 | 1980,25 | 173,55 | 40,39 | 4,11 | 0,092 | |
| 5,0 | 47,2 | 2227,84 | 48,01 | -0,81 | 0,017 | |||
| 4,9 | 55,2 | 24,01 | 3047,04 | 270,48 | 47,32 | 7,88 | 0,143 | |
| 6,3 | 51,8 | 39,69 | 2683,24 | 326,34 | 57,02 | -5,22 | 0,101 | |
| 5,8 | 56,7 | 33,64 | 3214,89 | 328,86 | 53,55 | 3,15 | 0,056 | |
| ИТОГО: | 42,2 | 193,34 | 19025,04 | 1902,04 | 0,840 | |||
| Среднее зн. | 4,22 | 42,56 | 19,334 | 1902,504 | 190,204 |
2.1.Проверим тесноту связи между факторами:
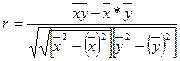 ;
; 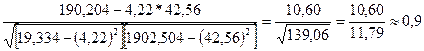
Вывод: связь сильная.
2.2.Проверим статистическую значимость по критерию Стьюдента:
1)Критерий Стьюдента: tвыб<=tкр
2)Но: r=0 tкр=2,31
tвыб=rвыб* 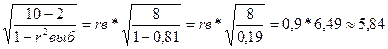
Вывод: таким образом поскольку tвыб=5,84<tкр=2,31, то с доверительной вероятностью
90% нулевая гипотеза отвергается, это указывает на наличие сильной линейной связи.
3. Полагая, что связь между факторами х и у может быть описана линейной функцией, используя процедуру метода наименьших квадратов, запишите систему нормальных уравнений относительно коэффициентов линейного уравнения регрессии. Любым способом рассчитайте эти коэффициенты.
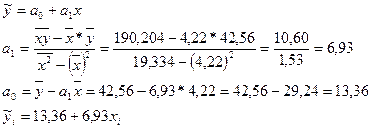
Последовательно подставляя в уравнение регрессии из графы (2) табл.5.7, рассчитаем значения и заполним графу (7) табл.5.7.
4. Для полученной модели связи между факторами Х и У рассчитайте среднюю ошибку аппроксимации. Сделайте предварительное заключение приемлемости полученной модели.
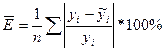
Для расчета заполним 8-ую и 9-ую графу табл.5.7.
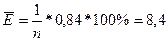 <Екр=12%
<Екр=12%
Вывод: модель следует признать удовлетворительной.
5. Проверьте значимость коэффициента уравнения регрессии a1 на основе t-критерия Стьюдента.
Решение: Таблица 5.8
| № |  |  | 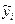 | 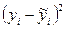 | 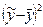 | 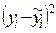 |
| 2,1 | 29,5 | 27,91 | 2,5281 | 214,623 | 170,5636 | |
| 2,9 | 34,2 | 33,46 | 0,5476 | 82,81 | 69,8896 | |
| 3,3 | 30,6 | 36,23 | 31,6969 | 40,069 | 143,0416 | |
| 3,8 | 35,2 | 39,69 | 20,1601 | 8,237 | 54,1696 | |
| 4,2 | 40,7 | 42,47 | 3,1329 | 0,008 | 3,4596 | |
| 3,9 | 44,5 | 40,39 | 16,8921 | 4,709 | 3,7636 | |
| 47,2 | 48,01 | 0,6561 | 29,703 | 21,5296 | ||
| 4,9 | 55,2 | 47,32 | 62,0944 | 22,658 | 159,7696 | |
| 6,3 | 51,8 | 57,02 | 27,2484 | 209,092 | 85,3776 | |
| 5,8 | 56,7 | 53,55 | 9,9225 | 120,78 | 199,9396 | |
| ИТОГО: | 42,2 | 425,6 | 426,1 | 174,8791 | 732,687 | 911,504 |
| Среднее | 4,22 | 42,56 |
Статистическая проверка:
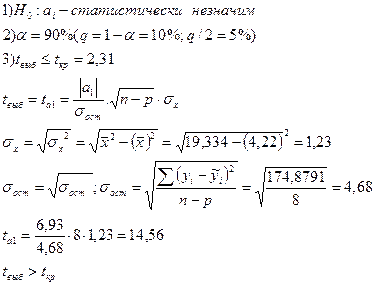
 Вывод: С доверительной вероятностью 90% коэффициент a 1- статистически значим, т.е. нулевая гипотеза отвергается.
Вывод: С доверительной вероятностью 90% коэффициент a 1- статистически значим, т.е. нулевая гипотеза отвергается.
6. Проверьте адекватность модели (уравнения регрессии) в целом на основе F-критерия Фишера-Снедекора.
Решение:
Процедура статистической проверки:
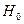 :модель не адекватна
:модель не адекватна
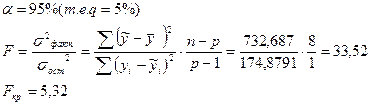
Вывод: т.к. Fвыб.>Fкр., то с доверительной вероятностью 95% нулевая гипотеза отвергается (т.е. принимается альтернативная). Изучаемая модель адекватна и может быть использована для прогнозирования и принятия управленческих решений.
7. Рассчитайте эмпирический коэффициент детерминации.
Решение:
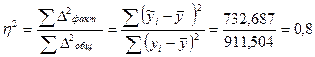 (таб. 3)
(таб. 3)
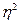 -показывает долю вариации.
-показывает долю вариации.
Вывод: т.е. 80% вариации объясняется фактором, включенным в модель, а 20% не включенными в модель факторами.
8. Рассчитайте корреляционное отношение. Сравните полученное значение с величиной линейного коэффициента корреляции.
Решение:
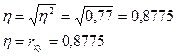
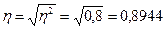
Эмпирическое корреляционное отношение указывает на тесноту связи между двумя факторами для любой связи, если связь линейная, то 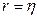 , т.е. коэффициент корреляции совпадает с коэффициентом детерминации.
, т.е. коэффициент корреляции совпадает с коэффициентом детерминации.
9. Выполните точечный прогноз для 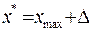 .
.
Решение:
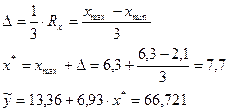
10-12. Рассчитайте доверительные интервалы для уравнения регрессии и для результирующего признака 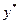 при доверительной вероятности
при доверительной вероятности 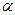 =90%. Изобразите в одной системе координат:
=90%. Изобразите в одной системе координат:
а) исходные данные,
б) линию регрессии,
в) точечный прогноз,
г) 90% доверительные интервалы.
Сформулируйте общий вывод относительно полученной модели.
Решение:
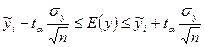 -математическое ожидание среднего.
-математическое ожидание среднего.
Для выполнения интервального прогноза рассматриваем две области.
1) для y из области изменения фактора x доверительные границы для линейного уравнения регрессии рассчитывается по формуле:
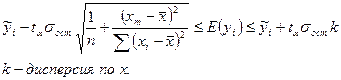
2) для прогнозного значения 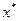 доверительный интервал для рассчитывается по формуле:
доверительный интервал для рассчитывается по формуле:
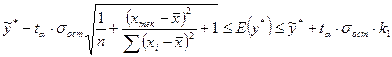
Исходные данные:
1) n=10
2) t=2,31(таб.)
3) 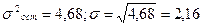
4) 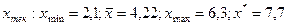
5) : 27,91 42,56 57,02 66,72
6) 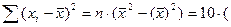 19,334-4,222)=1,53.
19,334-4,222)=1,53.
Таблица 5.9
| № | 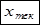 | 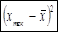 | 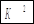 | 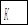 | 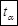 | 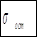 | 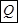 | 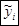 | 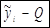 | 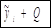 | |
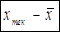 1 1 | 2,1 | -2,12 | 4,49 | 3,03 | 1,74 | 2,31 | 4,68 | 18,81 | 27,91 | 9,10 | 46,72 |
| 4,22 | 0,00 | 0,00 | 0,1 | 0,32 | 2,31 | 4,68 | 3,46 | 42,56 | 39,10 | 46,02 | |
| 6,3 | 2,08 | 4,33 | 2,93 | 1,71 | 2,31 | 4,68 | 18,49 | 57,02 | 38,53 | 75,51 | |
| 7,7 | 3,48 | 12,11 | 9,02 | 2,31 | 4,68 | 32,43 | 66,72 | 34,29 | 99,15 |
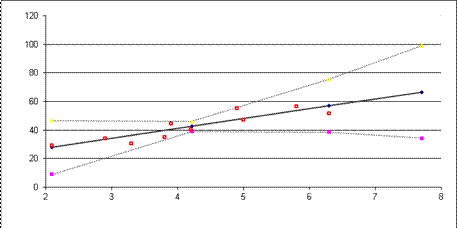
Вывод: поскольку 90% точек наблюдения попало в 90% доверительный интервал, данная модель и ее доверительные границы могут использоваться для прогнозирования с 90% доверительной вероятностью.
Контрольные вопросы
1. Линейные регрессионные модели с гетероскедастичными и автокоррелированными остатками.
2. Виды автокорреляции и их краткая характеристика.
3. Автокорреляция в остатках и порядок её обнаружения.
4. Виды автокорреляции в остатках.
5. Порядок использования критерия Дарбина-Уотсона.
6. Автокорреляция в исходных данных и порядок определения её наличия.
7. Методы устранения влияния автокорреляции на результаты прогнозирования.
8. Обобщенный метод наименьших квадратов (ОМНК).
9. Что понимается под гомоскедастичностью?
10. Как проверяется гипотеза о гомоскедастичности ряда остатков?
11. Оценка качества регрессии. Проверка адекватности и достоверности модели.
12. Значимость коэффициентов регрессии (критерий Стъюдента).
13. Дисперсионный анализ. Проверка достоверности модели связи (по F-критерию Фишера).
14. Коэффициенты и индексы корреляции. Мультиколлениарность.
15. Оценка значимости корреляции. Детерминация.
16. Средняя ошибка аппроксимации.
17. Принятие решений на основе уравнений регрессии.
18. В каких задачах эконометрики используется распределение Фишера?
19. Таблицы каких распределений используются при оценке качества линейной регрессии?
20. Каковы особенности практического применения регрессионных моделей?
21. Как осуществляется прогнозирование экономических показателей с использованием моделей линейной регрессии?
22. Как можно оценить «естественный» уровень безработицы с использованием модели линейной регрессии?
23. В каких случаях необходимо уточнение линейной регрессионной модели и как оно осуществляется?
24. Когда необходимо выведение из рассмотрения незначимых объясняющих переменных и добавление новых переменных?

